This is the multi-page printable view of this section. Click here to print.
Core Components
- 1: Crier
- 2: Deck
- 2.1: How to setup GitHub Oauth
- 2.2: CSRF attacks
- 3: Hook
- 4: Horologium
- 5: Prow-Controller-Manager
- 6: Sinker
- 7: Tide
- 7.1: Configuring Tide
- 7.2: Maintainer's Guide to Tide
- 7.3: PR Author's Guide to Tide
1 - Crier
Crier reports your prowjobs on their status changes.
Usage / How to enable existing available reporters
For any reporter you want to use, you need to mount your prow configs and specify --config-path and job-config-path
flag as most of other prow controllers do.
Gerrit reporter
You can enable gerrit reporter in crier by specifying --gerrit-workers=n flag.
Similar to the gerrit adapter, you’ll need to specify --gerrit-projects for
your gerrit projects, and also --cookiefile for the gerrit auth token (leave it unset for anonymous).
Gerrit reporter will send an aggregated summary message, when all gerrit adapter scheduled prowjobs with the same report label finish on a revision. It will also attach a report url so people can find logs of the job.
The reporter will also cast a +1/-1 vote on the prow.k8s.io/gerrit-report-label label of your prowjob,
or by default it will vote on CodeReview label. Where +1 means all jobs on the patshset pass and -1
means one or more jobs failed on the patchset.
Pubsub reporter
You can enable pubsub reporter in crier by specifying --pubsub-workers=n flag.
You need to specify following labels in order for pubsub reporter to report your prowjob:
| Label | Description |
|---|---|
"prow.k8s.io/pubsub.project" |
Your gcp project where pubsub channel lives |
"prow.k8s.io/pubsub.topic" |
The topic of your pubsub message |
"prow.k8s.io/pubsub.runID" |
A user assigned job id. It’s tied to the prowjob, serves as a name tag and help user to differentiate results in multiple pubsub messages |
The service account used by crier will need to have pubsub.topics.publish permission in the project where pubsub channel lives, e.g. by assigning the roles/pubsub.publisher IAM role
Pubsub reporter will report whenever prowjob has a state transition.
You can check the reported result by list the pubsub topic.
GitHub reporter
You can enable github reporter in crier by specifying --github-workers=N flag (N>0).
You also need to mount a github oauth token by specifying --github-token-path flag, which defaults to /etc/github/oauth.
If you have a ghproxy deployed, also remember to point --github-endpoint to your ghproxy to avoid token throttle.
The actual report logic is in the github report library for your reference.
Slack reporter
NOTE: if enabling the slack reporter for the first time, Crier will message to the Slack channel for all ProwJobs matching the configured filtering criteria.
You can enable the Slack reporter in crier by specifying the --slack-workers=n and --slack-token-file=path-to-tokenfile flags.
The --slack-token-file flag takes a path to a file containing a Slack OAuth Access Token.
The OAuth Access Token can be obtained as follows:
- Navigate to: https://api.slack.com/apps.
- Click Create New App.
- Provide an App Name (e.g. Prow Slack Reporter) and Development Slack Workspace (e.g. Kubernetes).
- Click Permissions.
- Add the
chat:write.publicscope using the Scopes / Bot Token Scopes dropdown and Save Changes. - Click Install App to Workspace
- Click Allow to authorize the Oauth scopes.
- Copy the OAuth Access Token.
Once the access token is obtained, you can create a secret in the cluster using that value:
kubectl create secret generic slack-token --from-literal=token=< access token >
Furthermore, to make this token available to Crier, mount the slack-token secret using a volume and set the --slack-token-file flag in the deployment spec.
apiVersion: apps/v1
kind: Deployment
metadata:
name: crier
labels:
app: crier
spec:
selector:
matchLabels:
app: crier
template:
metadata:
labels:
app: crier
spec:
containers:
- name: crier
image: gcr.io/k8s-prow/crier:v20200205-656133e91
args:
- --slack-workers=1
- --slack-token-file=/etc/slack/token
- --config-path=/etc/config/config.yaml
- --dry-run=false
volumeMounts:
- mountPath: /etc/config
name: config
readOnly: true
- name: slack
mountPath: /etc/slack
readOnly: true
volumes:
- name: slack
secret:
secretName: slack-token
- name: config
configMap:
name: config
Additionally, in order for it to work with Prow you must add the following to your config.yaml:
NOTE:
slack_reporter_configsis a map oforg,org/repo, or*(i.e. catch-all wildcard) to a set of slack reporter configs.
slack_reporter_configs:
# Wildcard (i.e. catch-all) slack config
"*":
# default: None
job_types_to_report:
- presubmit
- postsubmit
# default: None
job_states_to_report:
- failure
- error
# required
channel: my-slack-channel
# The template shown below is the default
report_template: "Job {{.Spec.Job}} of type {{.Spec.Type}} ended with state {{.Status.State}}. <{{.Status.URL}}|View logs>"
# "org/repo" slack config
istio/proxy:
job_types_to_report:
- presubmit
job_states_to_report:
- error
channel: istio-proxy-channel
# "org" slack config
istio:
job_types_to_report:
- periodic
job_states_to_report:
- failure
channel: istio-channel
The channel, job_states_to_report and report_template can be overridden at the ProwJob level via the reporter_config.slack field:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
channel: 'override-channel-name'
job_states_to_report:
- success
report_template: "Overridden template for job {{.Spec.Job}}"
spec:
containers:
- image: alpine
command:
- echo
To silence notifications at the ProwJob level you can pass an empty slice to reporter_config.slack.job_states_to_report:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
job_states_to_report: []
spec:
containers:
- image: alpine
command:
- echo
Implementation details
Crier supports multiple reporters, each reporter will become a crier controller. Controllers
will get prowjob change notifications from a shared informer, and you can specify --num-workers to change parallelism.
If you are interested in how client-go works under the hood, the details are explained in this doc
Adding a new reporter
Each crier controller takes in a reporter.
Each reporter will implement the following interface:
type reportClient interface {
Report(pj *v1.ProwJob) error
GetName() string
ShouldReport(pj *v1.ProwJob) bool
}
GetName will return the name of your reporter, the name will be used as a key when we store previous
reported state for each prowjob.
ShouldReport will return if a prowjob should be handled by current reporter.
Report is the actual report logic happens. Return nil means report is successful, and the reported
state will be saved in the prowjob. Return an actual error if report fails, crier will re-add the prowjob
key to the shared cache and retry up to 5 times.
You can add a reporter that implements the above interface, and add a flag to turn it on/off in crier.
Migration from plank for github report
Both plank and crier will call into the github report lib when a prowjob needs to be reported, so as a user you only want to make one of them to report :-)
To disable GitHub reporting in Plank, add the --skip-report=true flag to the Plank deployment.
Before migrating, be sure plank is setting the PrevReportStates field by describing a finished presubmit prowjob. Plank started to set this field after commit 2118178, if not, you want to upgrade your plank to a version includes this commit before moving forward.
you can check this entry by:
$ kubectl get prowjobs -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.prev_report_states.github-reporter}{"\n"}'
...
fafec9e1-3af2-11e9-ad1a-0a580a6c0d12 failure
fb027a97-3af2-11e9-ad1a-0a580a6c0d12 success
fb0499d3-3af2-11e9-ad1a-0a580a6c0d12 failure
fb05935f-3b2b-11e9-ad1a-0a580a6c0d12 success
fb05e1f1-3af2-11e9-ad1a-0a580a6c0d12 error
fb06c55c-3af2-11e9-ad1a-0a580a6c0d12 success
fb09e7d8-3abb-11e9-816a-0a580a6c0f7f success
You want to add a crier deployment, similar to ours config/prow/cluster/crier_deployment.yaml, flags need to be specified:
- point
config-pathand--job-config-pathto your prow config and job configs accordingly. - Set
--github-workerto be number of parallel github reporting threads you need - Point
--github-endpointto ghproxy, if you have set that for plank - Bind github oauth token as a secret and set
--github-token-pathif you’ve have that set for plank.
In your plank deployment, you can
- Remove the
--github-endpointflags - Remove the github oauth secret, and
--github-token-pathflag if set - Flip on
--skip-report, so plank will skip the reporting logic
Both change should be deployed at the same time, if have an order preference, deploy crier first since report twice should just be a no-op.
We will send out an announcement when we cleaning up the report dependency from plank in later 2019.
2 - Deck
Running Deck locally
Deck can be run locally by executing ./cmd/deck/runlocal. The scripts starts Deck via
Bazel using:
- pre-generated data (extracted from a running Prow instance)
- the local
config.yaml - the local static files, template files and lenses
Open your browser and go to: http://localhost:8080
Debugging via Intellij / VSCode
This section describes how to debug Deck locally by running it inside VSCode or Intellij.
# Prepare assets
make build-tarball PROW_IMAGE=cmd/deck
mkdir -p /tmp/deck
tar -xvf ./_bin/deck.tar -C /tmp/deck
cd /tmp/deck
# Expand all layers
for tar in *.tar.gz; do tar -xvf $tar; done
# Start Deck via go or in your IDE with the following arguments:
--config-path=./config/prow/config.yaml
--job-config-path=./config/jobs
--hook-url=http://prow.k8s.io
--spyglass
--template-files-location=/tmp/deck/var/run/ko/template
--static-files-location=/tmp/deck/var/run/ko/static
--spyglass-files-location=/tmp/deck/var/run/ko/lenses
Rerun Prow Job via Prow UI
Rerun prow job can be done by visiting prow UI, locate prow job and rerun job by clicking on the ↻ button, selecting a configuration option, and then clicking Rerun button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow.
See example below:

Rerunning can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
Abort Prow Job via Prow UI
Aborting a prow job can be done by visiting the prow UI, locate the prow job and abort the job by clicking on the ✕ button, and then clicking Confirm button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow. Note, the abort functionality uses the same field as rerun for permissions.
See example below:

Aborting can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
2.1 - How to setup GitHub Oauth
This document helps configure GitHub Oauth, which is required for PR Status and for the rerun button on Prow Status. If OAuth is configured, Prow will perform GitHub actions on behalf of the authenticated users. This is necessary to fetch information about pull requests for the PR Status page and to authenticate users when checking if they have permission to rerun jobs via the rerun button on Prow Status.
Set up secrets
The following steps will show you how to set up an OAuth app.
-
Create your GitHub Oauth application
https://developer.github.com/apps/building-oauth-apps/creating-an-oauth-app/
Make sure to create a GitHub Oauth App and not a regular GitHub App.
The callback url should be:
<PROW_BASE_URL>/github-login/redirect -
Create a secret file for GitHub OAuth that has the following content. The information can be found in the GitHub OAuth developer settings:
client_id: <APP_CLIENT_ID> client_secret: <APP_CLIENT_SECRET> redirect_url: <PROW_BASE_URL>/github-login/redirect final_redirect_url: <PROW_BASE_URL>/prIf Prow is expected to work with private repositories, add
scopes: - repo -
Create another secret file for the cookie store. This cookie secret will also be used for CSRF protection. The file should contain a random 32-byte length base64 key. For example, you can use
opensslto generate the keyopenssl rand -out cookie.txt -base64 32 -
Use
kubectl, which should already point to your Prow cluster, to create secrets using the command:kubectl create secret generic github-oauth-config --from-file=secret=<PATH_TO_YOUR_GITHUB_SECRET>kubectl create secret generic cookie --from-file=secret=<PATH_TO_YOUR_COOKIE_KEY_SECRET> -
To use the secrets, you can either:
-
Mount secrets to your deck volume:
Open
test-infra/config/prow/cluster/deck_deployment.yaml. Undervolumestoken, add:- name: oauth-config secret: secretName: github-oauth-config - name: cookie-secret secret: secretName: cookieUnder
volumeMountstoken, add:- name: oauth-config mountPath: /etc/githuboauth readOnly: true - name: cookie-secret mountPath: /etc/cookie readOnly: true -
Add the following flags to
deck:- --github-oauth-config-file=/etc/githuboauth/secret - --oauth-url=/github-login - --cookie-secret=/etc/cookie/secretNote that the
--oauth-urlshould eventually be changed to a boolean as described in #13804. -
You can also set your own path to the cookie secret using the
--cookie-secretflag. -
To prevent
deckfrom making mutating GitHub API calls, pass in the--dry-runflag.
-
Using A GitHub bot
The rerun button can be configured so that certain GitHub teams are allowed to trigger certain jobs
from the frontend. In order to make API calls to determine whether a user is on a given team, deck needs
to use the access token of an org member.
If not, you can create a new GitHub account, make it an org member, and set up a personal access token here.
Then create the access token secret:
kubectl create secret generic oauth-token --from-file=secret=<PATH_TO_ACCESS_TOKEN>
Add the following to volumes and volumeMounts:
volumeMounts:
- name: oauth-token
mountPath: /etc/github
readOnly: true
volumes:
- name: oauth-token
secret:
secretName: oauth-token
Pass the file path to deck as a flag:
--github-token-path=/etc/github/oauth
You can optionally use ghproxy to reduce token usage.
Run PR Status endpoint locally
Firstly, you will need a GitHub OAuth app. Please visit step 1 - 3 above.
When testing locally, pass the path to your secrets to deck using the --github-oauth-config-file and --cookie-secret flags.
Run the command:
go build . && ./deck --config-path=../../../config/prow/config.yaml --github-oauth-config-file=<PATH_TO_YOUR_GITHUB_OAUTH_SECRET> --cookie-secret=<PATH_TO_YOUR_COOKIE_SECRET> --oauth-url=/pr
Using a test cluster
If hosting your test instance on http instead of https, you will need to use the --allow-insecure flag in deck.
2.2 - CSRF attacks
In Deck, we make a number of POST requests that require user authentication. These requests are susceptible
to cross site request forgery (CSRF) attacks,
in which a malicious actor tricks an already authenticated user into submitting a form to one of these endpoints
and performing one of these protected actions on their behalf.
Protection
If --cookie-secret is 32 or more bytes long, CSRF protection is automatically enabled.
If --rerun-creates-job is specified, CSRF protection is required, and accordingly,
--cookie-secret must be 32 bytes long.
We protect against CSRF attacks using the gorilla CSRF library, implemented
in #13323. Broadly, this protection works by ensuring that
any POST request originates from our site, rather than from an outside link.
We do so by requiring that every POST request made to Deck includes a secret token either in the request header
or in the form itself as a hidden input.
We cryptographically generate the CSRF token using the --cookie-secret and a user session value and
include it as a header in every POST request made from Deck.
If you are adding a new POST request, you must include the CSRF token as described in the gorilla
documentation.
The gorilla library expects a 32-byte CSRF token. If --cookie-secret is sufficiently long,
direct job reruns will be enabled via the /rerun endpoint. Otherwise, if --cookie-secret is less
than 32 bytes and --rerun-creates-job is enabled, Deck will refuse to start. Longer values will
work but should be truncated.
By default, gorilla CSRF requires that all POST requests are made over HTTPS. If developing locally
over HTTP, you must specify --allow-insecure to Deck, which will configure both gorilla CSRF
and GitHub oauth to allow HTTP requests.
CSRF can also be executed by tricking a user into making a state-mutating GET request. All
state-mutating requests must therefore be POST requests, as gorilla CSRF does not secure GET
requests.
3 - Hook
This is a placeholder page. Some contents needs to be filled.
4 - Horologium
This is a placeholder page. Some contents needs to be filled.
5 - Prow-Controller-Manager
prow-controller-manager manages the job execution and lifecycle for jobs running in k8s.
It currently acts as a replacement for Plank.
It is intended to eventually replace other components, such as Sinker and Crier. See the tracking issue #17024 for details.
Advantages
- Eventbased rather than cronbased, hence reacting much faster to changes in prowjobs or pods
- Per-Prowjob retrying, meaning genuinely broken prowjobs will not be retried forever and transient errors will be retried much quicker
- Uses a cache for the build cluster rather than doing a LIST every 30 seconds, reducing the load on the build clusters api server
Exclusion with other components
This is mutually exclusive with only Plank. Only one of them may have more than zero replicas at the same time.
Usage
$ go run ./cmd/prow-controller-manager --help
Configuration
6 - Sinker
This is a placeholder page. Some contents needs to be filled.
7 - Tide
Tide is a Prow component for managing a pool of GitHub PRs that match a given set of criteria. It will automatically retest PRs that meet the criteria (“tide comes in”) and automatically merge them when they have up-to-date passing test results (“tide goes out”).
Documentation
Features
- Automatically runs batch tests and merges multiple PRs together whenever possible.
- Ensures that PRs are tested against the most recent base branch commit before they are allowed to merge.
- Maintains a GitHub status context that indicates if each PR is in a pool or what requirements are missing.
- Supports blocking merge to individual branches or whole repos using specifically labelled GitHub issues.
- Exposes Prometheus metrics.
- Supports repos that have ‘optional’ status contexts that shouldn’t be required for merge.
- Serves live data about current pools and a history of actions which can be consumed by Deck to populate the Tide dashboard, the PR dashboard, and the Tide history page.
- Scales efficiently so that a single instance with a single bot token can provide merge automation to dozens of orgs and repos with unique merge criteria. Every distinct ‘org/repo:branch’ combination defines a disjoint merge pool so that merges only affect other PRs in the same branch.
- Provides configurable merge modes (‘merge’, ‘squash’, or ‘rebase’).
History
Tide was created in 2017 by @spxtr to replace mungegithub’s Submit Queue. It was designed to manage a large number of repositories across organizations without using many API rate limit tokens by identifying mergeable PRs with GitHub search queries fulfilled by GitHub’s v4 GraphQL API.
Flowchart
graph TD;
subgraph github[GitHub]
subgraph org/repo/branch
head-ref[HEAD ref];
pullrequest[Pull Request];
status-context[Status Context];
end
end
subgraph prow-cluster
prowjobs[Prowjobs];
config.yaml;
end
subgraph tide-workflow
Tide;
pools;
divided-pools;
pools-->|dividePool|divided-pools;
filtered-pools;
subgraph syncSubpool
pool-i;
pool-n;
pool-n1;
accumulated-batch-prowjobs-->|filter out <br> incorrect refs <br> no longer meet merge requirement|valid-batches;
valid-batches-->accumulated-batch-success;
valid-batches-->accumulated-batch-pending;
status-context-->|fake prowjob from context|filtered-prowjobs;
filtered-prowjobs-->|accumulate|map_context_best-result;
map_context_best-result-->map_pr_overall-results;
map_pr_overall-results-->accumulated-success;
map_pr_overall-results-->accumulated-pending;
map_pr_overall-results-->accumulated-stale;
subgraph all-accumulated-pools
accumulated-batch-success;
accumulated-batch-pending;
accumulated-success;
accumulated-pending;
accumulated-stale;
end
accumulated-batch-success-..->accumulated-batch-success-exist{Exist};
accumulated-batch-pending-..->accumulated-batch-pending-exist{Exist};
accumulated-success-..->accumulated-success-exist{Exist};
accumulated-pending-..->accumulated-pending-exist{Exist};
accumulated-stale-..->accumulated-stale-exist{Exist};
pool-i-..->require-presubmits{Require Presubmits};
accumulated-batch-success-exist-->|yes|merge-batch[Merge batch];
merge-batch-->|Merge Pullrequests|pullrequest;
accumulated-batch-success-exist-->|no|accumulated-batch-pending-exist;
accumulated-batch-pending-exist-->|no|accumulated-success-exist;
accumulated-success-exist-->|yes|merge-single[Merge Single];
merge-single-->|Merge Pullrequests|pullrequest;
require-presubmits-->|no|wait;
accumulated-success-exist-->|no|require-presubmits;
require-presubmits-->|yes|accumulated-pending-exist;
accumulated-pending-exist-->|no|can-trigger-batch{Can Trigger New Batch};
can-trigger-batch-->|yes|trigger-batch[Trigger new batch];
can-trigger-batch-->|no|accumulated-stale-exist;
accumulated-stale-exist-->|yes|trigger-highest-pr[Trigger Jobs on Highest Priority PR];
accumulated-stale-exist-->|no|wait;
end
end
Tide-->pools[Pools - grouped PRs, prow jobs by org/repo/branch];
pullrequest-->pools;
divided-pools-->|filter out prs <br> failed prow jobs <br> pending non prow checks <br> merge conflict <br> invalid merge method|filtered-pools;
head-ref-->divided-pools;
prowjobs-->divided-pools;
config.yaml-->divided-pools;
filtered-pools-->pool-i;
filtered-pools-->pool-n;
filtered-pools-->pool-n1[pool ...];
pool-i-->|report tide status|status-context;
pool-i-->|accumulateBatch|accumulated-batch-prowjobs;
pool-i-->|accumulateSerial|filtered-prowjobs;
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef github fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef pools-def fill:#00ffff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef decision fill:#ffff00,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef outcome fill:#00cc66,stroke:#bbb,stroke-width:2px,color:#326ce5;
class prowjobs,config.yaml k8s;
class Tide plain;
class status-context,head-ref,pullrequest github;
class accumulated-batch-success,accumulated-batch-pending,accumulated-success,accumulated-pending,accumulated-stale pools-def;
class accumulated-batch-success-exist,accumulated-batch-pending-exist,accumulated-success-exist,accumulated-pending-exist,accumulated-stale-exist,can-trigger-batch,require-presubmits decision;
class trigger-highest-pr,trigger-batch,merge-single,merge-batch,wait outcome;
7.1 - Configuring Tide
Configuration of Tide is located under the config/prow/config.yaml file. All configuration for merge behavior and criteria belongs in the tide yaml struct, but it may be necessary to also configure presubmits for Tide to run against PRs (see ‘Configuring Presubmit Jobs’ below).
This document will describe the fields of the tide configuration and how to populate them, but you can also check out the GoDocs for the most up to date configuration specification.
To deploy Tide for your organization or repository, please see how to get started with prow.
General configuration
The following configuration fields are available:
sync_period: The field specifies how often Tide will sync jobs with GitHub. Defaults to 1m.status_update_period: The field specifies how often Tide will update GitHub status contexts. Defaults to the value ofsync_period.queries: List of queries (described below).merge_method: A key/value pair of anorg/repoas the key and merge method to override the default method of merge as value. Valid options aresquash,rebase, andmerge. Defaults tomerge.merge_commit_template: A mapping fromorg/repoororgto a set of Go templates to use when creating the title and body of merge commits. Go templates are evaluated with aPullRequest(seePullRequesttype). This field and map keys are optional.target_urls: A mapping from “*”,, or <org/repo> to the URL for the tide status contexts. The most specific key that matches will be used. pr_status_base_urls: A mapping from “*”,, or <org/repo> to the base URL for the PR status page. If specified, this URL is used to construct a link that will be used for the tide status context. It is mutually exclusive with the target_urlsfield.max_goroutines: The maximum number of goroutines spawned inside the component to handle org/repo:branch pools. Defaults to 20. Needs to be a positive number.blocker_label: The label used to identify issues which block merges to repository branches.squash_label: The label used to ask Tide to use the squash method when merging the labeled PR.rebase_label: The label used to ask Tide to use the rebase method when merging the labeled PR.merge_label: The label used to ask Tide to use the merge method when merging the labeled PR.
Merge Blocker Issues
Tide supports temporary holds on merging into branches via the blocker_label configuration option.
In order to use this option, set the blocker_label configuration option for the Tide deployment.
Then, when blocking merges is required, if an open issue is found with the label it will block merges to
all branches for the repo. In order to scope the branches which are blocked, add a branch:name token
to the issue title. These tokens can be repeated to select multiple branches and the tokens also support
quoting, so branch:"name" will block the name branch just as branch:name would.
Queries
The queries field specifies a list of queries.
Each query corresponds to a set of open PRs as candidates for merging.
It can consist of the following dictionary of fields:
orgs: List of queried organizations.repos: List of queried repositories.excludedRepos: List of ignored repositories.labels: List of labels any given PR must posses.missingLabels: List of labels any given PR must not posses.excludedBranches: List of branches that get excluded when querying therepos.includedBranches: List of branches that get included when querying therepos.author: The author of the PR.reviewApprovedRequired: If set, each PR in the query must have at least one approved GitHub pull request review present for merge. Defaults tofalse.
Under the hood, a query constructed from the fields follows rules described in https://help.github.com/articles/searching-issues-and-pull-requests/. Therefore every query is just a structured definition of a standard GitHub search query which can be used to list mergeable PRs. The field to search token correspondence is based on the following mapping:
orgs->org:kubernetesrepos->repo:kubernetes/test-infralabels->label:lgtmmissingLabels->-label:do-not-mergeexcludedBranches->-base:devincludedBranches->base:masterauthor->author:batmanreviewApprovedRequired->review:approved
Every PR that needs to be rebased or is failing required statuses is filtered from the pool before processing
Context Policy Options
A PR will be merged when all checks are passing. With this option you can customize which contexts are required or optional.
By default, required and optional contexts will be derived from Prow Job Config. This allows to find if required checks are missing from the GitHub combined status.
If branch-protection config is defined, it can be used to know which test needs
be passing to merge a PR.
When branch protection is not used, required and optional contexts can be defined globally, or at the org, repo or branch level.
If we want to skip unknown checks (ie checks that are not defined in Prow Config), we can set
skip-unknown-contexts to true. This option can be set globally or per org,
repo and branch.
Important: If this option is not set and no prow jobs are defined tide will trust the GitHub
combined status and will assume that all checks are required (except for it’s own tide status).
Example
tide:
merge_method:
kubeflow/community: squash
target_url: https://prow.k8s.io/tide
queries:
- repos:
- kubeflow/community
- kubeflow/examples
labels:
- lgtm
- approved
missingLabels:
- do-not-merge
- do-not-merge/hold
- do-not-merge/work-in-progress
- needs-ok-to-test
- needs-rebase
context_options:
# Use branch-protection options from this file to define required and optional contexts.
# this is convenient if you are using branchprotector to configure branch protection rules
# as tide will use the same rules as will be added by the branch protector
from-branch-protection: true
# Specify how to handle contexts that are detected on a PR but not explicitly listed in required-contexts,
# optional-contexts, or required-if-present-contexts. If true, they are treated as optional and do not
# block a merge. If false or not present, they are treated as required and will block a merge.
skip-unknown-contexts: true
orgs:
org:
required-contexts:
- "check-required-for-all-repos"
repos:
repo:
required-contexts:
- "check-required-for-all-branches"
branches:
branch:
from-branch-protection: false
required-contexts:
- "required_test"
optional-contexts:
- "optional_test"
required-if-present-contexts:
- "conditional_test"
Explanation: The component starts periodically querying all PRs in github.com/kubeflow/community and
github.com/kubeflow/examples repositories that have lgtm and approved labels set
and do not have do-not-merge, do-not-merge/hold, do-not-merge/work-in-progress, needs-ok-to-test and needs-rebase labels set.
All PRs that conform to the criteria are processed and merged.
The processing itself can include running jobs (e.g. tests) to verify the PRs are good to go.
All commits in PRs from github.com/kubeflow/community repository are squashed before merging.
For a full list of properties of queries, please refer to https://github.com/kubernetes/test-infra/blob/27c9a7f2784088c2db5ff133e8a7a1e2eab9ab3f/prow/config/prow-config-documented.yaml#:~:text=meet%20merge%20requirements.-,queries%3A,-%2D%20author%3A%20%27%20%27.
Persistent Storage of Action History
Tide records a history of the actions it takes (namely triggering tests and merging). This history is stored in memory, but can be loaded from GCS and periodically flushed in order to persist across pod restarts. Persisting action history to GCS is strictly optional, but is nice to have if the Tide instance is restarted frequently or if users want to view older history.
Both the --history-uri and --gcs-credentials-file flags must be specified to Tide
to persist history to GCS. The GCS credentials file should be a GCP service account
key file
for a service account that has permission to read and write the history GCS object.
The history URI is the GCS object path at which the history data is stored. It should
not be publicly readable if any repos are sensitive and must be a GCS URI like gs://bucket/path/to/object.
Configuring Presubmit Jobs
Before a PR is merged, Tide ensures that all jobs configured as required in the presubmits part of the config.yaml file are passing against the latest base branch commit, rerunning the jobs if necessary. No job is required to be configured in which case it’s enough if a PR meets all GitHub search criteria.
Semantic of individual fields of the presubmits is described in ProwJobs.
7.2 - Maintainer's Guide to Tide
Best practices
- Don’t let humans (or other bots) merge especially if tests have a long duration. Every merge invalidates currently running tests for that pool.
- Try to limit the total number of queries that you configure. Individual queries can cover many repos and include many criteria without using additional API tokens, but separate queries each require additional API tokens.
- Ensure that merge requirements configured in GitHub match the merge requirements configured for Tide. If the requirements differ, Tide may try to merge a PR that GitHub considers unmergeable.
- If you are using the
lgtmplugin and requiring thelgtmlabel for merge, don’t make queries exclude theneeds-ok-to-testlabel. Thelgtmplugin triggers one round of testing when applied to an untrusted PR and removes thelgtmlabel if the PR changes so it indicates to Tide that the current version of the PR is considered trusted and can be retested safely. - Do not enable the “Require branches to be up to date before merging” GitHub setting for repos managed by Tide. This requires all PRs to be rebased before merge so that PRs are always simple fast-forwards. This is a simplistic way to ensure that PRs are tested against the most recent base branch commit, but Tide already provides this guarantee through a more sophisticated mechanism that does not force PR authors to rebase their PR whenever another PR merges first. Enabling this GH setting may cause unexpected Tide behavior, provides absolutely no benefit over Tide’s natural behavior, and forces PR author’s to needlessly rebase their PRs. Don’t use it on Tide managed repos.
Expected behavior that might seem strange
- Any merge to a pool kicks all other PRs in the pool back into
Queued for retest. This is because Tide requires PRs to be tested against the most recent base branch commit in order to be merged. When a merge occurs, the base branch updates so any existing or in-progress tests can no longer be used to qualify PRs for merge. All remaining PRs in the pool must be retested. - Waiting to merge a successful PR because a batch is pending. This is because Tide prioritizes batches over individual PRs and the previous point tells us that merging the individual PR would invalidate the pending batch. In this case Tide will wait for the batch to complete and will merge the individual PR only if the batch fails. If the batch succeeds, the batch is merged.
- If the merge requirements for a pool change it may be necessary to “poke” or “bump” PRs to trigger an update on the PRs so that Tide will resync the status context. Alternatively, Tide can be restarted to resync all statuses.
- Tide may merge a PR without retesting if the existing test results are already against the latest base branch commit.
- It is possible for
tidestatus contexts on PRs to temporarily differ from the Tide dashboard or Tide’s behavior. This is because status contexts are updated asynchronously from the main Tide sync loop and have a separate rate limit and loop period.
Troubleshooting
- If Prow’s PR dashboard indicates that a PR is ready to merge and it appears to meet all merge requirements, but the PR is being ignored by Tide, you may have encountered a rare bug with GitHub’s search indexing. TLDR: If this is the problem, then any update to the PR (e.g. adding a comment) will make the PR visible to Tide again after a short delay. The longer explanation is that when GitHub’s background jobs for search indexing PRs fail, the search index becomes corrupted and the search API will have some incorrect belief about the affected PR, e.g. that it is missing a required label or still has a forbidden one. This causes the search query Tide uses to identify the mergeable PRs to incorrectly omit the PR. Since the same search engine is used by both the API and GitHub’s front end, you can confirm that the affected PR is not included in the query for mergeable PRs by using the appropriate “GitHub search link” from the expandable “Merge Requirements” section on the Tide status page. You can actually determine which particular index is corrupted by incrementally tweaking the query to remove requirements until the PR is included. Any update to the PR causes GitHub to kick off a new search indexing job in the background. Once it completes, the corrupted index should be fixed and Tide will be able to see the PR again in query results, allowing Tide to resume processing the PR. It appears any update to the PR is sufficient to trigger reindexing so we typically just leave a comment. Slack thread about an example of this.
Other resources
7.3 - PR Author's Guide to Tide
If you just want to figure out how to get your PR to merge this is the document for you!
Sources of Information
- The
tidestatus context at the bottom of your PR. The status either indicates that your PR is in the merge pool or explains why it is not in the merge pool. The ‘Details’ link will take you to either the Tide or PR dashboard.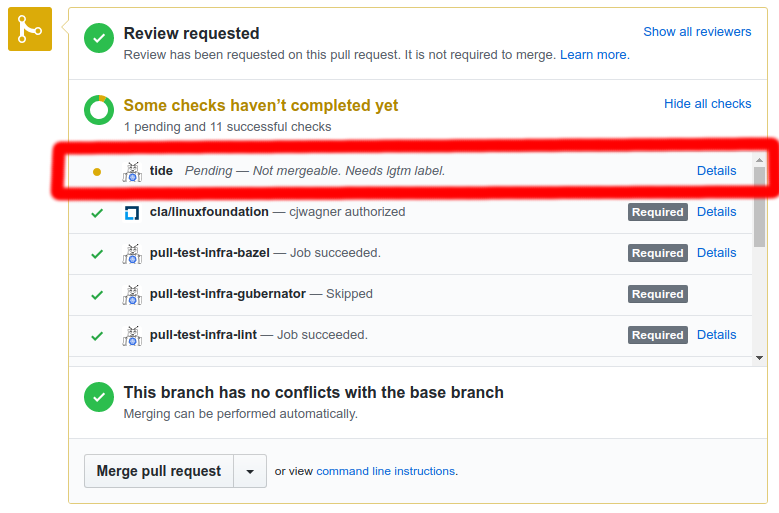
- The PR dashboard at “
<deck-url>/pr” where<deck-url>is something like “https://prow.k8s.io”. This dashboard shows a card for each of your PRs. Each card shows the current test results for the PR and the difference between the PR state and the merge criteria. K8s PR dashboard - The Tide dashboard at “
<deck-url>/tide”. This dashboard shows the state of every merge pool so that you can see what Tide is currently doing and what position your PR has in the retest queue. K8s Tide dashboard
Get your PR merged by asking these questions
“Is my PR in the merge pool?”
If the tide status at the bottom of your PR is successful (green) it is in the merge pool. If it is pending (yellow) it is not in the merge pool.
“Why is my PR not in the merge pool?”
First, if you just made a change to the PR, give Tide a minute or two to react. Tide syncs periodically (1m period default) so you shouldn’t expect to see immediate reactions.
To determine why your PR is not in the merge pool you have a couple options.
- The
tidestatus context at the bottom of your PR will describe at least one of the merge criteria that is not being met. The status has limited space for text so only a few failing criteria can typically be listed. To see all merge criteria that are not being met check out the PR dashboard. - The PR dashboard shows the difference between your PR’s state and the merge criteria so that you can easily see all criteria that are not being met and address them in any order or in parallel.
“My PR is in the merge pool, what now?”
Once your PR is in the merge pool it is queued for merge and will be automatically retested before merge if necessary. So typically your work is done! The one exception is if your PR fails a retest. This will cause the PR to be removed from the merge pool until it is fixed and is passing all the required tests again.
If you are eager for your PR to merge you can view all the PRs in the pool on the Tide dashboard to see where your PR is in the queue. Because we give older PRs (lower numbers) priority, it is possible for a PR’s position in the queue to increase.
Note: Batches of PRs are given priority over individual PRs so even if your PR is in the pool and has up-to-date tests it won’t merge while a batch is running because merging would update the base branch making the batch jobs stale before they complete. Similarly, whenever any other PR in the pool is merged, existing test results for your PR become stale and a retest becomes necessary before merge. However, your PR remains in the pool and will be automatically retested so this doesn’t require any action from you.