This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Announcements
- 2: Overview
- 2.1: Architecture
- 3: Components
- 3.1: Core Components
- 3.1.1: Crier
- 3.1.2: Deck
- 3.1.2.1: How to setup GitHub Oauth
- 3.1.2.2: CSRF attacks
- 3.1.3: Hook
- 3.1.4: Horologium
- 3.1.5: Prow-Controller-Manager
- 3.1.6: Sinker
- 3.1.7: Tide
- 3.1.7.1: Configuring Tide
- 3.1.7.2: Maintainer's Guide to Tide
- 3.1.7.3: PR Author's Guide to Tide
- 3.2: Optional Components
- 3.2.1: Branchprotector
- 3.2.2: Exporter
- 3.2.3: gcsupload
- 3.2.4: Gerrit
- 3.2.5: HMAC
- 3.2.6: jenkins-operator
- 3.2.7: status-reconciler
- 3.2.8: tot
- 3.2.8.1: fallbackcheck
- 3.2.9: Gangway (Prow API)
- 3.2.10: Sub
- 3.3: CLI Tools
- 3.3.1: checkconfig
- 3.3.2: config-bootstrapper
- 3.3.3: generic-autobumper
- 3.3.4: invitations-accepter
- 3.3.5: mkpj
- 3.3.6: mkpod
- 3.3.7: Peribolos
- 3.3.8: Phaino
- 3.3.9: Phony
- 3.3.10: tackle
- 3.4: Pod Utilities
- 3.4.1: clonerefs
- 3.4.2: entrypoint
- 3.4.3: initupload
- 3.4.4: sidecar
- 3.5: Plugins
- 3.5.1: approve
- 3.5.1.1: Reviewers and Approvers
- 3.5.2: branchcleaner
- 3.5.3: lgtm
- 3.5.4: updateconfig
- 3.6: External Plugins
- 3.6.1: cherrypicker
- 3.7: Deprecated Components
- 3.7.1: cm2kc (clustermap to kubeconfig)
- 3.7.2: Plank
- 3.8: Undocumented Components
- 3.8.1: admission
- 3.8.2: grandmatriarch
- 3.8.3: pipeline
- 4: GKE Build Clusters
- 5: Contribution Guidelines
- 6: Metrics
- 7: Building, Testing, and Updating Prow
- 8: Deploying Prow
- 9: Developing and Contributing to Prow
- 10: Getting more out of Prow
- 11: GitHub API Library
- 12: ghProxy
- 12.1: ghCache
- 12.2: Additional throttling algorithm
- 13: Inrepoconfig
- 14: Life of a Prow Job
- 15: Prow Configuration
- 16: Prow Secrets Management
- 17: Gerrit
- 18: ProwJobs
- 19: Setting up Private Deck
- 20: Spyglass
- 20.1: Spyglass Architecture
- 20.2: Build a Spyglass Lens
- 20.3: REST API coverage lens
- 21: Using Prow at Scale
- 22: Understanding Started.json and Finished.json
- 23: Testing Prow
- 23.1: Run Prow integration tests
- 23.1.1: Fake Git Server (FGS)
- 24: Legacy Snapshot
1 - Announcements
New features
New features added to each component:
-
October 20, 2023 The update to Inrepoconfig handling will break users if they have symlinks inside
.prow/that point to targets elsewhere in the codebase. See this comment for details. -
January 20, 2023 Remove k8s-ci-robot at-mention autoresponse for instances that does not warrant additional explanation in the details section.
-
August 4, 2022 override plugin will now override checkruns set by GitHub Actions and other CI systems on a PR.
-
June 8, 2022
deck.rerun_auth_configscan optionally be replaced withdeck.default_rerun_auth_configswhich supports a new format that is a slice of filters with associated rerun auth configs rather than a map. Currently entries can filter by repo and/or cluster. The old field is still supported and will not be deprecated. -
April 6, 2022 Highlight and pin interesting lines. To do this, shift-click on log lines in the buildlog lens. The URL fragment causes the same lines to be highlighted next page load. Additionally, when viewing a GCS log pressing the pin button saves the highlight. The saved highlight automatically displays next page load.
-
January 24, 2022 It is possible now to define GitHub Apps bots as trusted users to allow automatic tests trigger without relying on
/ok-to-testfrom organization member. Trigger and DCO plugins configuration now support additional fieldtrusted_apps, which contains list of GitHub Apps bot usernames without[bot]suffix. -
January 11, 2022 Trigger plugin can now trigger failed github jobs. The feature needs to be enabled in the
triggerssection of theplugin.yamlconfig and can be specified per trigger as follows:triggers: - repos: - org/repo - org2 trigger_github_workflows: true -
August 24, 2021 Postsubmit Prow jobs now support the
always_runfield. This field interacts with therun_if_changedandskip_if_only_changedfields as follows:- (NEW) If the field is explicitly set to
always_run: false, then the Postsubmit will not run automatically. The intention is to allow other triggers outside of a GitHub change, such as a Pub/Sub event, to trigger the job. See this issue for the motivation. However ifrun_if_changedorskip_if_only_changedis also set, then those triggers are determined first; if for whatever reason they cannot be determined, then the job will not run automatically (and wait for another trigger such as a Pub/Sub event as mentioned above). - If the field is explicitly set to
always_run: true, then the Postsubmit job will always run. Also trying to setrun_if_changedorskip_if_only_changedin the same Postsubmit job will result in a config error. This mutual exclusivity matches the configuration behavior of Presubmit jobs, which also disallow combiningalways_run: truetogether withrun_if_changedorskip_if_only_changed. - If
always_runis not set (missing from the job config):- If both
run_if_changedandskip_if_only_changedare not set: same as old behavior (Postsubmit job will run automatically upon a GitHub change). - If one of
run_if_changedorskip_if_only_changedis set: same as old behavior (running will depend onrun_if_changedorskip_if_only_changed).
- If both
- (NEW) If the field is explicitly set to
-
May 14th, 2021: All components that interact with GitHub newly allow client-side throttling customization via
--github-hourly-tokensand--github-allowed-burstparameters. A notable exception to this is Tide which has custom throttling logic and does not expose these two new options. Other existing custom options in branchprotector, peribolos, status-reconciler and needs-rebase (--tokens/--hourly-tokensetc.) are deprecated and will be removed in August 2021. -
April 12th, 2021 End of grace period for storage bucket validation, additional buckets have to be allowed by adding them to the
deck.additional_allowed_bucketslist. -
March 9th, 2021 Tide batchtesting will now continue to test a given batch even when more PRs became eligible while a test failed. You can disable this by setting
tide.prioritize_existing_batches.<org or org/repo>: falsein your Prow config. -
March 3, 2021
plank.default_decoration_configscan optionally be replaced withplank.default_decoration_config_entrieswhich supports a new format that is a slice of filters with associated decoration configs rather than a map. Currently entries can filter by repo and/or cluster. The old field is still supported and will not be deprecated. -
February 23, 2021 New format introduced in
plugins.yaml. Repos can be excluded from plugin definition at org level usingexcluded_reposnotation. The previous format will be deprecated in July 2021, see https://github.com/kubernetes/test-infra/issues/20631. -
November 2, 2020 Tide is now able to respect checkruns.
-
September 15, 2020 Added validation to Deck that will restrict artifact requests based on storage buckets. Opt-out by setting
deck.skip_storage_path_validationin your Prow config. Buckets specified in job configs (<job>.gcs_configuration.bucket) and plank configs (plank.default_decoration_configs[*].gcs_configuration.bucket) are automatically allowed access. Additional buckets can be allowed by adding them to thedeck.additional_allowed_bucketslist. (This feature will be enabled by default ~Jan 2021. For now, you will begin to notice violation warnings in your logs.) -
August 31th, 2020 Added
gcs_browser_prefixesfield in spyglass configuration.gcs_browser_prefixwill be deprecated in February 2021. You can now specify different values for different repositories. The format should be in org, org/repo or ‘*’ which is the default value. -
July 13th, 2020 Configuring
job_url_prefix_configwithgcs/prefix is now deprecated. Please configure a job url prefix without thegcs/storage provider suffix. From now on the storage provider is appended automatically so multiple storage providers can be used for builds of the same repository. For now we still handle the old configuration format, this will be removed in September 2020. To be clear handling of URLs with/view/gcsin Deck is not deprecated. -
June 23rd, 2020 An hmac tool was added to automatically reconcile webhooks and hmac tokens for the orgs and repos integrated with your prow instance.
-
June 8th, 2020 A new informer-based Plank implementation was added. It can be used by deploying the new prow-controller-manager binary. We plan to gradually move all our controllers into that binary, see https://github.com/kubernetes/test-infra/issues/17024
-
May 31, 2020 ‘–gcs-no-auth’ in Deck is deprecated and not used anymore. We always fall back to an anonymous GCS client now, if all other options fail. This flag will be removed in July 2020.
-
May 25, 2020 Added
--blob-storage-workersand--kubernetes-blob-storage-workersflags to crier. The flags--gcs-workersand--kubernetes-gcs-workersare now deprecated and will be removed in August 2020. -
May 13, 2020 Added a
decorate_all_jobsoption to job configuration that allows to control whether jobs are decorated by default. Individual jobs can use thedecorateoption to override this setting. -
March 25, 2020 Added a
report_templatesoption to the Plank config that allows to specify different report templates for each organization or a specific repository. Thereport_templateoption is deprecated and it will be removed on September 2020 which is going to be replaced with the*value inreport_templates. -
January 03, 2020 Added a
pr_status_base_urlsoption to the Tide config that allows to specify different tide’s URL for each organization or a specific repository. Thepr_status_base_urlwill be deprecated on June 2020 and it will be replaced with the*value inpr_status_base_urls. -
November 05, 2019 The
config-updaterplugin supports update configs on build clusters by usingclusters. The fields namespace and additional_namespaces are deprecated. -
October 27, 2019 The
trusted_orgfunctionality in trigger is being deprecated in favour of being more explicit in the fact that org members or repo collaborators are the trusted users. This option will be removed completely in January 2020. -
October 07, 2019 Added a
default_decoration_configsoption to the Plank config that allows to specify different plank’s default configuration for each organization or a specific repository.default_decoration_configwill be deprecated in April 2020 and it will be replaced with the*value indefault_decoration_configs. -
August 29, 2019 Added a
batch_size_limitoption to the Tide config that allows the batch size limit to be specified globally, per org, or per repo. Values default to 0 indicating no size limit. A value of -1 disables batches. -
July 30, 2019
authorized_usersinrerun_auth_configfor deck will becomegithub_users. -
July 19, 2019 deck will soon remove its default value for
--cookie-secret-file. If you set--oauth-urlbut not--cookie-secret-file, add--cookie-secret-file=/etc/cookie-secretto your deck instance. The default value will be removed at the end of October 2019. -
July 2, 2019 prow defaults to report status for both presubmit and postsubmit jobs on GitHub now.
-
June 17, 2019 It is now possible to configure the channel for the Slack reporter directly on jobs via the
.reporter_config.slack.channelconfig option -
May 13, 2019 New
plankconfigpod_running_timeoutis added and defaulted to two days to allow plank abort pods stuck in running state. -
April 25, 2019
--job-configinperiboloshas never been used; it is deprecated and will be removed in July 2019. Remove the flag from any calls to the tool. -
April 24, 2019
file_weight_countin blunderbuss is being deprecated in favour of the more currentmax_request_countfunctionality. Please ensure your configuration is up to date before the end of May 2019. -
March 12, 2019 tide now records a history of its actions and exposes a filterable view of these actions at the
/tide-historydeck path. -
March 9, 2019 prow components now support reading gzipped config files
-
February 13, 2019 prow (both plank and crier) can set status on the commit for postsubmit jobs on github now! Type of jobs can be reported to github is gated by a config field like
github_reporter: job_types_to_report: - presubmit - postsubmitnow and default to report for presubmit only. The default will change in April to include postsubmit jobs as well You can also add
skip_report: trueto your post-submit jobs to skip reporting if you enable postsubmit reporting on. -
January 15, 2019
approvenow considers self-approval and github review state by default. Configure withrequire_self_approvalandignore_review_state. Temporarily revert to old defaults withuse_deprecated_2018_implicit_self_approve_default_migrate_before_july_2019anduse_deprecated_2018_review_acts_as_approve_default_migrate_before_july_2019. -
January 12, 2019
blunderblussplugin now provides a new command,/auto-cc, that triggers automatic review requests. -
January 7, 2019
implicit_self_approvewill becomerequire_self_approvalin the second half of this year. -
January 7, 2019
review_acts_as_approvewill becomeignore_review_statein the second half of this year. -
October 10, 2018
tidenow supports the-repo:foo/bartag in queries via theexcludedReposYAML field. -
October 3, 2018
welcomenow supports a configurable message on a per-org, or per-repo basis. Please note that this includes a config schema change that will break previous deployments of this plugin. -
August 22, 2018
spyglassis a pluggable viewing framework for artifacts produced by Prowjobs. See a demo here! -
July 13, 2018
blunderblussplugin will now supportrequired_reviewersin OWNERS file to specify a person or github team to be cc’d on every PR that touches the corresponding part of the code. -
June 25, 2018
updateconfigplugin will now support update/remove keys from a glob match. -
June 05, 2018
blunderbussplugin may now suggest approvers in addition to reviewers. Useexclude_approvers: trueto revert to previous behavior. -
April 10, 2018
claplugin now supports/check-clacommand to force rechecking of the CLA status. -
February 1, 2018
updateconfigwill now update any configmap on merge -
November 14, 2017
jenkins-operator:0.58exposes prometheus metrics. -
November 8, 2017
horologium:0.14prow periodic job now support cron triggers. See https://godoc.org/gopkg.in/robfig/cron.v2 for doc to the cron library we are using.
Breaking changes
Breaking changes to external APIs (labels, GitHub interactions, configuration or deployment) will be documented in this section. Prow is in a pre-release state and no claims of backwards compatibility are made for any external API. Note: versions specified in these announcements may not include bug fixes made in more recent versions so it is recommended that the most recent versions are used when updating deployments.
-
August 24th, 2022 Deck by default validating storage buckets, can still opt out by setting
deck.skip_storage_path_validation: truein your Prow config. Buckets specified in job configs (<job>.gcs_configuration.bucket) and plank configs (plank.default_decoration_configs[*].gcs_configuration.bucket) are automatically allowed access. Additional buckets can be allowed by adding them to thedeck.additional_allowed_bucketslist. -
May 27th, 2022 Crier flags
--gcs-workersand--kubernetes-gcs-workersare removed in favor of--blob-storage-workersand--kubernetes-blob-storage-workers. -
May 27th, 2022 The
owners_dir_blacklistfield in prow config is removed in favor ofowners_dir_denylist. -
February 22nd, 2022 Since prow version
v20220222-acb5731b85, the entrypoint container in a prow job will run as--copy-mode-only, instead of/bin/cp /entrypoint /tools/entrypoint. Entrypoint images before the mentioned version will not work with--copy-mode-only, and entrypoint image since the mentioned version will not work with/bin/cp /entrypoint /tools/entrypoint. In another word, prow versions newer than or equal tov20220222-acb5731b85will stop working with pod utilities versions older thanv20220222-acb5731b85. If your prow instance is bumped byprow/cmd/generic-autobumperthen you should not be affected. -
February 22nd, 2022 Since prow version
v20220222-acb5731b85, prow images pushed to gcr.io/k8s-prow will be built with ko, and the binaries will be placed under/ko-app/, for example /robots/commenter is pushed to gcr.io/k8s-prow/commenter, the commenter binary is located at/ko-app/commenterin the image, prow jobs that use this image will update tocommand: - /ko-app/commenterto make it work, alternatively, the command could also becommand: - commenteras/ko-appis added to$PATHenv var in the image. -
February 22nd, 2022 Since prow version
v20220222-acb5731b85, static files indeckimage will be stored under/var/run/ko/directory. -
October 27th, 2021 The checkconfig flag
--prow-yaml-repo-pathno longer defaults to/home/prow/go/src/github.com/<< prow-yaml-repo-name >>/.prow.yamlwhen--prow-yaml-repo-nameis set. The defaulting has instead been replaced with the assumption that the Prow YAML file/directory can be found in the current working directory if--prow-yaml-repo-pathis not specified. If you are running checkconfig from a decorated ProwJobs as is typical, then this is already the case. -
September 16th, 2021 The ProwJob CRD manifest has been extended to specify a schema. Unfortunately, this results in a huge manifest which in turn makes the standard
kubectl applyfail, as the last-applied annotation it generates exceeds the maximum annotation size. If you are using Kubernetes 1.18 or newer, you can add the--server-side=trueargument to work around this. If not, you can use a schemaless manifest -
September 15th, 2021
autobumpremoved, please usegeneric-autobumperinstead, see example config -
April 16th, 2021 Flagutil remove default value for
--github-token-path. -
April 15th, 2021 Sinker requires –dry-run=false (default is true) to function correctly in production.
-
April 14th, 2021 Deck remove default value for
--cookie-secret-file. -
April 12th, 2021 Horologium now uses a cached client, which requires it to have watch permissions for Prowjobs on top of the already-required list and create.
-
April 11th, 2021 The plank binary has been removed. Please use the Prow Controller Manager instead, which provides a more modern implementation of the same functionality.
-
April 1st, 2021 The
owners_dir_blacklistfield in prow config has been deprecated in favor ofowners_dir_denylist. The support ofowners_dir_blacklistwill be stopped in October 2021. -
April 1st, 2021 The
labels_blacklistfield in verify-owners plugin config is deprecated in favor oflabels_denylist. The support forlabels_blacklistshall be stopped in October 2021. -
January 24th, 2021 Planks Pod pending and Pod scheduling timeout defaults where changed from 24h each to the more reasonable 10 minutes/5 minutes, respectively.
-
January 1, 2021 Support for
whitelistandbranch_whitelistfields in Slack merge warning configuration is discontinued. You can useexempt_usersandexempt_branchesfields instead. -
November 24, 2020 The
requiresigplugin has been removed in favor of therequire-matching-labelplugin which provides equivalent functionality (example plugin config) -
November 14, 2020 The
whitelistandbranch_whitelistfields in Slack merge warning were deprecated on August 22, 2020 in favor of the newexempt_usersandexempt_branchesfields. The support for these fields shall be stopped in January 2021. -
November 11th, 2020 The prow-controller-manager and sinker now require RBAC to be set up to manage their leader lock in the
coordination.k8s.iogroup. See here -
November, 2020 The deprecated
namespaceandadditional_namespacesproperties have been removed from the config updater plugin for more details. -
November, 2020 The
blacklistflag in status reconciler has been deprecated in favor ofdenylist. The support ofblacklistwill be stopped in February 2021. -
October, 2020 The
plankbinary has been deprecated in favor of the more modern implementation in the prow-controller-manager that provides the same functionality. Check out its README or check out its deployment and rbac manifest. The plank binary will be removed in February, 2021. -
September 14th, 2020 Sinker now requires
LISTandWATCHpermissions for pods -
September 2, 2020 The already deprecated
namespaceandadditional_namespacessettings in the config updater will be removed in October, 2020 -
August 28, 2020
tidenow ignores archived repositories in queries. -
August 28, 2020 The
Clustersformat and associated--build-clusterflag has been removed. -
August 24, 2020 The deprecated reporting functionality has been removed from Plank, use crier with
--github-workers=1instead Use a.kube/configwith the--kubeconfigflag to specify credentials for external build clusters. -
August 22, 2020 The
whitelistandbranch_whitelistfields in Slack merge warning are deprecated in favor of the newexempt_usersandexempt_branchesfields. -
July 17, 2020 Slack reporter will no longer report all states of a Prow job if it has
Channelspecified on the Prow job config. Instead, it will report thejob_states_to_reportconfigured in the Prow job or in the Prow core config if the former does not exist. -
May 18, 2020
expiryfield has been replaced withcreated_atin the HMAC secret. -
April 24, 2020 Horologium now defaults to
--dry-run=true -
April 23, 2020 Explicitly setting
--config-pathis now required. -
April 23, 2020 Update the
autobumpimage to at leastv20200422-8c8546d74before June 2020. -
April 23, 2020 Deleted deprecated
default_decoration_config. -
April 22, 2020 Deleted the
file_weight_countblunderbuss option. -
April 16, 2020 The
docs-no-retestprow plugin has been deleted. The plugin was deprecated in January 2020. -
April 14, 2020 GitHub reporting via plank is deprecated, set –github-workers=1 on crier before July 2020.
-
March 27, 2020 The deprecated
allow_cancellationsoption has been removed from Plank and the Jenkins operator. -
March 19, 2020 The
rerun_auth_configconfig field has been deprecated in favor of the newrerun_auth_configsfield which allows configuration on a global, organization or repo level.rerun_auth_configwill be removed in July 2020. -
November 21, 2019 The boskos metrics component replaced the existing prometheus metrics with a single, label-qualified metric. Metrics are now served at
/metricson port 9090. This actually happened August 5th, but is being documented now. Details: https://github.com/kubernetes/test-infra/pull/13767 -
November 18, 2019 The
mkbuild-clustercommand-line utility andbuild-clusterformat is deprecated and will be removed in May 2020. Usegencredand thekubeconfigformat as an alternative. -
November 14, 2019 The
slack_reporterconfig field has been deprecated in favor of the newslack_reporter_configsfield which allows configuration on a global, organization or repo level.slack_reporterwill be removed in May 2020. -
November 7, 2019 The
plank.allow_cancellationsandjenkins_operators.allow_cancellationssettings are deprecated and will be removed and set to alwaystruein March 2020. -
October 7, 2019 Prow will drop support for the deprecated knative-builds in November 2019.
-
September 24, 2019 Sending an http
GETrequest to the/hookendpoint now returns a405(Method Not Allowed) instead of a200(OK). -
September 8, 2019 The deprecated
job_url_prefixoption has been removed from Plank. -
May 2, 2019 All components exposing Prometheus metrics will now either push them to the Prometheus PushGateway, if configured, or serve them locally on port 9090 at
/metrics, if not configured (the default). -
April 26, 2019
blunderbuss,approve, and other plugins that read OWNERS now treatowners_dir_blacklistas a list of regular expressions matched against the entire (repository-relative) directory path of the OWNERS file rather than as a list of strings matched exactly against the basename only of the directory containing the OWNERS file. -
April 2, 2019
hook,deck,horologium,tide,plankandsinkerwill no longer provide a default value for the--config-pathflag. It is required to explicitly provide--config-pathwhen upgrading to a new version of these components that were previously relying on the default--config-path=/etc/config/config.yaml. -
March 29, 2019 Custom logos should be provided as full paths in the configuration under
deck.branding.logosand will not implicitly be assumed to be under the static assets directory. -
February 26, 2019 The
job_url_prefixoption fromplankhas been deprecated in favor of the newjob_url_prefix_configoption which allows configuration on a global, organization or repo level.job_url_prefixwill be removed in September 2019. -
February 13, 2019
horologiumandsinkerdeployments will soon require--dry-run=falsein production, please set this before March 15. At that time flag will default to –dry-run=true instead of –dry-run=false. -
February 1, 2019 Now that
hookandtidewill no longer post “Skipped” statuses for jobs that do not need to run, it is not possible to require those statuses with branch protection. Therefore, it is necessary to run thebranchprotectorfrom at least version510db59before upgradingtideto that version. -
February 1, 2019
horologiumandsinkernow support the--dry-runflag, so you must pass--dry-run=falseto keep the previous behavior (see Feb 13 update). -
January 31, 2019
subno longer supports the--masterurlflag for connecting to the infrastructure cluster. Use--kubeconfigwith--contextfor this. -
January 31, 2019
crierno longer supports the--masterurlflag for connecting to the infrastructure cluster. Use--kubeconfigwith--contextfor this. -
January 27, 2019 Jobs that do not run will no longer post “Skipped” statuses.
-
January 27, 2019 Jobs that do not run always will no longer be required by branch protection as they will not always produce a status. They will continue to be required for merge by
tideif they are configured as required. -
January 27, 2019 All support for
run_after_successjobs has been removed. Configuration of these jobs will continue to parse but will ignore the field. -
January 27, 2019
hookwill now correctly honor therun_alwaysfield on Gerrit presubmits. Previously, if this field was unset it would have defaulted totrue; now, it will correctly default tofalse. -
January 22, 2019
sinkerprefers.kube/configinstead of the customClustersfile to specify credentials for external build clusters. The flag name has changed from--build-clusterto--kubeconfig. Migrate before June 2019. -
November 29, 2018
plankwill no longer default jobs withdecorate: trueto haveautomountServiceAccountToken: falsein their PodSpec if unset, if the job explicitly setsserviceAccountName -
November 26, 2018 job names must now match
^[A-Za-z0-9-._]+$. Jobs that did not match this before were allowed but did not provide a good user experience. -
November 15, 2018 the
hookservice account now requires RBAC privileges to createConfigMapsto support new functionality in theupdateconfigplugin. -
November 9, 2018 Prow gerrit client label/annotations now have a
prow.k8s.io/namespace prefix, if you have a gerrit deployment, please bump both cmd/gerrit and cmd/crier. -
November 8, 2018
planknow defaults jobs withdecorate: trueto haveautomountServiceAccountToken: falsein their PodSpec if unset. Jobs that used the default service account should explicitly set this field to maintain functionality. -
October 16, 2018 Prow tls-cert management has been migrated from kube-lego to cert-manager.
-
October 12, 2018 Removed deprecated
buildIdenvironment variable from prow jobs. UseBUILD_ID. -
October 3, 2018
-github-token-filereplaced with-github-token-pathfor consistency withbranchprotectorandperiboloswhich were already using-github-token-path.-github-token-filewill continue to work through the remainder of 2018, but it will be removed in early 2019. The following commands are affected:cherrypicker,hook,jenkins-operator,needs-rebase,phony,plank,refresh, andtide. -
October 1, 2018 bazel is the one official way to build container images. Please use prow/bump.sh and/or bazel run //prow:release-push
-
Sep 27, 2018 If you are setting explicit decorate configs, the format has changed from
- name: job-foo decorate: true timeout: 1to
- name: job-foo decorate: true decoration_config: timeout: 1 -
September 24, 2018 the
splicecomponent has been deleted following the deletion of mungegithub. -
July 9, 2018
milestoneformat has changed frommilestone: maintainers_id: <some_team_id> maintainers_team: <some_team_name>to
repo_milestonerepo_milestone: <some_repo_name>: maintainers_id: <some_team_id> maintainers_team: <some_team_name> -
July 2, 2018 the
triggerplugin will now trust PRs from repo collaborators. Useonly_org_members: truein the trigger config to temporarily disable this behavior. -
June 14, 2018 the
updateconfigplugin will only add data to yourConfigMapsusing the basename of the updated file, instead of using that and also duplicating the data using the name of theConfigMapas a key -
June 1, 2018 all unquoted
booleanfields in config.yaml that were unmarshall into typestringnow need to be quoted to avoid unmarshalling error. -
May 9, 2018
decklogs for jobs run asPodswill now return logs for the"test"container only. -
April 2, 2018
updateconfigformat has been changed frompath/to/some/other/thing: configNameto
path/to/some/other/thing: Name: configName # If unspecified, Namespace default to the value of ProwJobNamespace. Namespace: myNamespace -
March 15, 2018
jenkins_operatoris removed from the config in favor ofjenkins_operators. -
March 1, 2018
MilestoneStatushas been removed from the plugins Configuration in favor of theMilestonewhich is shared between two plugins: 1)milestonestatusand 2)milestone. The milestonestatus plugin now uses theMilestoneobject to get the maintainers team ID -
February 27, 2018
jenkins-operatordoes not use$BUILD_IDas a fallback to$PROW_JOB_IDanymore. -
February 15, 2018
jenkins-operatorcan now accept the--tot-urlflag and will use the connection tototto vend build identifiers asplankdoes, giving control over where in GCS artifacts land to Prow and away from Jenkins. Furthermore, the$BUILD_IDvariable in Jenkins jobs will now correctly point to the build identifier vended bytotand a new variable,$PROW_JOB_ID, points to the identifier used to link ProwJobs to Jenkins builds.$PROW_JOB_IDfallbacks to$BUILD_IDfor backwards-compatibility, ie. to not break in-flight jobs during the time of the jenkins-operator update. -
February 1, 2018 The
config_updatersection inplugins.yamlnow uses amapsobject instead ofconfig_file,plugin_filestrings. Please switch over before July. -
November 30, 2017 If you use tide, you’ll need to switch your query format and bump all prow component versions to reflect the changes in #5754.
-
November 14, 2017
horologium:0.17fixes cron job not being scheduled. -
November 10, 2017 If you want to use cron feature in prow, you need to bump to:
hook:0.181,sinker:0.23,deck:0.62,splice:0.32,horologium:0.15plank:0.60,jenkins-operator:0.57andtide:0.12to avoid error spamming from the config parser. -
November 7, 2017
plank:0.56fixes bug introduced inplank:0.53that affects controllers using an empty kubernetes selector. -
November 7, 2017
jenkins-operator:0.51provides jobs with the$BUILD_IDvariable as well as the$buildIdvariable. The latter is deprecated and will be removed in a future version. -
November 6, 2017
plank:0.55providesPodswith the$BUILD_IDvariable as well as the$BUILD_NUMBERvariable. The latter is deprecated and will be removed in a future version. -
November 3, 2017 Added
EmptyDirvolume type. To update tohook:0.176+orhorologium:0.11+the following components must have the associated minimum versions:deck:0.58+,plank:0.54+,jenkins-operator:0.50+. -
November 2, 2017
plank:0.53changes thetypelabel key toprow.k8s.io/typeand thejobannotation key toprow.k8s.io/jobadded in pods. -
October 14, 2017
deck:0:53+needs to be updated in conjunction withjenkins-operator:0:48+since Jenkins logs are now exposed from the operator anddeckneeds to use theexternal_agent_logsoption in order to redirect requests to the locationjenkins-operatorexposes logs. -
October 13, 2017
hook:0.174,plank:0.50, andjenkins-operator:0.47drop the deprecatedgithub-bot-nameflag. -
October 2, 2017
hook:0.171: The label plugin was split into three plugins (label, sigmention, milestonestatus). Breaking changes:- The configuration key for the milestone maintainer team’s ID has been
changed. Previously the team ID was stored in the plugins config at key
label»milestone_maintainers_id. Now that the milestone status labels are handled in themilestonestatusplugin instead of thelabelplugin, the team ID is stored at keymilestonestatus»maintainers_id. - The sigmention and milestonestatus plugins must be enabled on any repos that require them since their functionality is no longer included in the label plugin.
- The configuration key for the milestone maintainer team’s ID has been
changed. Previously the team ID was stored in the plugins config at key
-
September 3, 2017
sinker:0.17now deletes pods labeled byplank:0.42in order to avoid cleaning up unrelated pods that happen to be found in the same namespace prow runs pods. If you run other pods in the same namespace, you will have to manually delete or label the prow-owned pods, otherwise you can bulk-label all of them with the following command and let sinker collect them normally:kubectl label pods --all -n pod_namespace created-by-prow=true -
September 1, 2017
deck:0.44andjenkins-operator:0.41controllers no longer provide a default value for the--jenkins-token-fileflag. Cluster administrators should provide--jenkins-token-file=/etc/jenkins/jenkinsexplicitly when upgrading to a new version of these components if they were previously relying on the default. For more context, please see this pull request. -
August 29, 2017 Configuration specific to plugins is now held in the
pluginsConfigMapand serialized in this repo in theplugins.yamlfile. Cluster administrators upgrading tohook:0.148or newer should move plugin configuration from the mainConfigMap. For more context, please see this pull request.
Project updates
- October 28, 2022 Documentation migration: existing Markdown files in k/t-i have been migrated over to https://docs.prow.k8s.io/docs/legacy-snapshot. The old locations now have “tombstones” to redirect to the new location. See https://github.com/kubernetes/test-infra/pull/27818 for details.
2 - Overview
Prow is a Kubernetes based CI/CD system. Jobs can be triggered by various types of events and report their status to many different services. In addition to job execution, Prow provides GitHub automation in the form of policy enforcement, chat-ops via /foo style commands, and automatic PR merging.
See the GoDoc for library docs. Please note that these libraries are intended for use by prow only, and we do not make any attempt to preserve backwards compatibility.
For a brief overview of how Prow runs jobs take a look at “Life of a Prow Job”.
To see common Prow usage and interactions flow, see the pull request interactions sequence diagram.
{kind=link}
Functions and Features
- Job execution for testing, batch processing, artifact publishing.
- GitHub events are used to trigger post-PR-merge (postsubmit) jobs and on-PR-update (presubmit) jobs.
- Support for multiple execution platforms and source code review sites.
- Pluggable GitHub bot automation that implements
/foostyle commands and enforces configured policies/processes. - GitHub merge automation with batch testing logic.
- Front end for viewing jobs, merge queue status, dynamically generated help information, and more.
- Automatic deployment of source control based config.
- Automatic GitHub org/repo administration configured in source control.
- Designed for multi-org scale with dozens of repositories. (The Kubernetes Prow instance uses only 1 GitHub bot token!)
- High availability as benefit of running on Kubernetes. (replication, load balancing, rolling updates…)
- JSON structured logs.
- Prometheus metrics.
Documentation
Getting started
- With your own Prow deployment: “Deploying Prow”
- With developing for Prow: “Developing and Contributing to Prow”
- As a job author: ProwJobs
More details
Tests
The stability of prow is heavily relying on unit tests and integration tests.
- Unit tests are co-located with prow source code
- Integration tests utilizes kind with hermetic integration tests. See instructions for adding new integration tests for more details
Useful Talks
KubeCon 2020 EU virtual
KubeCon 2018 EU
KubeCon 2018 China
KubeCon 2018 Seattle
- Behind you PR: K8s with K8s on K8s
- Using Prow for Testing Outside of K8s
- Jenkins X (featuring Tide)
- SIG Testing Intro
- SIG Testing Deep Dive
Misc
Prow in the wild
Prow is used by the following organizations and projects:
- Kubernetes
- This includes kubernetes, kubernetes-client, kubernetes-csi, and kubernetes-sigs.
- OpenShift
- This includes openshift, openshift-s2i, operator-framework, and some repos in containers and heketi.
- Istio
- Knative
- Jetstack
- Kyma
- Metal³
- Prometheus
- Caicloud
- Kubeflow
- Azure AKS Engine
- tensorflow/minigo
- Daisy (Google Compute Image Tools)
- KubeEdge (Kubernetes Native Edge Computing Framework)
- Volcano (Kubernetes Native Batch System)
- Loodse
- Feast
- Falco
- TiDB
- Amazon EKS Distro and Amazon EKS Anywhere
- KubeSphere
- OpenYurt
- KubeVirt
- AWS Controllers for Kubernetes
- Gardener
Jenkins X uses Prow as part of Serverless Jenkins.
Contact us
If you need to contact the maintainers of Prow you have a few options:
- Open an issue in the kubernetes/test-infra repo.
- Reach out to the
#prowchannel of the Kubernetes Slack. - Contact one of the code owners in prow/OWNERS or in a more specifically scoped OWNERS file.
Bots home
@k8s-ci-robot lives here and is the face of the Kubernetes Prow instance. Here is a command list for interacting with @k8s-ci-robot and other Prow bots.
2.1 - Architecture
Prow in a Nutshell
Prow creates jobs based on various types of events, such as:
-
GitHub events (e.g., a new PR is created, or is merged, or a person comments “/retest” on a PR),
-
Pub/Sub messages,
-
time (these are created by Horologium and are called periodic jobs), and
-
retesting (triggered by Tide).
Jobs are created inside the Service Cluster as Kubernetes Custom Resources. The Prow Controller Manager takes triggered jobs and schedules them into a build cluster, where they run as Kubernetes pods. Crier then reports the results back to GitHub.
flowchart TD
classDef yellow fill:#ff0
classDef cyan fill:#0ff
classDef pink fill:#f99
subgraph Service Cluster["<span style='font-size: 40px;'><b>Service Cluster</b></span>"]
Deck:::cyan
Prowjobs:::yellow
Crier:::cyan
Tide:::cyan
Horologium:::cyan
Sinker:::cyan
PCM[Prow Controller Manager]:::cyan
Hook:::cyan
subgraph Hook
WebhookHandler["Webhook Handler"]
PluginCat(["'cat' plugin"])
PluginTrigger(["'trigger' plugin"])
end
end
subgraph Build Cluster[<b>Build Cluster</b>]
Pods[(Pods)]:::yellow
end
style Legend fill:#fff,stroke:#000,stroke-width:4px
subgraph Legend["<span style='font-size: 20px;'><b>LEGEND</b></span>"]
direction LR
k8sResource[Kubernetes Resource]:::yellow
prowComponent[Prow Component]:::cyan
hookPlugin([Hook Plugin])
Other
end
Prowjobs <-.-> Deck <-----> |Serve| prow.k8s.io
GitHub ==> |Webhooks| WebhookHandler
WebhookHandler --> |/meow| PluginCat
WebhookHandler --> |/retest| PluginTrigger
Prowjobs <-.-> Tide --> |Retest and Merge| GitHub
Horologium ---> |Create| Prowjobs
PluginCat --> |Comment| GitHub
PluginTrigger --> |Create| Prowjobs
Sinker ---> |Garbage collect| Prowjobs
Sinker --> |Garbage collect| Pods
PCM -.-> |List and update| Prowjobs
PCM ---> |Report| Prowjobs
PCM ==> |Create and Query| Pods
Prowjobs <-.-> |Inform| Crier --> |Report| GitHub
Notes
Note that Prow can also work with Gerrit, albeit with less features. Specifically, neither Tide nor Hook work with Gerrit yet.
3 - Components
Prow Images
This directory includes a sub directory for every Prow component and is where all binary and container images are built. You can find the main packages here. For details about building the binaries and images see “Building, Testing, and Updating Prow”.
Cluster Components
Prow has a microservice architecture implemented as a collection of container images that run as Kubernetes deployments. A brief description of each service component is provided here.
Core Components
crier(doc, code) reports on ProwJob status changes. Can be configured to report to gerrit, github, pubsub, slack, etc.deck(doc, code) presents a nice view of recent jobs, command and plugin help information, the current status and history of merge automation, and a dashboard for PR authors.hook(doc, code) is the most important piece. It is a stateless server that listens for GitHub webhooks and dispatches them to the appropriate plugins. Hook’s plugins are used to trigger jobs, implement ‘slash’ commands, post to Slack, and more. See the plugins doc and code directory for more information on plugins.horologium(doc, code) triggers periodic jobs when necessary.prow-controller-manager(doc, code) manages the job execution and lifecycle for jobs that run in k8s pods. It currently acts as a replacement forplanksinker(doc, code) cleans up old jobs and pods.
Merge Automation
tide(doc, code) manages retesting and merging PRs once they meet the configured merge criteria. See its README for more information.
Optional Components
branchprotector(doc, code) configures github branch protection according to a specified policyexporter(doc, code) exposes metrics about ProwJobs not directly related to a specific Prow componentgcsupload(doc, code)gerrit(doc, code) is a Prow-gerrit adapter for handling CI on gerrit workflowshmac(doc, code) updates HMAC tokens, GitHub webhooks and HMAC secrets for the orgs/repos specified in the Prow config filejenkins-operator(doc, code) is the controller that manages jobs that run on Jenkins. We moved away from using this component in favor of running all jobs on Kubernetes.tot(doc, code) vends sequential build numbers. Tot is only necessary for integration with automation that expects sequential build numbers. If Tot is not used, Prow automatically generates build numbers that are monotonically increasing, but not sequential.status-reconciler(doc, code) ensures changes to blocking presubmits in Prow configuration does not cause in-flight GitHub PRs to get stucksub(doc, code) listen to Cloud Pub/Sub notification to trigger Prow Jobs.
CLI Tools
checkconfig(doc, code) loads and verifies the configuration, useful as a pre-submit.config-bootstrapper(doc, code) bootstraps a configuration that would be incrementally updated by theupdateconfigProw plugingeneric-autobumper(doc, code) automates image version upgrades (e.g. for a Prow deployment) by opening a PR with images changed to their latest version according to a config file.invitations-accepter(doc, code) approves all pending GitHub repository invitationsmkpj(doc, code) createsProwJobsusing Prow configuration.mkpod(doc, code) createsPodsfromProwJobs.peribolos(doc, code) manages GitHub org, team and membership settings according to a config file. Used by kubernetes/orgphaino(doc, code) runs an approximation of a ProwJob on your local workstationphony(doc, code) sends fake webhooks for testing hook and plugins.
Pod Utilities
These are small tools that are automatically added to ProwJob pods for jobs that request pod decoration. They are used to transparently provide source code cloning and upload of metadata, logs, and job artifacts to persistent storage. See their README for more information.
Base Images
The container images in images are used as base images for Prow components.
TODO: undocumented
Deprecated
cm2kc(doc, code) is a CLI tool used to convert a clustermap file to a kubeconfig file. Deprecated because we have moved away from clustermaps; you should usegencredto generate a kubeconfig file directly.
3.1 - Core Components
3.1.1 - Crier
Crier reports your prowjobs on their status changes.
Usage / How to enable existing available reporters
For any reporter you want to use, you need to mount your prow configs and specify --config-path and job-config-path
flag as most of other prow controllers do.
Gerrit reporter
You can enable gerrit reporter in crier by specifying --gerrit-workers=n flag.
Similar to the gerrit adapter, you’ll need to specify --gerrit-projects for
your gerrit projects, and also --cookiefile for the gerrit auth token (leave it unset for anonymous).
Gerrit reporter will send an aggregated summary message, when all gerrit adapter scheduled prowjobs with the same report label finish on a revision. It will also attach a report url so people can find logs of the job.
The reporter will also cast a +1/-1 vote on the prow.k8s.io/gerrit-report-label label of your prowjob,
or by default it will vote on CodeReview label. Where +1 means all jobs on the patshset pass and -1
means one or more jobs failed on the patchset.
Pubsub reporter
You can enable pubsub reporter in crier by specifying --pubsub-workers=n flag.
You need to specify following labels in order for pubsub reporter to report your prowjob:
| Label | Description |
|---|---|
"prow.k8s.io/pubsub.project" |
Your gcp project where pubsub channel lives |
"prow.k8s.io/pubsub.topic" |
The topic of your pubsub message |
"prow.k8s.io/pubsub.runID" |
A user assigned job id. It’s tied to the prowjob, serves as a name tag and help user to differentiate results in multiple pubsub messages |
The service account used by crier will need to have pubsub.topics.publish permission in the project where pubsub channel lives, e.g. by assigning the roles/pubsub.publisher IAM role
Pubsub reporter will report whenever prowjob has a state transition.
You can check the reported result by list the pubsub topic.
GitHub reporter
You can enable github reporter in crier by specifying --github-workers=N flag (N>0).
You also need to mount a github oauth token by specifying --github-token-path flag, which defaults to /etc/github/oauth.
If you have a ghproxy deployed, also remember to point --github-endpoint to your ghproxy to avoid token throttle.
The actual report logic is in the github report library for your reference.
Slack reporter
NOTE: if enabling the slack reporter for the first time, Crier will message to the Slack channel for all ProwJobs matching the configured filtering criteria.
You can enable the Slack reporter in crier by specifying the --slack-workers=n and --slack-token-file=path-to-tokenfile flags.
The --slack-token-file flag takes a path to a file containing a Slack OAuth Access Token.
The OAuth Access Token can be obtained as follows:
- Navigate to: https://api.slack.com/apps.
- Click Create New App.
- Provide an App Name (e.g. Prow Slack Reporter) and Development Slack Workspace (e.g. Kubernetes).
- Click Permissions.
- Add the
chat:write.publicscope using the Scopes / Bot Token Scopes dropdown and Save Changes. - Click Install App to Workspace
- Click Allow to authorize the Oauth scopes.
- Copy the OAuth Access Token.
Once the access token is obtained, you can create a secret in the cluster using that value:
kubectl create secret generic slack-token --from-literal=token=< access token >
Furthermore, to make this token available to Crier, mount the slack-token secret using a volume and set the --slack-token-file flag in the deployment spec.
apiVersion: apps/v1
kind: Deployment
metadata:
name: crier
labels:
app: crier
spec:
selector:
matchLabels:
app: crier
template:
metadata:
labels:
app: crier
spec:
containers:
- name: crier
image: gcr.io/k8s-prow/crier:v20200205-656133e91
args:
- --slack-workers=1
- --slack-token-file=/etc/slack/token
- --config-path=/etc/config/config.yaml
- --dry-run=false
volumeMounts:
- mountPath: /etc/config
name: config
readOnly: true
- name: slack
mountPath: /etc/slack
readOnly: true
volumes:
- name: slack
secret:
secretName: slack-token
- name: config
configMap:
name: config
Additionally, in order for it to work with Prow you must add the following to your config.yaml:
NOTE:
slack_reporter_configsis a map oforg,org/repo, or*(i.e. catch-all wildcard) to a set of slack reporter configs.
slack_reporter_configs:
# Wildcard (i.e. catch-all) slack config
"*":
# default: None
job_types_to_report:
- presubmit
- postsubmit
# default: None
job_states_to_report:
- failure
- error
# required
channel: my-slack-channel
# The template shown below is the default
report_template: "Job {{.Spec.Job}} of type {{.Spec.Type}} ended with state {{.Status.State}}. <{{.Status.URL}}|View logs>"
# "org/repo" slack config
istio/proxy:
job_types_to_report:
- presubmit
job_states_to_report:
- error
channel: istio-proxy-channel
# "org" slack config
istio:
job_types_to_report:
- periodic
job_states_to_report:
- failure
channel: istio-channel
The channel, job_states_to_report and report_template can be overridden at the ProwJob level via the reporter_config.slack field:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
channel: 'override-channel-name'
job_states_to_report:
- success
report_template: "Overridden template for job {{.Spec.Job}}"
spec:
containers:
- image: alpine
command:
- echo
To silence notifications at the ProwJob level you can pass an empty slice to reporter_config.slack.job_states_to_report:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
job_states_to_report: []
spec:
containers:
- image: alpine
command:
- echo
Implementation details
Crier supports multiple reporters, each reporter will become a crier controller. Controllers
will get prowjob change notifications from a shared informer, and you can specify --num-workers to change parallelism.
If you are interested in how client-go works under the hood, the details are explained in this doc
Adding a new reporter
Each crier controller takes in a reporter.
Each reporter will implement the following interface:
type reportClient interface {
Report(pj *v1.ProwJob) error
GetName() string
ShouldReport(pj *v1.ProwJob) bool
}
GetName will return the name of your reporter, the name will be used as a key when we store previous
reported state for each prowjob.
ShouldReport will return if a prowjob should be handled by current reporter.
Report is the actual report logic happens. Return nil means report is successful, and the reported
state will be saved in the prowjob. Return an actual error if report fails, crier will re-add the prowjob
key to the shared cache and retry up to 5 times.
You can add a reporter that implements the above interface, and add a flag to turn it on/off in crier.
Migration from plank for github report
Both plank and crier will call into the github report lib when a prowjob needs to be reported, so as a user you only want to make one of them to report :-)
To disable GitHub reporting in Plank, add the --skip-report=true flag to the Plank deployment.
Before migrating, be sure plank is setting the PrevReportStates field by describing a finished presubmit prowjob. Plank started to set this field after commit 2118178, if not, you want to upgrade your plank to a version includes this commit before moving forward.
you can check this entry by:
$ kubectl get prowjobs -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.prev_report_states.github-reporter}{"\n"}'
...
fafec9e1-3af2-11e9-ad1a-0a580a6c0d12 failure
fb027a97-3af2-11e9-ad1a-0a580a6c0d12 success
fb0499d3-3af2-11e9-ad1a-0a580a6c0d12 failure
fb05935f-3b2b-11e9-ad1a-0a580a6c0d12 success
fb05e1f1-3af2-11e9-ad1a-0a580a6c0d12 error
fb06c55c-3af2-11e9-ad1a-0a580a6c0d12 success
fb09e7d8-3abb-11e9-816a-0a580a6c0f7f success
You want to add a crier deployment, similar to ours config/prow/cluster/crier_deployment.yaml, flags need to be specified:
- point
config-pathand--job-config-pathto your prow config and job configs accordingly. - Set
--github-workerto be number of parallel github reporting threads you need - Point
--github-endpointto ghproxy, if you have set that for plank - Bind github oauth token as a secret and set
--github-token-pathif you’ve have that set for plank.
In your plank deployment, you can
- Remove the
--github-endpointflags - Remove the github oauth secret, and
--github-token-pathflag if set - Flip on
--skip-report, so plank will skip the reporting logic
Both change should be deployed at the same time, if have an order preference, deploy crier first since report twice should just be a no-op.
We will send out an announcement when we cleaning up the report dependency from plank in later 2019.
3.1.2 - Deck
Running Deck locally
Deck can be run locally by executing ./cmd/deck/runlocal. The scripts starts Deck via
Bazel using:
- pre-generated data (extracted from a running Prow instance)
- the local
config.yaml - the local static files, template files and lenses
Open your browser and go to: http://localhost:8080
Debugging via Intellij / VSCode
This section describes how to debug Deck locally by running it inside VSCode or Intellij.
# Prepare assets
make build-tarball PROW_IMAGE=cmd/deck
mkdir -p /tmp/deck
tar -xvf ./_bin/deck.tar -C /tmp/deck
cd /tmp/deck
# Expand all layers
for tar in *.tar.gz; do tar -xvf $tar; done
# Start Deck via go or in your IDE with the following arguments:
--config-path=./config/prow/config.yaml
--job-config-path=./config/jobs
--hook-url=http://prow.k8s.io
--spyglass
--template-files-location=/tmp/deck/var/run/ko/template
--static-files-location=/tmp/deck/var/run/ko/static
--spyglass-files-location=/tmp/deck/var/run/ko/lenses
Rerun Prow Job via Prow UI
Rerun prow job can be done by visiting prow UI, locate prow job and rerun job by clicking on the ↻ button, selecting a configuration option, and then clicking Rerun button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow.
See example below:

Rerunning can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
Abort Prow Job via Prow UI
Aborting a prow job can be done by visiting the prow UI, locate the prow job and abort the job by clicking on the ✕ button, and then clicking Confirm button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow. Note, the abort functionality uses the same field as rerun for permissions.
See example below:

Aborting can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
3.1.2.1 - How to setup GitHub Oauth
This document helps configure GitHub Oauth, which is required for PR Status and for the rerun button on Prow Status. If OAuth is configured, Prow will perform GitHub actions on behalf of the authenticated users. This is necessary to fetch information about pull requests for the PR Status page and to authenticate users when checking if they have permission to rerun jobs via the rerun button on Prow Status.
Set up secrets
The following steps will show you how to set up an OAuth app.
-
Create your GitHub Oauth application
https://developer.github.com/apps/building-oauth-apps/creating-an-oauth-app/
Make sure to create a GitHub Oauth App and not a regular GitHub App.
The callback url should be:
<PROW_BASE_URL>/github-login/redirect -
Create a secret file for GitHub OAuth that has the following content. The information can be found in the GitHub OAuth developer settings:
client_id: <APP_CLIENT_ID> client_secret: <APP_CLIENT_SECRET> redirect_url: <PROW_BASE_URL>/github-login/redirect final_redirect_url: <PROW_BASE_URL>/prIf Prow is expected to work with private repositories, add
scopes: - repo -
Create another secret file for the cookie store. This cookie secret will also be used for CSRF protection. The file should contain a random 32-byte length base64 key. For example, you can use
opensslto generate the keyopenssl rand -out cookie.txt -base64 32 -
Use
kubectl, which should already point to your Prow cluster, to create secrets using the command:kubectl create secret generic github-oauth-config --from-file=secret=<PATH_TO_YOUR_GITHUB_SECRET>kubectl create secret generic cookie --from-file=secret=<PATH_TO_YOUR_COOKIE_KEY_SECRET> -
To use the secrets, you can either:
-
Mount secrets to your deck volume:
Open
test-infra/config/prow/cluster/deck_deployment.yaml. Undervolumestoken, add:- name: oauth-config secret: secretName: github-oauth-config - name: cookie-secret secret: secretName: cookieUnder
volumeMountstoken, add:- name: oauth-config mountPath: /etc/githuboauth readOnly: true - name: cookie-secret mountPath: /etc/cookie readOnly: true -
Add the following flags to
deck:- --github-oauth-config-file=/etc/githuboauth/secret - --oauth-url=/github-login - --cookie-secret=/etc/cookie/secretNote that the
--oauth-urlshould eventually be changed to a boolean as described in #13804. -
You can also set your own path to the cookie secret using the
--cookie-secretflag. -
To prevent
deckfrom making mutating GitHub API calls, pass in the--dry-runflag.
-
Using A GitHub bot
The rerun button can be configured so that certain GitHub teams are allowed to trigger certain jobs
from the frontend. In order to make API calls to determine whether a user is on a given team, deck needs
to use the access token of an org member.
If not, you can create a new GitHub account, make it an org member, and set up a personal access token here.
Then create the access token secret:
kubectl create secret generic oauth-token --from-file=secret=<PATH_TO_ACCESS_TOKEN>
Add the following to volumes and volumeMounts:
volumeMounts:
- name: oauth-token
mountPath: /etc/github
readOnly: true
volumes:
- name: oauth-token
secret:
secretName: oauth-token
Pass the file path to deck as a flag:
--github-token-path=/etc/github/oauth
You can optionally use ghproxy to reduce token usage.
Run PR Status endpoint locally
Firstly, you will need a GitHub OAuth app. Please visit step 1 - 3 above.
When testing locally, pass the path to your secrets to deck using the --github-oauth-config-file and --cookie-secret flags.
Run the command:
go build . && ./deck --config-path=../../../config/prow/config.yaml --github-oauth-config-file=<PATH_TO_YOUR_GITHUB_OAUTH_SECRET> --cookie-secret=<PATH_TO_YOUR_COOKIE_SECRET> --oauth-url=/pr
Using a test cluster
If hosting your test instance on http instead of https, you will need to use the --allow-insecure flag in deck.
3.1.2.2 - CSRF attacks
In Deck, we make a number of POST requests that require user authentication. These requests are susceptible
to cross site request forgery (CSRF) attacks,
in which a malicious actor tricks an already authenticated user into submitting a form to one of these endpoints
and performing one of these protected actions on their behalf.
Protection
If --cookie-secret is 32 or more bytes long, CSRF protection is automatically enabled.
If --rerun-creates-job is specified, CSRF protection is required, and accordingly,
--cookie-secret must be 32 bytes long.
We protect against CSRF attacks using the gorilla CSRF library, implemented
in #13323. Broadly, this protection works by ensuring that
any POST request originates from our site, rather than from an outside link.
We do so by requiring that every POST request made to Deck includes a secret token either in the request header
or in the form itself as a hidden input.
We cryptographically generate the CSRF token using the --cookie-secret and a user session value and
include it as a header in every POST request made from Deck.
If you are adding a new POST request, you must include the CSRF token as described in the gorilla
documentation.
The gorilla library expects a 32-byte CSRF token. If --cookie-secret is sufficiently long,
direct job reruns will be enabled via the /rerun endpoint. Otherwise, if --cookie-secret is less
than 32 bytes and --rerun-creates-job is enabled, Deck will refuse to start. Longer values will
work but should be truncated.
By default, gorilla CSRF requires that all POST requests are made over HTTPS. If developing locally
over HTTP, you must specify --allow-insecure to Deck, which will configure both gorilla CSRF
and GitHub oauth to allow HTTP requests.
CSRF can also be executed by tricking a user into making a state-mutating GET request. All
state-mutating requests must therefore be POST requests, as gorilla CSRF does not secure GET
requests.
3.1.3 - Hook
This is a placeholder page. Some contents needs to be filled.
3.1.4 - Horologium
This is a placeholder page. Some contents needs to be filled.
3.1.5 - Prow-Controller-Manager
prow-controller-manager manages the job execution and lifecycle for jobs running in k8s.
It currently acts as a replacement for Plank.
It is intended to eventually replace other components, such as Sinker and Crier. See the tracking issue #17024 for details.
Advantages
- Eventbased rather than cronbased, hence reacting much faster to changes in prowjobs or pods
- Per-Prowjob retrying, meaning genuinely broken prowjobs will not be retried forever and transient errors will be retried much quicker
- Uses a cache for the build cluster rather than doing a LIST every 30 seconds, reducing the load on the build clusters api server
Exclusion with other components
This is mutually exclusive with only Plank. Only one of them may have more than zero replicas at the same time.
Usage
$ go run ./cmd/prow-controller-manager --help
Configuration
3.1.6 - Sinker
This is a placeholder page. Some contents needs to be filled.
3.1.7 - Tide
Tide is a Prow component for managing a pool of GitHub PRs that match a given set of criteria. It will automatically retest PRs that meet the criteria (“tide comes in”) and automatically merge them when they have up-to-date passing test results (“tide goes out”).
Documentation
Features
- Automatically runs batch tests and merges multiple PRs together whenever possible.
- Ensures that PRs are tested against the most recent base branch commit before they are allowed to merge.
- Maintains a GitHub status context that indicates if each PR is in a pool or what requirements are missing.
- Supports blocking merge to individual branches or whole repos using specifically labelled GitHub issues.
- Exposes Prometheus metrics.
- Supports repos that have ‘optional’ status contexts that shouldn’t be required for merge.
- Serves live data about current pools and a history of actions which can be consumed by Deck to populate the Tide dashboard, the PR dashboard, and the Tide history page.
- Scales efficiently so that a single instance with a single bot token can provide merge automation to dozens of orgs and repos with unique merge criteria. Every distinct ‘org/repo:branch’ combination defines a disjoint merge pool so that merges only affect other PRs in the same branch.
- Provides configurable merge modes (‘merge’, ‘squash’, or ‘rebase’).
History
Tide was created in 2017 by @spxtr to replace mungegithub’s Submit Queue. It was designed to manage a large number of repositories across organizations without using many API rate limit tokens by identifying mergeable PRs with GitHub search queries fulfilled by GitHub’s v4 GraphQL API.
Flowchart
graph TD;
subgraph github[GitHub]
subgraph org/repo/branch
head-ref[HEAD ref];
pullrequest[Pull Request];
status-context[Status Context];
end
end
subgraph prow-cluster
prowjobs[Prowjobs];
config.yaml;
end
subgraph tide-workflow
Tide;
pools;
divided-pools;
pools-->|dividePool|divided-pools;
filtered-pools;
subgraph syncSubpool
pool-i;
pool-n;
pool-n1;
accumulated-batch-prowjobs-->|filter out <br> incorrect refs <br> no longer meet merge requirement|valid-batches;
valid-batches-->accumulated-batch-success;
valid-batches-->accumulated-batch-pending;
status-context-->|fake prowjob from context|filtered-prowjobs;
filtered-prowjobs-->|accumulate|map_context_best-result;
map_context_best-result-->map_pr_overall-results;
map_pr_overall-results-->accumulated-success;
map_pr_overall-results-->accumulated-pending;
map_pr_overall-results-->accumulated-stale;
subgraph all-accumulated-pools
accumulated-batch-success;
accumulated-batch-pending;
accumulated-success;
accumulated-pending;
accumulated-stale;
end
accumulated-batch-success-..->accumulated-batch-success-exist{Exist};
accumulated-batch-pending-..->accumulated-batch-pending-exist{Exist};
accumulated-success-..->accumulated-success-exist{Exist};
accumulated-pending-..->accumulated-pending-exist{Exist};
accumulated-stale-..->accumulated-stale-exist{Exist};
pool-i-..->require-presubmits{Require Presubmits};
accumulated-batch-success-exist-->|yes|merge-batch[Merge batch];
merge-batch-->|Merge Pullrequests|pullrequest;
accumulated-batch-success-exist-->|no|accumulated-batch-pending-exist;
accumulated-batch-pending-exist-->|no|accumulated-success-exist;
accumulated-success-exist-->|yes|merge-single[Merge Single];
merge-single-->|Merge Pullrequests|pullrequest;
require-presubmits-->|no|wait;
accumulated-success-exist-->|no|require-presubmits;
require-presubmits-->|yes|accumulated-pending-exist;
accumulated-pending-exist-->|no|can-trigger-batch{Can Trigger New Batch};
can-trigger-batch-->|yes|trigger-batch[Trigger new batch];
can-trigger-batch-->|no|accumulated-stale-exist;
accumulated-stale-exist-->|yes|trigger-highest-pr[Trigger Jobs on Highest Priority PR];
accumulated-stale-exist-->|no|wait;
end
end
Tide-->pools[Pools - grouped PRs, prow jobs by org/repo/branch];
pullrequest-->pools;
divided-pools-->|filter out prs <br> failed prow jobs <br> pending non prow checks <br> merge conflict <br> invalid merge method|filtered-pools;
head-ref-->divided-pools;
prowjobs-->divided-pools;
config.yaml-->divided-pools;
filtered-pools-->pool-i;
filtered-pools-->pool-n;
filtered-pools-->pool-n1[pool ...];
pool-i-->|report tide status|status-context;
pool-i-->|accumulateBatch|accumulated-batch-prowjobs;
pool-i-->|accumulateSerial|filtered-prowjobs;
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef github fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef pools-def fill:#00ffff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef decision fill:#ffff00,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef outcome fill:#00cc66,stroke:#bbb,stroke-width:2px,color:#326ce5;
class prowjobs,config.yaml k8s;
class Tide plain;
class status-context,head-ref,pullrequest github;
class accumulated-batch-success,accumulated-batch-pending,accumulated-success,accumulated-pending,accumulated-stale pools-def;
class accumulated-batch-success-exist,accumulated-batch-pending-exist,accumulated-success-exist,accumulated-pending-exist,accumulated-stale-exist,can-trigger-batch,require-presubmits decision;
class trigger-highest-pr,trigger-batch,merge-single,merge-batch,wait outcome;
3.1.7.1 - Configuring Tide
Configuration of Tide is located under the config/prow/config.yaml file. All configuration for merge behavior and criteria belongs in the tide yaml struct, but it may be necessary to also configure presubmits for Tide to run against PRs (see ‘Configuring Presubmit Jobs’ below).
This document will describe the fields of the tide configuration and how to populate them, but you can also check out the GoDocs for the most up to date configuration specification.
To deploy Tide for your organization or repository, please see how to get started with prow.
General configuration
The following configuration fields are available:
sync_period: The field specifies how often Tide will sync jobs with GitHub. Defaults to 1m.status_update_period: The field specifies how often Tide will update GitHub status contexts. Defaults to the value ofsync_period.queries: List of queries (described below).merge_method: A key/value pair of anorg/repoas the key and merge method to override the default method of merge as value. Valid options aresquash,rebase, andmerge. Defaults tomerge.merge_commit_template: A mapping fromorg/repoororgto a set of Go templates to use when creating the title and body of merge commits. Go templates are evaluated with aPullRequest(seePullRequesttype). This field and map keys are optional.target_urls: A mapping from “*”,, or <org/repo> to the URL for the tide status contexts. The most specific key that matches will be used. pr_status_base_urls: A mapping from “*”,, or <org/repo> to the base URL for the PR status page. If specified, this URL is used to construct a link that will be used for the tide status context. It is mutually exclusive with the target_urlsfield.max_goroutines: The maximum number of goroutines spawned inside the component to handle org/repo:branch pools. Defaults to 20. Needs to be a positive number.blocker_label: The label used to identify issues which block merges to repository branches.squash_label: The label used to ask Tide to use the squash method when merging the labeled PR.rebase_label: The label used to ask Tide to use the rebase method when merging the labeled PR.merge_label: The label used to ask Tide to use the merge method when merging the labeled PR.
Merge Blocker Issues
Tide supports temporary holds on merging into branches via the blocker_label configuration option.
In order to use this option, set the blocker_label configuration option for the Tide deployment.
Then, when blocking merges is required, if an open issue is found with the label it will block merges to
all branches for the repo. In order to scope the branches which are blocked, add a branch:name token
to the issue title. These tokens can be repeated to select multiple branches and the tokens also support
quoting, so branch:"name" will block the name branch just as branch:name would.
Queries
The queries field specifies a list of queries.
Each query corresponds to a set of open PRs as candidates for merging.
It can consist of the following dictionary of fields:
orgs: List of queried organizations.repos: List of queried repositories.excludedRepos: List of ignored repositories.labels: List of labels any given PR must posses.missingLabels: List of labels any given PR must not posses.excludedBranches: List of branches that get excluded when querying therepos.includedBranches: List of branches that get included when querying therepos.author: The author of the PR.reviewApprovedRequired: If set, each PR in the query must have at least one approved GitHub pull request review present for merge. Defaults tofalse.
Under the hood, a query constructed from the fields follows rules described in https://help.github.com/articles/searching-issues-and-pull-requests/. Therefore every query is just a structured definition of a standard GitHub search query which can be used to list mergeable PRs. The field to search token correspondence is based on the following mapping:
orgs->org:kubernetesrepos->repo:kubernetes/test-infralabels->label:lgtmmissingLabels->-label:do-not-mergeexcludedBranches->-base:devincludedBranches->base:masterauthor->author:batmanreviewApprovedRequired->review:approved
Every PR that needs to be rebased or is failing required statuses is filtered from the pool before processing
Context Policy Options
A PR will be merged when all checks are passing. With this option you can customize which contexts are required or optional.
By default, required and optional contexts will be derived from Prow Job Config. This allows to find if required checks are missing from the GitHub combined status.
If branch-protection config is defined, it can be used to know which test needs
be passing to merge a PR.
When branch protection is not used, required and optional contexts can be defined globally, or at the org, repo or branch level.
If we want to skip unknown checks (ie checks that are not defined in Prow Config), we can set
skip-unknown-contexts to true. This option can be set globally or per org,
repo and branch.
Important: If this option is not set and no prow jobs are defined tide will trust the GitHub
combined status and will assume that all checks are required (except for it’s own tide status).
Example
tide:
merge_method:
kubeflow/community: squash
target_url: https://prow.k8s.io/tide
queries:
- repos:
- kubeflow/community
- kubeflow/examples
labels:
- lgtm
- approved
missingLabels:
- do-not-merge
- do-not-merge/hold
- do-not-merge/work-in-progress
- needs-ok-to-test
- needs-rebase
context_options:
# Use branch-protection options from this file to define required and optional contexts.
# this is convenient if you are using branchprotector to configure branch protection rules
# as tide will use the same rules as will be added by the branch protector
from-branch-protection: true
# Specify how to handle contexts that are detected on a PR but not explicitly listed in required-contexts,
# optional-contexts, or required-if-present-contexts. If true, they are treated as optional and do not
# block a merge. If false or not present, they are treated as required and will block a merge.
skip-unknown-contexts: true
orgs:
org:
required-contexts:
- "check-required-for-all-repos"
repos:
repo:
required-contexts:
- "check-required-for-all-branches"
branches:
branch:
from-branch-protection: false
required-contexts:
- "required_test"
optional-contexts:
- "optional_test"
required-if-present-contexts:
- "conditional_test"
Explanation: The component starts periodically querying all PRs in github.com/kubeflow/community and
github.com/kubeflow/examples repositories that have lgtm and approved labels set
and do not have do-not-merge, do-not-merge/hold, do-not-merge/work-in-progress, needs-ok-to-test and needs-rebase labels set.
All PRs that conform to the criteria are processed and merged.
The processing itself can include running jobs (e.g. tests) to verify the PRs are good to go.
All commits in PRs from github.com/kubeflow/community repository are squashed before merging.
For a full list of properties of queries, please refer to https://github.com/kubernetes/test-infra/blob/27c9a7f2784088c2db5ff133e8a7a1e2eab9ab3f/prow/config/prow-config-documented.yaml#:~:text=meet%20merge%20requirements.-,queries%3A,-%2D%20author%3A%20%27%20%27.
Persistent Storage of Action History
Tide records a history of the actions it takes (namely triggering tests and merging). This history is stored in memory, but can be loaded from GCS and periodically flushed in order to persist across pod restarts. Persisting action history to GCS is strictly optional, but is nice to have if the Tide instance is restarted frequently or if users want to view older history.
Both the --history-uri and --gcs-credentials-file flags must be specified to Tide
to persist history to GCS. The GCS credentials file should be a GCP service account
key file
for a service account that has permission to read and write the history GCS object.
The history URI is the GCS object path at which the history data is stored. It should
not be publicly readable if any repos are sensitive and must be a GCS URI like gs://bucket/path/to/object.
Configuring Presubmit Jobs
Before a PR is merged, Tide ensures that all jobs configured as required in the presubmits part of the config.yaml file are passing against the latest base branch commit, rerunning the jobs if necessary. No job is required to be configured in which case it’s enough if a PR meets all GitHub search criteria.
Semantic of individual fields of the presubmits is described in ProwJobs.
3.1.7.2 - Maintainer's Guide to Tide
Best practices
- Don’t let humans (or other bots) merge especially if tests have a long duration. Every merge invalidates currently running tests for that pool.
- Try to limit the total number of queries that you configure. Individual queries can cover many repos and include many criteria without using additional API tokens, but separate queries each require additional API tokens.
- Ensure that merge requirements configured in GitHub match the merge requirements configured for Tide. If the requirements differ, Tide may try to merge a PR that GitHub considers unmergeable.
- If you are using the
lgtmplugin and requiring thelgtmlabel for merge, don’t make queries exclude theneeds-ok-to-testlabel. Thelgtmplugin triggers one round of testing when applied to an untrusted PR and removes thelgtmlabel if the PR changes so it indicates to Tide that the current version of the PR is considered trusted and can be retested safely. - Do not enable the “Require branches to be up to date before merging” GitHub setting for repos managed by Tide. This requires all PRs to be rebased before merge so that PRs are always simple fast-forwards. This is a simplistic way to ensure that PRs are tested against the most recent base branch commit, but Tide already provides this guarantee through a more sophisticated mechanism that does not force PR authors to rebase their PR whenever another PR merges first. Enabling this GH setting may cause unexpected Tide behavior, provides absolutely no benefit over Tide’s natural behavior, and forces PR author’s to needlessly rebase their PRs. Don’t use it on Tide managed repos.
Expected behavior that might seem strange
- Any merge to a pool kicks all other PRs in the pool back into
Queued for retest. This is because Tide requires PRs to be tested against the most recent base branch commit in order to be merged. When a merge occurs, the base branch updates so any existing or in-progress tests can no longer be used to qualify PRs for merge. All remaining PRs in the pool must be retested. - Waiting to merge a successful PR because a batch is pending. This is because Tide prioritizes batches over individual PRs and the previous point tells us that merging the individual PR would invalidate the pending batch. In this case Tide will wait for the batch to complete and will merge the individual PR only if the batch fails. If the batch succeeds, the batch is merged.
- If the merge requirements for a pool change it may be necessary to “poke” or “bump” PRs to trigger an update on the PRs so that Tide will resync the status context. Alternatively, Tide can be restarted to resync all statuses.
- Tide may merge a PR without retesting if the existing test results are already against the latest base branch commit.
- It is possible for
tidestatus contexts on PRs to temporarily differ from the Tide dashboard or Tide’s behavior. This is because status contexts are updated asynchronously from the main Tide sync loop and have a separate rate limit and loop period.
Troubleshooting
- If Prow’s PR dashboard indicates that a PR is ready to merge and it appears to meet all merge requirements, but the PR is being ignored by Tide, you may have encountered a rare bug with GitHub’s search indexing. TLDR: If this is the problem, then any update to the PR (e.g. adding a comment) will make the PR visible to Tide again after a short delay. The longer explanation is that when GitHub’s background jobs for search indexing PRs fail, the search index becomes corrupted and the search API will have some incorrect belief about the affected PR, e.g. that it is missing a required label or still has a forbidden one. This causes the search query Tide uses to identify the mergeable PRs to incorrectly omit the PR. Since the same search engine is used by both the API and GitHub’s front end, you can confirm that the affected PR is not included in the query for mergeable PRs by using the appropriate “GitHub search link” from the expandable “Merge Requirements” section on the Tide status page. You can actually determine which particular index is corrupted by incrementally tweaking the query to remove requirements until the PR is included. Any update to the PR causes GitHub to kick off a new search indexing job in the background. Once it completes, the corrupted index should be fixed and Tide will be able to see the PR again in query results, allowing Tide to resume processing the PR. It appears any update to the PR is sufficient to trigger reindexing so we typically just leave a comment. Slack thread about an example of this.
Other resources
3.1.7.3 - PR Author's Guide to Tide
If you just want to figure out how to get your PR to merge this is the document for you!
Sources of Information
- The
tidestatus context at the bottom of your PR. The status either indicates that your PR is in the merge pool or explains why it is not in the merge pool. The ‘Details’ link will take you to either the Tide or PR dashboard.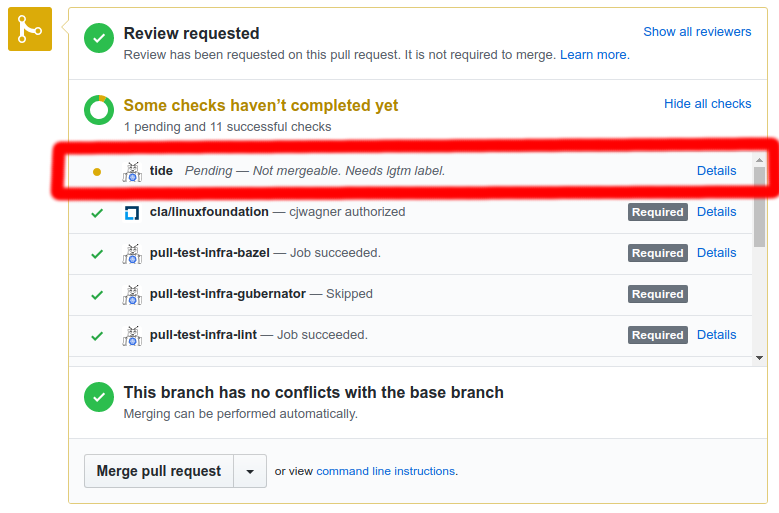
- The PR dashboard at “
<deck-url>/pr” where<deck-url>is something like “https://prow.k8s.io”. This dashboard shows a card for each of your PRs. Each card shows the current test results for the PR and the difference between the PR state and the merge criteria. K8s PR dashboard - The Tide dashboard at “
<deck-url>/tide”. This dashboard shows the state of every merge pool so that you can see what Tide is currently doing and what position your PR has in the retest queue. K8s Tide dashboard
Get your PR merged by asking these questions
“Is my PR in the merge pool?”
If the tide status at the bottom of your PR is successful (green) it is in the merge pool. If it is pending (yellow) it is not in the merge pool.
“Why is my PR not in the merge pool?”
First, if you just made a change to the PR, give Tide a minute or two to react. Tide syncs periodically (1m period default) so you shouldn’t expect to see immediate reactions.
To determine why your PR is not in the merge pool you have a couple options.
- The
tidestatus context at the bottom of your PR will describe at least one of the merge criteria that is not being met. The status has limited space for text so only a few failing criteria can typically be listed. To see all merge criteria that are not being met check out the PR dashboard. - The PR dashboard shows the difference between your PR’s state and the merge criteria so that you can easily see all criteria that are not being met and address them in any order or in parallel.
“My PR is in the merge pool, what now?”
Once your PR is in the merge pool it is queued for merge and will be automatically retested before merge if necessary. So typically your work is done! The one exception is if your PR fails a retest. This will cause the PR to be removed from the merge pool until it is fixed and is passing all the required tests again.
If you are eager for your PR to merge you can view all the PRs in the pool on the Tide dashboard to see where your PR is in the queue. Because we give older PRs (lower numbers) priority, it is possible for a PR’s position in the queue to increase.
Note: Batches of PRs are given priority over individual PRs so even if your PR is in the pool and has up-to-date tests it won’t merge while a batch is running because merging would update the base branch making the batch jobs stale before they complete. Similarly, whenever any other PR in the pool is merged, existing test results for your PR become stale and a retest becomes necessary before merge. However, your PR remains in the pool and will be automatically retested so this doesn’t require any action from you.
3.2 - Optional Components
3.2.1 - Branchprotector
branchprotector configures github branch protection according to a specified policy.
Policy configuration
Extend the primary prow config.yaml document to include a top-level
branch-protection key that looks like the following:
branch-protection:
orgs:
kubernetes:
repos:
test-infra:
# Protect all branches in kubernetes/test-infra
protect: true
# Always allow the org's oncall-team to push
restrictions:
teams: ["oncall-team"]
# Ensure that the extra-process-followed github status context passes.
# In addition, adds any required prow jobs (aka always_run: true)
required_status_checks:
contexts: ["extra-process-followed"]
presubmits:
kubernetes/test-infra:
- name: fancy-job-name
context: fancy-job-name
always_run: true
spec: # podspec that runs job
This config will:
- Enable protection for every branch in the
kubernetes/test-infrarepo. - Require
extra-process-followedandfancy-job-namestatus contexts to pass before allowing a merge- Although it will always allow
oncall-teamto merge, even if required contexts fail. - Note that
fancy-job-nameis pulled in automatically from thepresubmitsconfig for the repo, if one exists.
- Although it will always allow
Updating
- Send PR with
config.yamlchanges - Merge PR
- Done!
Make changes to the policy by modifying config.yaml in your favorite text
editor and then send out a PR. When the PR merges prow pushes the updated config
. The branchprotector applies the new policies the next time it runs (within
24hrs).
Advanced configuration
Fields
See branch_protection.go and GitHub’s protection api for a complete list of fields allowed
inside branch-protection and their meanings. The format is:
branch-protection:
# default policy here
orgs:
foo:
# this is the foo org policy
protect: true # enable protection
enforce_admins: true # rules apply to admins
required_linear_history: true # enforces a linear commit Git history
allow_force_pushes: true # permits force pushes to the protected branch
allow_deletions: true # allows deletion of the protected branch
required_pull_request_reviews:
dismiss_stale_reviews: false # automatically dismiss old reviews
dismissal_restrictions: # allow review dismissals
users:
- her
- him
teams:
- them
- those
require_code_owner_reviews: true # require a code owner approval
required_approving_review_count: 1 # number of approvals
required_status_checks:
strict: false # require pr branch to be up to date
contexts: # checks which must be green to merge
- foo
- bar
restrictions: # restrict who can push to the repo
apps:
- github-prow-app
users:
- her
- him
teams:
- them
- those
Scope
It is possible to define a policy at the
branch-protection, org, repo or branch level. For example:
branch-protection:
# Protect unless overridden
protect: true
# If protected, always require the cla status context
required_status_checks:
contexts: ["cla"]
orgs:
unprotected-org:
# Disable protection unless overridden (overrides parent setting of true)
protect: false
repos:
protected-repo:
protect: true
# Inherit protect-by-default config from parent
# If protected, always require the tested status context
required_status_checks:
contexts: ["tested"]
branches:
secure:
# Protect the secure branch (overrides inhereted parent setting of false)
protect: true
# Require the foo status context
required_status_checks:
contexts: ["foo"]
different-org:
# Inherits protect-by-default: true setting from above
The general rule for how to compute child values is:
- If the child value is
nullor missing, inherit the parent value. - Otherwise:
- List values (like
contexts), create a union of the parent and child lists. - For bool/int values (like
protect), the child value replaces the parent value.
- List values (like
So in the example above:
- The
securebranch inunprotected-org/protected-repo- enables protection (set a branch level)
- requires
footestedclastatus contexts (the latter two are appended by ancestors)
- All other branches in
unprotected-org/protected-repo- disable protection (inherited from org level)
- All branches in all other repos in
unprotected-org- disable protection (set at org level)
- All branches in all repos in
different-org- Enable protection (inherited from branch-protection level)
- Require the
clacontext to be green to merge (appended by parent)
Developer docs
Run unit tests
go test ./cmd/branchprotector
Run locally
go run ./cmd/branchprotector --help, which will tell you about the
current flags.
Do a dry run (which will not make any changes to github) with something like the following command:
go run ./cmd/branchprotector \
--config-path=/path/to/config.yaml \
--github-token-path=/path/to/my-github-token
This will say how the binary will actually change github if you add a
--confirm flag.
Deploy local changes to dev cluster
Run things like the following:
# Build image locally and push it to <YOUR_REGISTRY>
make push-single-image PROW_IMAGE=cmd/branchprotector REGISTRY=<YOUR_REGISTRY>
This will build an image with your local changes, and push it to <YOUR_REGISTRY>.
Or, if you just want to build an image but not to push, run the following:
# Build image locally
make build-single-image PROW_IMAGE=cmd/branchprotector
This will build an image with your local changes, without pushing it to anywhere.
Deploy cronjob to production
branchprotector image is automatically built as part of prow, see “How to update the cluster” for more details.
Branchprotector runs as a prow periodic job, for example ci-test-infra-branchprotector.
3.2.2 - Exporter
The prow-exporter exposes metrics about prow jobs while the metrics are not directly related to a specific prow-component.
Metrics
| Metric name | Metric type | Labels/tags |
|---|---|---|
| prow_job_labels | Gauge | job_name=<prow_job-name> job_namespace=<prow_job-namespace> job_agent=<prow_job-agent> label_PROW_JOB_LABEL_KEY=<PROW_JOB_LABEL_VALUE> |
| prow_job_annotations | Gauge | job_name=<prow_job-name> job_namespace=<prow_job-namespace> job_agent=<prow_job-agent> annotation_PROW_JOB_ANNOTATION_KEY=<PROW_JOB_ANNOTATION_VALUE> |
| prow_job_runtime_seconds | Histogram | job_name=<prow_job-name> job_namespace=<prow_job-namespace> type=<prow_job-type> last_state=<last-state> state=<state> org=<org> repo=<repo> base_ref=<base_ref> |
For example, the metric prow_job_labels is similar to kube_pod_labels defined
in kubernetes/kube-state-metrics.
A typical usage of prow_job_labels is to join
it with other metrics using a Prometheus matching operator.
Note that job_name is .spec.job
instead of .metadata.name as taken in kube_pod_labels.
The gauge value is always 1 because we have another metric prowjobs
for the number jobs by name. The metric here shows only the existence of such a job with the label set in the cluster.
3.2.3 - gcsupload
gcsupload uploads artifacts to cloud storage at a path resolved from the job configuration.
gcsupload can be configured by either passing in flags or by specifying a full set of options
as JSON in the $GCSUPLOAD_OPTIONS environment variable, which has the following form:
{
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
The path strategy field can be one of "legacy", "single", and "explicit". This field
determines how the organization and repository of the code under test is encoded into the GCS path
for the test artifacts:
| Strategy | Encoding |
|---|---|
"legacy" |
"" for the default org and repo, "org" for non-default repos in the default org, "org_repo" for repos in other orgs. |
"single" |
"" for the default org and repo, "org_repo" for all other repos. |
"explicit" |
"org_repo" for all repos. |
For historical reasons, the "legacy" or "single" strategies may already be in use for some;
however, for new deployments it is strongly advised to use the "explicit" strategy.
3.2.4 - Gerrit
Gerrit is a Prow-gerrit adapter for handling CI on gerrit workflows. It can poll gerrit changes from multiple gerrit instances, and trigger presubmits on Prow upon new patchsets on Gerrit changes, and postsubmits when Gerrit changes are merged.
Deployment Usage
When deploy the gerrit component, you need to specify --config-path to your prow config, and optionally
--job-config-path to your prowjob config if you have split them up.
Set --gerrit-projects to the gerrit projects you want to poll against.
Example:
If you want prow to interact with gerrit project foo and bar on instance gerrit-1.googlesource.com
and also project baz on instance gerrit-2.googlesource.com, then you can set:
--gerrit-projects=gerrit-1.googlesource.com=foo,bar
--gerrit-projects=gerrit-2.googlesource.com=baz
--cookiefile allows you to specify a git https cookie file to interact with your gerrit instances, leave
it empty for anonymous access to gerrit API.
--last-sync-fallback should point to a persistent volume that saves your last poll to gerrit.
Underlying infra
Also take a look at gerrit related packages for implementation details.
You might also want to deploy Crier which reports job results back to gerrit.
3.2.5 - HMAC
hmac is a tool to update the HMAC token, GitHub webhooks and HMAC secret
for the orgs/repos as per the managed_webhooks configuration changes in the Prow config file.
Prerequisites
To run this tool, you’ll need:
-
A github account that has admin permission to the orgs/repos.
-
A personal access token for the github account. Note the token must be granted
admin:repo_hookandadmin:org_hookscopes. -
Permissions to read&write the hmac secret in the Prow cluster.
How to run this tool
There are two ways to run this tool:
- Run it on local:
go run ./cmd/hmac \
--config-path=/path/to/prow/config \
--github-token-path=/path/to/oauth/secret \
--kubeconfig=/path/to/kubeconfig \
--kubeconfig-context=[context of the cluster to connect] \
--hmac-token-secret-name=[hmac secret name in Prow cluster] \
--hmac-token-key=[key of the hmac tokens in the secret] \
--hook-url http://an.ip.addr.ess/hook \
--dryrun=true # Remove it to actually update hmac tokens and webhooks
- Run it as a Prow job:
The recommended way to run this tool would be running it as a postsubmit job. One example Prow job configured for k8s Prow can be found here.
How it works
Given a new managed_webhooks configuration in the Prow core config file,
the tool can reconcile the current state of HMAC tokens, secrets and
webhooks to meet the new configuration.
Configuration example
Below is a typical example for the managed_webhooks configuration:
managed_webhooks:
# Whether this tool should respect the legacy global token.
# This has to be true if any of the managed repo/org is using the legacy global token that is manually created.
respect_legacy_global_token: true
# Controls whether org/repo invitation for prow bot should be automatically
# accepted or not. Only admin level invitations related to orgs and repos
# in the managed_webhooks config will be accepted and all other invitations
# will be left pending.
auto_accept_invitation: true
# Config for orgs and repos that have been onboarded to this Prow instance.
org_repo_config:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
Workflow example
Suppose the current org_repo_config in the managed_webhooks configuration is
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
There can be 3 scenarios to modify the configuration, as explained below:
Rotate an existing HMAC token
User updates the token_created_after for foo/baz to a later time, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2020-03-02T15:00:00Z
The hmac tool will generate a new HMAC token for the foo/baz repo,
add the new token to the secret, and update the webhook for the repo.
And after the update finishes, it will delete the old token.
Onboard a new repo
User adds a new repo foo/bax in the managed_webhooks configuration, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
foo/bax:
token_created_after: 2020-03-02T15:00:00Z
The hmac tool will generate an HMAC token for the foo/bax repo,
add the token to the secret, and add the webhook for the repo.
Remove an existing repo
User deletes the repo foo/baz from the managed_webhooks configuration, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
The hmac tool will delete the HMAC token for the foo/baz repo from
the secret, and delete the corresponding webhook for this repo.
Note the 3 types of config changes can happen together, and
hmactool is able to handle all the changes in one single run.
3.2.6 - jenkins-operator
jenkins-operator is a controller that enables Prow to use Jenkins
as a backend for running jobs.
Jenkins configuration
A Jenkins master needs to be provided via --jenkins-url in order for
the operator to make requests to. By default, --dry-run is set to true
so the operator will not make any mutating requests to Jenkins, GitHub,
and Kubernetes, but you most probably want to set it to false.
The Jenkins operator expects to read the Prow configuration by default
in /etc/config/config.yaml which can be configured with --config-path.
The following stanza is config that can be optionally set in the Prow config file:
jenkins_operators:
- max_concurrency: 150
max_goroutines: 20
job_url_template: 'https://storage-for-logs/{{if eq .Spec.Type "presubmit"}}pr-logs/pull{{else if eq .Spec.Type "batch"}}pr-logs/pull{{else}}logs{{end}}{{if ne .Spec.Refs.Repo "origin"}}/{{.Spec.Refs.Org}}_{{.Spec.Refs.Repo}}{{end}}{{if eq .Spec.Type "presubmit"}}/{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}{{else if eq .Spec.Type "batch"}}/batch{{end}}/{{.Spec.Job}}/{{.Status.BuildID}}/'
report_template: '[Full PR test history](https://pr-history/{{if ne .Spec.Refs.Repo "origin"}}{{.Spec.Refs.Org}}_{{.Spec.Refs.Repo}}/{{end}}{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}).'
max_concurrencyis the maximum number of Jenkins builds that can run in parallel, otherwise the operator is not going to start new builds. Defaults to 0, which means no limit.max_goroutinesis the maximum number of goroutines that the operator will spin up to handle all Jenkins builds. Defaulted to 20.job_url_templateis a Golang-templated URL that shows up in the Details button next to the GitHub job status context. A ProwJob is provided as input to the template.report_templateis a Golang-templated message that shows up in GitHub in case of a job failure. A ProwJob is provided as input to the template.
Security
Various flavors of authentication are supported:
- basic auth, using
--jenkins-userand--jenkins-token-file. - OpenShift bearer token auth, using
--jenkins-bearer-token-file. - certificate-based auth, using
--cert-file,--key-file, and optionally--ca-cert-file.
Basic auth and bearer token are mutually exclusive options whereas cert-based auth is complementary to both of them.
If CSRF protection is enabled in Jenkins, --csrf-protect=true
needs to be used on the operator’s side to allow Prow to work correctly.
Logs
Apart from a controller, the Jenkins operator also runs a http server to serve Jenkins logs. You can configure the Prow frontend to show Jenkins logs with the following Prow config:
deck:
external_agent_logs:
- agent: jenkins
url_template: 'http://jenkins-operator/job/{{.Spec.Job}}/{{.Status.BuildID}}/consoleText'
Deck uses url_template to contact jenkins-operator when a user
clicks the Build log button of a Jenkins job (agent: jenkins).
jenkins-operator forwards the request to Jenkins and serves back
the response.
NOTE: Deck will display the Build log button on the main page when the agent is not kubernetes
regardless the external agent log was configured on the server side. Deck has no way to know if the server
side configuration is consistent when rendering jobs on the main page.
Job configuration
Below follows the Prow configuration for a Jenkins job:
presubmits:
org/repo:
- name: pull-request-unit
agent: jenkins
always_run: true
context: ci/prow/unit
rerun_command: "/test unit"
trigger: "((?m)^/test( all| unit),?(\\s+|$))"
You can read more about the different types of Prow jobs elsewhere.
What is interesting for us here is the agent field which needs to
be set to jenkins in order for jobs to be dispatched to Jenkins and
name which is the name of the job inside Jenkins.
The following parameters must be added within each Jenkins job:
BUILD_IDPROW_JOB_ID
Sharding
Sharding of Jenkins jobs is supported via Kubernetes labels and label selectors. This enables Prow to work with multiple Jenkins masters. Three places need to be configured in order to use sharding:
--label-selectorin the Jenkins operator.label_selectorinjenkins_operatorsin the Prow config.labelsin the job config.
For example, one would set the following options:
--label-selector=master=jenkins-masterin a Jenkins operator.
This option forces the operator to list all ProwJobs with master=jenkins-master.
label_selector: master=jenkins-masterin the Prow config.
jenkins_operators:
- label_selector: master=jenkins-master
max_concurrency: 150
max_goroutines: 20
jenkins_operators in the Prow config can be read by multiple running operators
and based on label_selector, each operator knows which config stanza does it
need to use. Thus, --label-selector and label_selector need to match exactly.
labels: jenkins-masterin the job config.
presubmits:
org/repo:
- name: pull-request-unit
agent: jenkins
labels:
master: jenkins-master
always_run: true
context: ci/prow/unit
rerun_command: "/test unit"
trigger: "((?m)^/test( all| unit),?(\\s+|$))"
Labels in the job config are set in ProwJobs during their creation.
Kubernetes client
The Jenkins operator acts as a Kubernetes client since it manages ProwJobs backed by Jenkins builds. It is expected to run as a pod inside a Kubernetes cluster and so it uses the in-cluster client config.
GitHub integration
The operator needs to talk to GitHub for updating commit statuses and adding comments about failed tests. Note that this functionality may potentially move into its own service, then the Jenkins operator will not need to contact the GitHub API. The required options are already defaulted:
github-token-pathset to/etc/github/oauth. This is the GitHub bot oauth token that is used for updating job statuses and adding comments in GitHub.github-endpointset tohttps://api.github.com.
Prometheus support
The following Prometheus metrics are exposed by the operator:
jenkins_requestsis the number of Jenkins requests made.verbis the type of request (GET,POST)handleris the path of the request, usually containing a job name (eg.job/test-pull-request-unit).codeis the status code of the request (200,404, etc.).
jenkins_request_retriesis the number of Jenkins request retries made.jenkins_request_latencyis the time for a request to roundtrip between the operator and Jenkins.resync_period_secondsis the time the operator takes to complete one reconciliation loop.prowjobsis the number of Jenkins prowjobs in the system.job_nameis the name of the job.typeis the type of the prowjob: presubmit, postsubmit, periodic, batchstateis the state of the prowjob: triggered, pending, success, failure, aborted, error
If a push gateway needs to be used it can be configured in the Prow config:
push_gateway:
endpoint: http://prometheus-push-gateway
interval: 1m
3.2.7 - status-reconciler
status-reconciler ensures that changes to blocking presubmits in Prow configuration while PRs are
in flight do not cause those PRs to get stuck.
When the set of blocking presubmits changes for a repository, one of three cases occurs:
- a new blocking presubmit exists and should be triggered for every trusted pull request in flight
- an existing blocking presubmit is removed and should have its' status retired
- an existing blocking presubmit is renamed and should have its' status migrated
The status-reconciler watches the job configuration for Prow and ensures that the above actions
are taken as necessary.
To exclude repos from being reconciled, passing flag --denylist, this can be done repeatedly.
This is useful when moving a repo from prow instance A to prow instance B, while unwinding jobs from
prow instance A, the jobs are not expected to be blindly lablled succeed by prow instance A.
Note that status-reconciler is edge driven (not level driven) so it can’t be used retrospectively.
To update statuses that were stale before deploying status-reconciler,
you can use the migratestatus tool.
3.2.8 - tot
This is a placeholder page. Some contents needs to be filled.
3.2.8.1 - fallbackcheck
Ensure your GCS bucket layout is what tot expects to use. Useful when you want to transition
from versioning your GCS buckets away from Jenkins build numbers to build numbers vended
by prow.
fallbackcheck checks the existence of latest-build.txt files as per the documented GCS layout.
It ignores jobs that have no GCS buckets.
Install
go get sigs.k8s.io/prow/cmd/tot/fallbackcheck
Run
fallbackcheck -bucket GCS_BUCKET -prow-url LIVE_DECK_DEPLOYMENT
For example:
fallbackcheck -bucket https://gcsweb-ci.svc.ci.openshift.org/gcs/origin-ci-test/ -prow-url https://deck-ci.svc.ci.openshift.org/
3.2.9 - Gangway (Prow API)
Architecture
See the design doc.
Gangway uses gRPC to serve several endpoints. These can be seen in the
gangway.proto file, which describes the gRPC endpoints. The
proto describes the interface at a high level, and is converted into low-level
Golang types into gangway.pb.go and
gangway_grpc.pb.go. These low-level Golang types are
then used in the gangway.go file to implement the high-level
intent of the proto file.
As Gangway only understands gRPC natively, if you want to use a REST client against it you must deploy Gangway. For example, on GKE you can use Cloud Endpoints and deploy Gangway behind a reverse proxy called “ESPv2”. This ESPv2 container will forward HTTP requests made to it to the equivalent gRPC endpoint in Gangway and back again.
Configuration setup
Server-side configuration
Gangway has its own security check to see whether the client is allowed to, for
example, trigger the job that it wants to trigger (we don’t want to let any
random client trigger any Prow Job that Prow knows about). In the central Prow
config under the gangway section, prospective Gangway users can list
themselves in there. For an example, see the section filled out for Gangway’s
own integration tests and search for
allowed_jobs_filters.
Client-side configuration
The table below lists the supported endpoints.
| Endpoint | Description |
|---|---|
| CreateJobExecution | Triggers a new Prow Job. |
| GetJobExecution | Get the status of a Prow Job. |
| ListJobExecutions | List all Prow Jobs that match the query. |
See gangway.proto and the Gangway Google
client.
Tutorial
See the example.
3.2.10 - Sub
Sub is a Prow component that can trigger new Prow jobs (PJs) using Pub/Sub messages. The message does not need to have the full PJ defined; instead you just need to have the job name and some other key pieces of information (more on this below). The rest of the data needed to create a full-blown PJ is derived from the main Prow configuration (or inrepoconfig).
Deployment Usage
Sub can listen to Pub/Sub subscriptions (known as “pull subscriptions”).
When deploy the sub component, you need to specify --config-path to your prow config, and optionally
--job-config-path to your prowjob config if you have split them up.
Notable options:
--dry-run: Dry run for testing. Uses API tokens but does not mutate.--grace-period: On shutdown, try to handle remaining events for the specified duration.--port: On shutdown, try to handle remaining events for the specified duration.--github-app-idand--github-app-private-key-path=/etc/github/cert: Used to authenticate to GitHub for cloning operations as a GitHub app. Mutually exclusive with--cookiefile.--cookiefile: Used to authenticate git when cloning fromhttps://...URLs. Seehttp.cookieFileinman git-config.--in-repo-config-cache-size: Used to cache Prow configurations fetched from inrepoconfig-enabled repos.
flowchart TD
classDef yellow fill:#ff0
classDef cyan fill:#0ff
classDef pink fill:#f99
subgraph Service Cluster
PCM[Prow Controller Manager]:::cyan
Prowjob:::yellow
subgraph Sub
staticconfig["Static Config
(/etc/job-config)"]
inrepoconfig["Inrepoconfig
(git clone <inrepoconfig>)"]
YesOrNo{"Is my-prow-job-name
in the config?"}
Yes
No
end
end
subgraph Build Cluster
Pod:::yellow
end
subgraph GCP Project
subgraph Pub/Sub
Topic
Subscription
end
end
subgraph Message
Payload["{"data":
{"name":"my-prow-job-name",
"attributes":{"prow.k8s.io/pubsub.EventType": "..."},
"data": ...,
..."]
end
Message --> Topic --> Subscription --> Sub --> |Pulls| Subscription
staticconfig --> YesOrNo
inrepoconfig -.-> YesOrNo
YesOrNo --> Yes --> |Create| Prowjob --> PCM --> |Create| Pod
YesOrNo --> No --> |Report failure| Topic
Sending a Pub/Sub Message
Pub/Sub has a generic PubsubMessage type that has the following JSON structure:
{
"data": string,
"attributes": {
string: string,
...
},
"messageId": string,
"publishTime": string,
"orderingKey": string
}
The Prow-specific information is encoded as JSON as the string value of the data key.
Pull Server
All pull subscriptions need to be defined in Prow Configuration:
pubsub_subscriptions:
"gcp-project-01":
- "subscription-01"
- "subscription-02"
- "subscription-03"
"gcp-project-02":
- "subscription-01"
- "subscription-02"
- "subscription-03"
Sub must be running with GOOGLE_APPLICATION_CREDENTIALS environment variable pointing to the service
account credentials JSON file. The service account used must have the right permission on the
subscriptions (Pub/Sub Subscriber, and Pub/Sub Editor).
More information at https://cloud.google.com/pubsub/docs/access-control.
Periodic Prow Jobs
When creating your Pub/Sub message, for the attributes field, add a key
prow.k8s.io/pubsub.EventType with value
prow.k8s.io/pubsub.PeriodicProwJobEvent. Then for the data field, use the
following JSON as the value:
{
"name":"my-periodic-job",
"envs":{
"GIT_BRANCH":"v.1.2",
"MY_ENV":"overwrite"
},
"labels":{
"myLabel":"myValue",
},
"annotations":{
# GCP project where Prow Job statuses are published by Prow. Must also
# provide "prow.k8s.io/pubsub.topic" to take effect.
#
# It's highly recommended to configure this even if prowjobs are monitored
# by other means, because this is also where errors are reported when the
# jobs are failed to be triggered.
"prow.k8s.io/pubsub.project":"myProject",
# Unique run ID.
"prow.k8s.io/pubsub.runID":"asdfasdfasdf",
# GCP pubsub topic where Prow Job statuses are published by Prow. Must be a
# different topic from where this payload is published to.
"prow.k8s.io/pubsub.topic":"myTopic"
}
}
Note: the # lines are comments for purposes of explanation in this doc; JSON
does not permit comments so make sure to remove them in your actual payload.
The above payload will ask Prow to find and trigger the periodic job named
my-periodic-job, and add/overwrite the annotations and environment variables
on top of the job’s default annotations. The prow.k8s.io/pubsub.* annotations
are used to publish job statuses.
Note: periodic jobs always clone source code from ref (a branch) instead of a specific SHA. If you need to trigger a job based on a specific SHA you can use a postsubmit job instead.
Postsubmit Prow Jobs
Triggering presubmit job is similar to periodic jobs. Two things to change:
- instead of an attributes with key
prow.k8s.io/pubsub.EventTypeand valueprow.k8s.io/pubsub.PeriodicProwJobEvent, replace the value withprow.k8s.io/pubsub.PostsubmitProwJobEvent - requires setting
refsinstructing postsubmit jobs how to clone source code:
{
# Common fields as above
"name":"my-postsubmit-job",
"envs":{...},
"labels":{...},
"annotations":{...},
"refs":{
"org": "org-a",
"repo": "repo-b",
"base_ref": "main",
"base_sha": "abc123"
}
}
This will start postsubmit job my-postsubmit-job, clones source code from base_ref
at base_sha.
(There are more fields can be supplied, see full documentation)
Presubmit Prow Jobs
Triggering presubmit jobs is similar to postsubmit jobs. Two things to change:
- instead of an
attributeswith keyprow.k8s.io/pubsub.EventTypeand valueprow.k8s.io/pubsub.PostsubmitProwJobEvent, replace the value withprow.k8s.io/pubsub.PresubmitProwJobEvent - for the
refsfield, additionally supply apullsfield, like this:
{
# Common fields as above
"name":"my-presubmit-job",
"envs":{...},
"labels":{...},
"annotations":{...},
"refs":{
"org": "org-a",
"repo": "repo-b",
"base_ref": "main",
"base_sha": "abc123",
"pulls": [
{
"sha": "def456"
}
]
}
}
This will start presubmit job my-presubmit-job, clones source code like pull requests
defined under pulls, which merges to base_ref at base_sha.
(There are more fields that can be supplied, see full
documentation.
For example, if you want the job to be reported on the PR, add number field
right next to sha)
Gerrit Presubmits and Postsubmits
Gerrit presubmit and postsubmit jobs require some additional labels and annotations to be specified in the pubsub payload if you wish for them to report results back to the Gerrit change. Specifically the following annotations must be supplied (values are examples):
annotations:
prow.k8s.io/gerrit-id: my-repo~master~I79eee198f020c2ff23d49dbe4d2b2ef7cdc4091b
prow.k8s.io/gerrit-instance: https://my-project-review.googlesource.com
labels:
prow.k8s.io/gerrit-patchset: "4"
prow.k8s.io/gerrit-revision: 2b8cafaab9bd3a829a6bdaa819a18f908bc677ca
3.3 - CLI Tools
3.3.1 - checkconfig
checkconfig loads the Prow configuration given with --config-path,
--job-config-path and --plugin-config in order to validate it.
Use checkconfig as a pre-submit for any repository holding Prow
configuration to ensure that check-ins do not break anything.
3.3.2 - config-bootstrapper
config-bootstrapper is used to bootstrap a configuration that would be incrementally updated by the
config-updater Prow plugin.
When a set of configurations do not exist (for example, on a clean redeployment or in a disaster recovery situation), the config-updater plugin is not useful as it can only upload incremental updates. This tool is meant to be used in those situations to set up the config to the correct base state and hand off ownership to the plugin for updates.
Provide the config-bootstrapper with the latest state of the Prow configuration (plugins.yaml, config.yaml, any job configuration files) to boot-strap with the latest configuration.
Sample usage:
./config-bootstrapper \
--dry-run=false \
--source-path=. \
--config-path=prowconfig/config.yaml \
--plugin-config=prowconfig/plugins.yaml \
--job-config-path=prowconfig/jobs
3.3.3 - generic-autobumper
This tool automates the version upgrading of images such as the prow.k8s.io Prow deployment. Its workflow is:
- Given a local git repo containing the manifests of Prow component deployment, e.g., /config/prow/cluster folder in this repo.
- Find out the most recent tags of given prefixes in
gcr.ioregistry and modify the yaml files with them. git-committhe change, push it to the remote repo, and create/update a PR, e.g., test-infra/pull/14249, for the change.
The cluster admins can upgrade the version of images by approving the PR.
Define Prow jobs to utilize this tool:
- Periodic job for the above workflow: Periodically generate PRs for bumping the version, e.g., ci-test-infra-autobump-prow.
- Postsubmit job for auto-deployment: In order to make the changes effective in Prow-cluster,
a postsubmit job, e.g.,
post-test-infra-deploy-prowfor prow.k8s.io is defined for deploying the yaml files.
Requirement
We need to fulfil those requirements to use this tool:
-
a “committable” local repo, i.e.,
git-commitcommand can be executed successfully, e.g.,git-configis set up correctly. This can be achieved by clone the repo byextra_refs, e.g.,extra_refs: - org: kubernetes repo: test-infra base_ref: master -
a GitHub token which has permissions to be used by this tool to push changes and create PRs against the remote repo.
-
a yaml config file that specifies the follwing information passed in with the flag -config=FILEPATH:
-
For info about what should go in the config look at the documentation for the Options here and look at the example below.
e.g.,
gitHubLogin: "k8s-ci-robot"
gitHubToken: "/etc/github-token/oauth"
gitName: "Kubernetes Prow Robot"
gitEmail: "k8s.ci.robot@gmail.com"
onCallAddress: "https://storage.googleapis.com/kubernetes-jenkins/oncall.json"
skipPullRequest: false
gitHubOrg: "kubernetes"
gitHubRepo: "test-infra"
remoteName: "test-infra"
upstreamURLBase: "https://raw.githubusercontent.com/kubernetes/test-infra/master"
includedConfigPaths:
- "."
excludedConfigPaths:
- "config/prow-staging"
extraFiles:
- "config/jobs/kubernetes/kops/build-grid.py"
- "config/jobs/kubernetes/kops/build-pipeline.py"
- "releng/generate_tests.py"
- "images/kubekins-e2e/Dockerfile"
targetVersion: "latest"
prefixes:
- name: "Prow"
prefix: "gcr.io/k8s-prow/"
refConfigFile: "config/prow/cluster/deck_deployment.yaml"
stagingRefConfigFile: "config/prow-staging/cluster/deck_deployment.yaml"
repo: "https://github.com/kubernetes/test-infra"
summarise: true
consistentImages: true
- name: "Boskos"
prefix: "gcr.io/k8s-staging-boskos/"
refConfigFile: "config/prow/cluster/build/boskos.yaml"
stagingRefConfigFile: "config/prow-staging/cluster/boskos.yaml"
repo: "https://github.com/kubernetes-sigs/boskos"
summarise: false
consistentImages: true
- name: "Prow-Test-Images"
prefix: "gcr.io/k8s-testimages/"
repo: "https://github.com/kubernetes/test-infra"
summarise: false
consistentImages: false
3.3.4 - invitations-accepter
The invitations-accepter tool approves all pending repository invitations.
Usage
example:
invitations-accepter --dry-run=false --github-token-path=/etc/github/oauth
using with GitHub Apps
invitations-accepter --dry-run=false --github-app-id=12345 --github-app-private-key-path=/etc/github/cert
3.3.5 - mkpj
This is a placeholder page. Some contents needs to be filled.
3.3.6 - mkpod
This is a placeholder page. Some contents needs to be filled.
3.3.7 - Peribolos
Peribolos allows the org settings, teams and memberships to be declared in a yaml file. GitHub is then updated to match the declared configuration.
See the kubernetes/org repo, in particular the merge and update.sh parts of that repo for this tool in action.
Peribolos was the subject of a KubeCon talk: How Kubernetes Uses GitOps to Manage GitHub Communities at Scale
Etymology
A peribolos is a wall that encloses a court in Greek/Roman architecture.
Org configuration
Extend the primary prow config.yaml document to include a top-level orgs key that looks like the following:
orgs:
this-org:
# org settings
company: foo
email: foo
name: foo
description: foo
has_organization_projects: true
has_repository_projects: true
default_repository_permission: read
members_can_create_repositories: false
# org member settings
members:
- anne
- bob
admins:
- carl
# team settings
teams:
node:
# team config
description: people working on node backend
privacy: closed
previously:
- backend # If a backend team exists, rename it to node
# team members
members:
- anne
maintainers:
- jane
repos: # Ensure the team has the following permissions levels on repos in the org
some-repo: admin
other-repo: read
another-team:
...
...
that-org:
...
This config will:
- Ensure the org settings match the following:
- Set the company, email, name and descriptions fields for the org to foo
- Allow projects to be created at the org and repo levels
- Give everyone read access to repos by default
- Disallow members from creating repositories
- Ensure the following memberships exist:
- anne and bob are members, carl is an admin
- Configure the node and another-team in the following manner:
- Set node’s description and privacy setting.
- Rename the backend team to node
- Add anne as a member and jane as a maintainer to node
- Similar things for another-team (details elided)
- Ensure that the team has admin rights to
some-repo, read access toother-repoand no other privileges
Note that any fields missing from the config will not be managed by peribolos. So if description is missing from the org setting, the current value will remain.
For more details please see GitHub documentation around edit org, update org membership, edit team, update team membership.
Initial seed
Peribolos can dump the current configuration to an org. For example you could dump the kubernetes org do the following:
$ go run ./cmd/peribolos --dump kubernetes-sigs --github-token-path ~/github-token | tee ~/current.yaml
...
INFO: Build completed successfully, 1 total action
...
{"client":"github","component":"peribolos","level":"info","msg":"GetOrg(kubernetes-sigs)","time":"2018-09-28T13:17:42-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, admin)","time":"2018-09-28T13:17:42-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, member)","time":"2018-09-28T13:17:43-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeams(kubernetes-sigs)","time":"2018-09-28T13:17:45-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeamMembers(2671356, maintainer)","time":"2018-09-28T13:17:46-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeamMembers(2671356, member)","time":"2018-09-28T13:17:46-07:00"}
...
admins:
- calebamiles
- cblecker
- etc
billing_email: secret@example.com
company: ""
default_repository_permission: read
description: Org for Kubernetes SIG-related work
email: ""
has_organization_projects: true
has_repository_projects: true
location: ""
members:
- ameukam
- amwat
- ant31
- etc
teams:
application-admins:
description: admin access to application
maintainers:
- kow3ns
members:
- mattfarina
- prydonius
privacy: closed
architecture-tracking-admins:
description: admin permission for architecture-tracking
maintainers:
- jdumars
- bgrant0607
privacy: closed
# etc
Open ~/current.yaml and then delete any metadata you don’t want peribolos to manage (such as billing_email, or all the teams, etc).
Apply this config in dry-run mode to see what would happen (hopefully nothing since you just created it):
$ go run ./cmd/peribolos --config-path ~/current.yaml --github-token-path ~/github-token # --confirm
{"client":"github","component":"peribolos","level":"info","msg":"GetOrg(kubernetes-sigs)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgInvitations(kubernetes-sigs)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, admin)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, member)","time":"2018-09-27T23:07:14Z"}
...
Settings
In order to mitigate the chance of applying erroneous configs, the peribolos binary includes a few safety checks:
--required-admins=- a list of people who must be configured as admins in order to accept the config (defaults to empty list)--min-admins=5- the config must specify at least this many admins--require-self=true- require the bot applying the config to be an admin.
These flags are designed to ensure that any problems can be corrected by rerunning the tool with a fixed config and/or binary.
--maximum-removal-delta=0.25- reject a config that deletes more than 25% of the current memberships.
This flag is designed to protect against typos in the configuration which might cause massive, unwanted deletions. Raising this value to 1.0 will allow deleting everyone, and reducing it to 0.0 will prevent any deletions.
--confirm=false- no github mutations will be made until this flag is true. It is safe to run the binary without this flag. It will print what it would do, without actually making any changes.
See go run ./cmd/peribolos --help for the full and current list of settings that can be configured with flags.
3.3.8 - Phaino
Run prowjobs on your local workstation with phaino.
Plato believed that ideas and forms are the ultimate truth, whereas we only see the imperfect physical appearances of those idea.
He linkens this in his Allegory of the Cave to someone living in a cave who can only see the shadows projected on the wall from objects passing in front of a fire.
Phaino is act of making those imperfect shadows appear.
Phaino shares a prefix with Pharos, meaning lighthouse and in particular the ancient one in Alexandria.
Usage
Usage:
# Use a job from deck
go run ./cmd/phaino $URL # or /path/to/prowjob.yaml
# Use mkpj to create the job
go run ./cmd/mkpj --config-path=/path/to/prow/config.yaml --job-config-path=/path/to/prow/job/configs --job=foo > /tmp/foo
go run ./cmd/phaino /tmp/foo
Phaino is an interactive utility; it will prompt you for a local copy of any secrets or volumes that the Prow Job may require.
Common options
--grace=5mcontrols how long to wait for interrupted jobs before terminating--printthe command that runs each job without running it--privilegedjobs are allowed to run instead of rejected--timeout=10mcontrols how long to allow jobs to run before interrupting them--code-mount-path=/gochanges the path where code is mounted in the container--skip-volume-mounts=volume1,volume2includes the unwanted volume mounts that are defined in the job spec--extra-volume-mounts=/go/src/sigs.k8s.io/prow=/Users/xyz/k8s-test-infraincludes the extra volume mounts needed for the container. Key is the mount path and value is the local path--skip-envs=env1,env2includes the unwanted env vars that are defined in the job spec--extra-envs=env1=val1,env2=val2includes the extra env vars needed for the container--use-local-gcloud-credentialscontrols whether to use the same gcloud credentials as local or not--use-local-kubeconfigcontrols whether to use the same kubeconfig as local or not
Common options usage scenarios
Phaino is smart at prompting for where repo is located, volume mounts etc., if it’s desired to save the prompts, use the following tricks instead:
-
If the repo needs to be cloned under GOPATH, use:
--code-mount-path==/whatever/go/src # Controls where source code is mounted in container --extra-volume-mounts=/whatever/go/src/sigs.k8s.io/prow=/Users/xyz/k8s-test-infra
-
If job requires mounting kubeconfig, assume the mount is named
kubeconfig,use:--use-local-kubeconfig --skip-volume-mounts=kubeconfig -
If job requires mounting gcloud default credentials, assume the mount is named
service-account,use:--use-local-gcloud-credentials --skip-volume-mounts=service-account -
If job requires mounting something else like
name:foo; mountPath: /bar,use:--extra-volume-mounts=/bar=/Users/xyz/local/bar --skip-volume-mounts=foo -
If job requires env vars,use:
--extra-envs=env1=val1,env2=val2
See go run ./cmd/phaino --help for full option list.
Usage examples
URL example
- Go to your deck deployment
- Pick a job and click the rerun icon on the left
- Copy the URL (something like
https://prow.k8s.io/rerun?prowjob=d08f1ca5-5d63-11e9-ab62-0a580a6c1281) - Paste it as a phaino arg
go run ./cmd/phaino https://prow.k8s.io/rerun?prowjob=d08f1ca5-5d63-11e9-ab62-0a580a6c1281- Alternatively
go run ./cmd/phaino <(curl $URL)
Configuration example
- Use
mkpjto create the job and pipe this tophaino-
For prow.k8s.io jobs use
//config:mkpjgo run ./config:mkpj --job=pull-test-infra-bazel > /tmp/foo go run ./cmd/phaino /tmp/foo -
Other deployments will need to clone that rule and/or pass in extra flags:
go run ./cmd/mkpj --config-path=/my/config.yaml --job=my-job go run ./cmd/phaino /tmp/foo
-
3.3.9 - Phony
phony sends fake GitHub webhooks.
Running a GitHub event manager
phony is most commonly used for testing hook and its plugins, but can be used for testing any externally exposed service configured to receive GitHub events (external plugins).
To get an idea of phony’s behavior, start a local instance of hook with
this:
go run cmd/hook/main.go \
--config-path=config/prow/config.yaml \
--plugin-config=config/prow/plugins.yaml \
--hmac-secret-file=path/to/hmac \
--github-token-path=path/to/github-token
# Note:
# --hmac-secret-file is required for running locally, use the same hmac token for phony below
Usage
Once you have a running server that manages github webhook events, generate an
hmac token (same process as in prow), and point a phony pull
request event at it with the following:
phony --help
Usage of ./phony:
-address string
Where to send the fake hook. (default "http://localhost:8888/hook")
-event string
Type of event to send, such as pull_request. (default "ping")
-hmac string
HMAC token to sign payload with. (default "abcde12345")
-payload string
File to send as payload. If unspecified, sends "{}".
If you are testing hook and successfully sent the webhook from phony, you should see a log from hook resembling the following:
{"author":"","component":"hook","event-GUID":"GUID","event-type":"pull_request","level":"info","msg":"Pull request .","org":"","pr":0,"repo":"","time":"2018-05-29T11:38:57-07:00","url":""}
A list of supported events can be found in the GitHub API Docs. Some example event payloads can be found in the examples directory.
3.3.10 - tackle
Prow’s tackle utility walks you through deploying a new instance of prow
in a couple of minutes, try it out!
Installing tackle
Tackle at this point in time needs to be built from source. The following steps will walk you through the process:
- Clone the
test-infrarepository:
git clone git@github.com:kubernetes/test-infra.git
- Build
tackle(This requires a working go installation on your system)
cd test-infra/prow/cmd/tackle && go build -o tackle
- Optionally move
tackleto your$PATH
sudo mv tackle /usr/sbin/tackle
Deploying prow
Note: Creating a cluster using the tackle utility assumes you
have the gcloud application in your $PATH and are logged in. If you are
doing this on another cloud skip to the Manual deployment below.
Installing Prow using tackle will help you through the following steps:
- Choosing a kubectl context (or creating a cluster on GCP / getting its credentials if necessary)
- Deploying prow into that cluster
- Configuring GitHub to send prow webhooks for your repos. This is where you’ll provide the absolute
/path/to/github/token
To install prow run the following and follow the on-screen instructions:
- Run
tackle:
tackle
- Once your cluster is created, you’ll get a prompt to apply a
starter.yaml. Before you do that open another terminal and apply the prow CRDs using:
kubectl apply --server-side=true -f https://raw.githubusercontent.com/kubernetes/test-infra/master/config/prow/cluster/prowjob-crd/prowjob_customresourcedefinition.yaml
-
After that specify the
starter.yamlyou want to use (please make sure to replace the values mentioned here). Once that is done some pods still won’t be in theRunningstate because we haven’t created the secret containing the credentials needed for our GCS bucket. To do that follow the steps in Configure a GCS bucket. -
Once that is done,
tackleshould show you the URL where you can access the prow dashboard. To use it with your repositories head over to the settings of the GitHub app you created and there under webhook secret, supply the HMAC token you specified in thestarter.yaml. -
Once that is done, install the GitHub app on the repositories you want (this is only needed if you ran
tacklewith the--skip-githubflag) and you should now be able to use Prow :)
See the Next Steps section after running this utility.
3.4 - Pod Utilities
Pod utilities are small, focused Go programs used by plank to decorate user-provided PodSpecs
in order to increase the ease of integration for new jobs into the entire CI infrastructure. The
utilities today wrap the execution of the test code to ensure that the tests run against correct
versions of the source code, that test commands run in the appropriate environment and that output
from the test (in the form of status, logs and artifacts) is correctly uploaded to the cloud.
These utilities are integrated into a test run by adding InitContainers and sidecar Containers
to the user-provided PodSpec, as well as by overwriting the Container entrypoint for the test
Container provided by the user. The following utilities exist today:
clonerefs: clones source code under testinitupload: records the beginning of a test in cloud storage and reports the status of the clone operationsentrypoint: is injected into the testContainer, wraps the test code to capture logs and exit statussidecar: runs alongside the testContainer, uploads status, logs and test artifacts to cloud storage once the test is finished
Why use Pod Utilities?
Writing a ProwJob that uses the Pod Utilities is much easier than writing one that doesn’t because the Pod Utilities will transparently handle many of the tasks the job would otherwise need to do in order to prepare its environment and output more than pass/fail. Historically, this was achieved by wrapping every job with a bootstrap.py script that handled cloning source code, preparing the test environment, and uploading job metadata, logs, and artifacts. This was cumbersome to configure and required every job to be wrapped with the script in the job image. The pod utilities achieve the same goals with less configuration and much simpler job images that are easier to develop and less coupled to Prow.
Writing a ProwJob that uses Pod Utilities
What the test container can expect
Example test container script:
pwd # my repo root
ls path/to/file/in/my/repo.txt # access repo file
ls ../other-repo # access repo file in another repo
echo success > ${ARTIFACTS}/results.txt # result info that will be uploaded to GCS.
# logs, and job metadata are automatically uploaded.
More specifically, a ProwJob using the Pod Utilities can expect the following:
- Source Code - Jobs can expect to begin execution with their working
directory set as the root of the checked out repo. The commit that is checked
out depends on the type of job:
presubmitjobs will have the relevant PR checked out and merged with the base branch.postsubmitjobs will have the upstream commit that triggered the job checked out.periodicjobs will have the working directory set to the root of the repo specified by the first ref inextra_refs(if specified). See theextra_refsfield if you need to clone more than one repo.
- Metadata and Logs - Jobs can expect metadata about the job to be uploaded before the job starts, and additional metadata and logs to be uploaded when the job completes.
- Artifact Directory - Jobs can expect an
$ARTIFACTSenvironment variable to be specified. It indicates an existent directory where job artifacts can be dumped for automatic upload to GCS upon job completion.
How to configure
In order to use the pod utilities, you will need to configure plank with some settings first. See plank’s README for reference.
ProwJobs may request Pod Utility decoration by setting decorate: true in their config.
Example ProwJob configuration:
- name: pull-job
always_run: true
decorate: true
spec:
containers:
- image: alpine
command:
- "echo"
args:
- "The artifacts dir is $(ARTIFACTS)"
In addition to normal ProwJob configuration, ProwJobs using the Pod Utilities
must specify the command field in the container specification instead of using
the Dockerfile’s ENTRYPOINT directive. Note that the command field is a string
array not just a string. It should point to the test binary location in the container.
Additional fields may be required for some use cases:
- Private repos need to do two things:
- Add an ssh secret that gives the bot access to the repo to the build cluster
and specify the secret name in the
ssh_key_secretsfield of the job decoration config. - Set the
clone_urifield of the job spec togit@github.com:{{.Org}}/{{.Repo}}.git.
- Add an ssh secret that gives the bot access to the repo to the build cluster
and specify the secret name in the
- Repos requiring a non-standard clone path can use the
path_aliasfield to clone the repo to different go import path than the default of/home/prow/go/src/github.com/{{.Org}}/{{.Repo}}/(e.g.path_alias: sigs.k8s.io/prow->/home/prow/go/src/sigs.k8s.io/prow). - Jobs that require additional repos to be checked out can arrange for that with
the
exta_refsfield. If the cloned path of this repo must be used as a default working dir theworkdir: truemust be specified. - Jobs that do not want submodules to be cloned should set
skip_submodulestotrue - Jobs that want to perform shallow cloning can use
clone_depthfield. It can be set to desired clone depth. By default, clone_depth get set to 0 which results in full clone of repo.
- name: post-job
decorate: true
decoration_config:
ssh_key_secrets:
- ssh-secret
clone_uri: "git@github.com:<YOUR_ORG>/<YOUR_REPO>.git"
extra_refs:
- org: kubernetes
repo: other-repo
base_ref: master
workdir: false
skip_submodules: true
clone_depth: 0
spec:
containers:
- image: alpine
command:
- "echo"
args:
- "The artifacts dir is $(ARTIFACTS)"
Migrating from bootstrap.py to Pod Utilities
Jobs using the deprecated bootstrap.py should switch to the Pod Utilities at their earliest convenience. @dims has created a handy migration guide.
Automatic Censoring of Secret Data
Many jobs exist that must touch third-party systems in order to be productive. Whether the job provisions
resources in a cloud IaaS like GCP, reports results to an aggregation service like coveralls.io, or simply
clones private repositories, jobs require sensitive credentials to achieve their goals. Even with the best
intentions, it is possible for end-user code running in a test Pod for a ProwJob to accidentally leak
the content of those credentials. If Prow is configured to push job logs and artifacts to a public cloud
storage bucket, that leak is immediately immortalized in plain text for the world to read. The sidecar
utility can infer what secrets a job has access to and censor those secrets from the output. The following
job turns on censoring:
- name: censored-job
decorate: true
decoration_config:
censor_secrets: true
Censoring Process
The automatic censoring process is written to be as useful as possible while having a bounded impact on the
execution cost in resources and time for the job. In order to censor every possible leak, all keys in all
Secrets that are mounted into the test Pod are treated as sensitive data. For each of these keys, the
value of the key as well as the base-64 encoded value are censored from the job’s log as well as any
artifacts the job produces. If any archives (e.g. .tar.gz) are found in the output artifacts for a job,
they are unarchived in order to censor their contents on the fly before being re-archived and pushed up to
cloud storage.
In order to bound the impact in runtime and resource cost for censoring on the job, both the concurrency and buffer size of the censoring algorithm are tunable. The overall steady-state memory footprint of the censoring algorithm is simply the buffer size times the maximum concurrency. The buffer must be as large as twice the length of the largest secret to be censored, but may be tuned to very small values in order to decrease the memory footprint. Keep mind that this will increase overall disk I/O and therefore increase the runtime of censoring. Therefore, in order to decrease censoring runtime the buffer should be increased.
Configuring Censoring
A number of aspects of the censoring algorithm are tunable with configuration option at the per-job level
or for entire repositories or organizations. Under the decoration_config stanza, the following options
are available to tune censoring:
decoration_config:
censoring_options:
censoring_concurrency: 0 # the number of files to censor concurrently; each allocates a buffer
censoring_buffer_size: 0 # the size of the censoring buffer, in bytes
include_directories:
- path/**/to/*something.txt # globs relative to $ARTIFACTS that should be censored; everything censored if unset
exclude_directories:
- path/**/to/*other.txt # globs relative to $ARTIFACTS that should not be censored
3.4.1 - clonerefs
clonerefs clones code under test at the specified locations. Regardless of the success or failure
of clone operations, this utility will have an exit code of 0 and will record the clone operation
status to the specified log file. Clone records have the form:
[
{
"failed": false,
"refs": {
"org": "kubernetes",
"repo": "kubernetes",
"base_ref": "master",
"base_sha": "a36820b10cde020818b8dd437e285d0e2e7d5e98",
"pulls": [
{
"number": 123,
"author": "smarterclayton",
"sha": "2b58234a8aee0d55918b158a3b38c292d6a95ef7"
}
]
},
"commands": [
{
"command": "git init",
"output": "Reinitialized existing Git repository in /go/src/k8s.io/kubernetes/.git/",
"error": ""
}
]
}
]
Note: the utility will exit with a non-zero status if a fatal error is detected and no clone operations can even begin to run.
This utility is intended to be used with initupload, which will
decode the JSON output by clonerefs and can format it for human consumption.
clonerefs can be configured by either passing in flags or by specifying a full set of options
as JSON in the $CLONEREFS_OPTIONS environment variable, which has the form:
{
"src_root": "/go",
"log": "/logs/clone-log.txt",
"git_user_name": "ci-robot",
"git_user_email": "ci-robot@k8s.io",
"refs": [
{
"org": "kubernetes",
"repo": "kubernetes",
"base_ref": "master",
"base_sha": "a36820b10cde020818b8dd437e285d0e2e7d5e98",
"pulls": [
{
"number": 123,
"author": "smarterclayton",
"sha": "2b58234a8aee0d55918b158a3b38c292d6a95ef7"
}
],
"skip_submodules": true,
"clone_depth": 0
}
]
}
3.4.2 - entrypoint
entrypoint wraps a process and records its output to stdout and stderr as well as its exit
code, recording both to disk. The utility will exit with a non-zero exit code if the wrapped
process fails or if the utility has a fatal error.
This utility is intended to be used with sidecar, which will
watch the files written by this utility and report on the status of the wrapped process.
entrypoint can be configured by either passing in flags or by specifying a full set of options
as JSON in the $ENTRYPOINT_OPTIONS environment variable, which has the form:
{
"args": [
"/bin/ls",
"-la"
],
"timeout": 7200000000000,
"grace_period": 15000000000,
"process_log": "/logs/process-log.txt",
"marker_file": "/logs/marker-file.txt"
}
Note: the "timeout" and "grace_period" fields hold the duration in nanoseconds.
3.4.3 - initupload
initupload reads clone records placed by clonerefs in order to determine job status. The status
and logs from the clone operations are uploaded to cloud storage at a path resolved from the job
configuration. This utility will exit with a non-zero exit code if the clone records indicate that
any clone operations failed, as well as if any fatal errors are encountered in this utility itself.
initupload can be configured by either passing in flags or by specifying a full set of options
as JSON in the $INITUPLOAD_OPTIONS environment variable, which has the same form as that for
gcsupload, plus the "log" field. See that documentation for
an explanation.
{
"log": "/logs/clone-log.txt",
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
3.4.4 - sidecar
sidecar watches disk for files containing a the std{out,err} output from a process as well as
its exit code; when the exit code has been written, this utility uploads a status object, the logs
from the process and any other specified artifacts to cloud storage. The utility will exit with the
exit code of the wrapped process or otherwise non-zero if the utility has a fatal error.
This utility is intended to be used with entrypoint, which will
write the files watched by this utility.
sidecar can be configured by either passing in flags or by specifying a full set of options
as JSON in the $SIDECAR_OPTIONS environment variable, which has the same form as that for
gcsupload, plus the "process_log" and "marker_file" fields. See
that documentation for an explanation.
{
"wrapper_options": {
"process_log": "/logs/process-log.txt",
"marker_file": "/logs/marker-file.txt"
},
"gcs_options": {
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
3.5 - Plugins
Plugins are sub-components of hook that consume GitHub webhooks related to their function and can be individually enabled per repo or org.
All plugin specific configuration is stored in plugins.yaml.
The Configuration golang struct holds all the config fields organized into substructures by plugin. See its GoDoc for up-to-date descriptions of every config option.
Help Information
Most plugins lack README’s but instead generate PluginHelp structs on demand that include general explanations and help information in addition to details about the current configuration.
Please see https://prow.k8s.io/plugins for a list of all plugins deployed on the Kubernetes Prow instance, what they do, and what commands they offer. For an alternate view, please see https://prow.k8s.io/command-help to see all of the commands offered by the deployed plugins.
How to enable a plugin on a repo
Add an entry to plugins.yaml. If you misspell the name then a
unit test will fail. If you have updateconfig plugin
deployed then the config will be automatically updated once the PR is merged,
else you will need to run make update-plugins. This does not require
redeploying the binaries, and will take effect within a minute.
External Plugins
External plugins offer an alternative to compiling a plugin into the hook binary. Any web endpoint that can properly handle GitHub webhooks can be configured as an external plugin that hook will forward webhooks to. External plugin endpoints are specified per org or org/repo in plugins.yaml under the external_plugins field. Specific event types may be optionally specified to filter which events are forwarded to the endpoint.
External plugins are well suited for:
- Slow operations that would impact the performance of other plugins if run as part of
hook. - Components that need to be triggered or notified of events beside GitHub webhooks.
- Isolating a more or less privileged plugin or a plugin that executes PR code.
- Integrating existing GitHub services with Prow.
Examples of external plugins can be found in the prow/external-plugins directory. The following is an example external plugin configuration that would live in plugins.yaml.
external_plugins:
org-foo/repo-bar:
- name: refresh-remote
endpoint: https://my-refresh-plugin.com
events:
- issue_comment
- name: needs-rebase
# No endpoint specified implies "http://{{name}}".
events:
- pull_request
# Dispatching issue_comment events to the needs-rebase plugin is optional. If enabled, this may cost up to two token per comment on a PR. If `ghproxy`
# is in use, these two tokens are only needed if the PR or its mergeability changed.
- issue_comment
- name: cherrypick
# No events specified implies all event types.
How to test a plugin
3.5.1 - approve
This is a placeholder page. Some contents needs to be filled.
3.5.1.1 - Reviewers and Approvers
Questions this Doc Seeks To Answer
- What are reviewers, approvers, and the OWNERS files?
- How does the reviewer selection mechanism work? approver selection mechanism work?
- How does an approver know which PR s/he has to approve?
Overview
Every GitHub directory which is a unit of independent code contains a file named “OWNERS”. The file lists reviewers and approvers for the directory. Approvers (or previously called assignees) are owners of the codes.
Approvers:
- have contributed substantially to the repo
- can provide an approval (
/approve) indicating whether a change to a directory or subdirectory should be accepted - Approval is done on a per directory basis and subdirectories inherit their parents directory’s approvers
Reviewers:
- generally a larger set of current and past contributors
- They are responsible for a more thorough code review, discussing the implementation details and style
- Provide an
/lgtmwhen they are satisfied with the Pull Request. The/lgtmmust be renewed whenever the Pull Request changes.
An example of the OWNERS file is listed below:
reviewers:
- jack
- ken
- lina
approvers:
- jack
- ken
- lina
Note that items in the OWNERS files can be GitHub usernames, or aliases defined in OWNERS_ALIASES files. An OWNERS_ALIASES file is another co-existed file that delivers a mechanism for defining groups. However, GitHub Team names are not supported. We do not use them because there is no audit log for changes to the GitHub Teams. This way we have an audit log.
Blunderbuss And Reviewers
lgtm Label
LGTM is abbreviation for “looks good to me”. The lgtm label is normally given when the code has been thoroughly reviewed. Getting it means the PR is one step away from getting merged. Reviewers of the PR give the label to a PR by typing /lgtm in a comment, or retract it by typing /lgtm cancel (at the beginning of a comment line). Authors of the PR cannot give the label, but they can cancel it. The bot retracts the label automatically if someone updates the PR with a new commit.
Any collaborator on the repo may use the /lgtm command, whether or not they are selected as a reviewer or approver by this plugin. (See the next section for reviewer and approver selection algorithm.)
Blunderbuss Selection Mechanism
Blunderbuss provides statistical means to select a subset of approvers found in OWNERS files for approving a PR. A PR consists of changes on one or more files, in which each file has different number of lines of codes changed. Blunderbuss determines the magnitude of code change within a PR using total number of lines of codes changed across various files. Number of reviewers selected for each PR is 2.
Algorithm for selecting reviewers is as follows:
-
determine potential reviewers of a file by going over all reviewers found in the OWNERS files for current and parent directories of the file (deduplication involved)
-
assign each changed file with a weightage based on number of lines of codes changed
-
assign each potential reviewer with a weightage by summing up weightages of all changed files in which s/he is a reviewer
-
randomly select 2 reviewers based on their weightage
Approval Handler and the Approved Label
approved Label
A PR cannot be merged into the repo without the approved label. In order for the approved label to be applied, every file modified by the PR must be approved (via /approve) by an approver from the OWNERs files. Note, this does not necessarily require multiple approvers. The process is best illustrated in the example below.
Approval Selection Mechanism
First, it is important to understand that ALL approvers in an OWNERS file can approve any file in that directory AND its subdirectories. Second, it is important to understand the somewhat-competing goals of the bot when selecting approvers:
-
Provide a subset of approvers that can approve all files in the PR
-
Provide a small subset of approvers and suggest the same reviewers as blunderbuss if possible (people can be both reviewers and approvers)
-
Do not always suggest the same set of people to approve and do not consistently suggest people from the root OWNERS file
The exact algorithm for selecting approvers is somewhat complex; it is an set cover approximation with consideration for existing assignees. To read it in depth, check out the approvers source code linked at the end of the README.
Example

Suppose files in directories E and G are changed in a PR created by PRAuthor. Any combination of approver(s) listed below can approve the PR in order to get it merged:
-
approvers found in OWNERS files for leaf (current) directories E and G
-
approvers found in OWNERS files for parent directories B and C
-
approvers found in OWNERS files for root directory A
Note someone can be both a reviewer found in OWNERS files for directory A and E. If s/he is selected as an approver and gives approval, it approves entire PR because s/he is also a reviewer for the root directory A.
Step 1:
K8s-bot creates a comment that suggests the selected approvers and shows a list of OWNERS file(s) where the approvers can be found.
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *PRAuthor*
We suggest the following additional approvers: **approver1,** **approver2**
If they are not already assigned, you can assign the PR to them by writing `/assign @approver1 @approver2` in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* /A/B/E/OWNERS
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
A selected approver such as approver1 can be notified by typing /assign @approver1 in a comment.
Step 2:
approver1 is in the E OWNERS file. S/he writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, PRAuthor*
We suggest the following additional approver: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
Step 3:
approver3 (an approver for D) is NOT an approver for any of the affected directories. S/he writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, approver3, PRAuthor*
We suggest the following additional approvers: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver1 @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
Step 4:
approver1 is an approver of the PR. S/he writes /lgtm
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, approver3, PRAuthor*
We suggest the following additional approver: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
The lgtm label is immediately added to the PR.
Step 5:
approver2 (who in the C OWNERS file, which is a parent to G) writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **APPROVED**
The following people have approved this PR: *approver1, approver2, approver3, PRAuthor*
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* ~/A/C/G/OWNERS~ [approver2]
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
The PR is now unblocked from merging. If Tide is configured, the K8s-bot merges the PR, because it has both the lgtm and approved. It K8s-bot still needs to wait its turn in submit queue and pass tests.

Configuration options
See the Approve go struct for documentation of the options for this plugin.
See also the Lgtm go struct for documentation of the LGTM plugin’s options.
Final Notes
Obtaining approvals from selected approvers is the last step towards merging a PR. The approvers approve a PR by typing /approve in a comment, or retract it by typing /approve cancel.
Algorithm for getting the status is as follow:
-
run through all comments to obtain latest intention of approvers
-
put all approvers into an approver set
-
determine whether a file has at least one approver in the approver set
-
add the status to the PR if all files have been approved
If an approval is cancelled, the bot will delete the status added to the PR and remove the approver from the approver set. If someone who is not an approver in the OWNERS file types /approve in a comment, the PR will not be approved. If someone who is an approver in the OWNERS file and s/he does not get selected, s/he can still type /approve or /lgtm in a comment, pushing the PR forward.
Code Implementation Links
Blunderbuss: prow/plugins/blunderbuss/blunderbuss.go
LGTM: prow/plugins/lgtm/lgtm.go
Approve: prow/plugins/approve/approve.go
3.5.2 - branchcleaner
The branchcleaner plugin automatically deletes source branches for merged PRs between two branches
on the same repository. This is helpful to keep repos that don’t allow forking clean.
Usage
Enable the branchcleaner in the desired repos via the plugins.yaml:
plugins:
org/repo:
- branchcleaner
3.5.3 - lgtm
See the documentation in the approve plugin for details on the LGTM flow.
3.5.4 - updateconfig
updateconfig allows prow to update configmaps when files in a repo change.
updateconfig also supports glob match, or multi-key updates.
Usage
Update your plugins.yaml file to something along the following lines:
plugins:
my-github/repo:
plugins:
- config-updater
config_updater:
maps:
# Update the thing-config configmap whenever thing changes
path/to/some/other/thing:
name: thing-config
# If cluster and namespace configuration are unset, it will be put into the default cluster in the prowjob namespace
path/to/some/other/thing2:
name: thing2-config
# Specify the clusters and namespaces that the configmap targets
# which requires that the --kubeconfig arg is enabled for Hook
# https://docs.prow.k8s.io/docs/getting-started-deploy/#run-test-pods-in-different-clusters
# if not set or empty, it uses the cluster where prow components are running
# and the specified namespace(s)
clusters:
others:
- namespace1
# Update the config configmap whenever config.yaml changes
config/prow/config.yaml:
name: config
# Update the plugin configmap whenever plugins.yaml changes
config/prow/plugins.yaml:
name: plugin
# Update the `this` or/and `that` key in the `data` configmap whenever `data.yaml` or/and `other-data.yaml` changes
some/data.yaml:
name: data
key: this
some/other-data.yaml:
name: data
key: that
# Update the fejtaverse configmap whenever any `.yaml` file under `fejtaverse` changes
fejtaverse/**/*.yaml:
name: fejtaverse
3.6 - External Plugins
This is a placeholder page. Some contents needs to be filled.
3.6.1 - cherrypicker
Cherrypicker is an external prow plugin that can also run as a standalone bot. It automates cherry-picking merged PRs into different branches. Cherrypicks are triggered from either comments or labels in GitHub PRs that need to be cherrypicked.
For comments:
/cherrypick release-1.10
The above comment will result in opening a new PR against the release-1.10 branch
once the PR where the comment was made gets merged or is already merged.
To use label, you need to apply labels that contain the name of the branch in the form:
cherrypick/XXX
where XXX is the name of the branch.
The bot uses its own fork to push patches that need to be cherry-picked and opens PRs out of those patches. The fork is created automatically by the bot so there is no need to set it up manually.
Required scopes for the oauth token that need to be used are read:org and repo.
3.7 - Deprecated Components
3.7.1 - cm2kc (clustermap to kubeconfig)
Description
cm2kc is a CLI tool used to convert a clustermap file to a kubeconfig file.
Usage
go run ./cmd/cm2kc <options>
The following is a list of supported options for cm2kc:
-i, --input string Input clustermap file. (default "/dev/stdin")
-o, --output string Output kubeconfig file. (default "/dev/stdout")
Examples
Add a kubeconfig file in a secret: kubeconfig from a clustermap file in another secret: build-cluster for context: my-context
The following command will:
- Get a clustermap formatted secret:
build-clusterin key:clusterfor context:my-context. - Base64 decode the secret.
- Convert the clustermap data to a kubeconfig format.
- Create a kubeconfig formatted secret:
kubeconfigin key:configfor context:my-contextfrom the converted data.
kubectl --context=my-context get secrets build-cluster -o jsonpath='{.data.cluster}' |
base64 -d |
go run ./cmd/cm2kc |
kubectl --context=my-context create secret generic kubeconfig --from-file=config=/dev/stdin
Lastly, to begin using this in Prow, update the volume mount and replace --build-cluster with --kubeconfig in the deployment of each relevant Prow component (e.g. crier, deck, plank, and sinker).
Create a kubeconfig file at path /path/to/kubeconfig.yaml from a clustermap file at path /path/to/clustermap.yaml
Ensure the clustermap file exists at the specified --input path:
# /path/to/clustermap.yaml
default:
clientCertificate: fake-default-client-cert
clientKey: fake-default-client-key
clusterCaCertificate: fake-default-ca-cert
endpoint: https://1.2.3.4
build:
clientCertificate: fake-build-client-cert
clientKey: fake-build-client-key
clusterCaCertificate: fake-build-ca-cert
endpoint: https://5.6.7.8
Execute cm2kc specifying an --input path to the clustermap file and an --output path to the desired location of the generated kubeconfig file:
go run ./cmd/cm2kc --input=/path/to/clustermap.yaml --output=/path/to/kubeconfig.yaml
The following kubeconfig file will be created at the specified --output path:
# /path/to/kubeconfig.yaml
apiVersion: v1
clusters:
- name: default
cluster:
certificate-authority-data: fake-default-ca-cert
server: https://1.2.3.4
- name: build
cluster:
certificate-authority-data: fake-build-ca-cert
server: https://5.6.7.8
contexts:
- name: default
context:
cluster: default
user: default
- name: build
context:
cluster: build
user: build
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
client-certificate-data: fake-default-ca-cert
client-key-data: fake-default-ca-cert
- name: build
user:
client-certificate-data: fake-build-ca-cert
client-key-data: fake-build-ca-cert
3.7.2 - Plank
Plank is the controller that manages the job execution and lifecycle for jobs running in k8s.
Usage
go run ./cmd/prow-controller-manager --help
Configuration
GCS and S3 are supported as the job log storage.
# config.yaml
plank:
# used to link to job results for decorated jobs (with pod utilities)
job_url_prefix_config:
'*': https://<domain>/view
# used to link to job results for non decorated jobs (without pod utilities)
job_url_template: 'https://<domain>/view/<bucket-name>/pr-logs/pull/{{.Spec.Refs.Repo}}/{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}/{{.Spec.Job}}/{{.Status.BuildID}}'
report_template: '[Full PR test history](https://<domain>/pr-history?org={{.Spec.Refs.Org}}&repo={{.Spec.Refs.Repo}}&pr={{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}})'
default_decoration_config_entries:
# All entries that match a job are used, later entries override previous values.
# Omission of 'repo' and 'cluster' fields makes this entry match all jobs.
- config:
timeout: 4h
grace_period: 15s
utility_images: # pull specs for container images used to construct job pods
clonerefs: gcr.io/k8s-prow/clonerefs:v20190221-d14461a
initupload: gcr.io/k8s-prow/initupload:v20190221-d14461a
entrypoint: gcr.io/k8s-prow/entrypoint:v20190221-d14461a
sidecar: gcr.io/k8s-prow/sidecar:v20190221-d14461a
gcs_configuration: # configuration for uploading job results to GCS
bucket: <bucket-name> or s3://<bucket-name>
path_strategy: explicit # or `legacy`, `single`
default_org: <github-org> # should not need this if `strategy` is set to explicit
default_repo: <github-repo> # should not need this if `strategy` is set to explicit
gcs_credentials_secret: <secret-name> # the name of the secret that stores cloud provider credentials
ssh_key_secrets:
- ssh-secret # name of the secret that stores the bot's ssh keys for GitHub, doesn't matter what the key of the map is and it will just uses the values
- repo: "^org/" # some regexp to match against <org/repo>
config:
timeout:2h
- cluster: "-trusted$" #some regexp to match against the cluster name
config:
# example override to use k8s SA with GCP workload identity rather than
# a GCP service account key file.
gcs_credentials_secret: ""
3.8 - Undocumented Components
3.8.1 - admission
This is a placeholder page. Some contents needs to be filled.
3.8.2 - grandmatriarch
This is a placeholder page. Some contents needs to be filled.
3.8.3 - pipeline
This is a placeholder page. Some contents needs to be filled.
4 - GKE Build Clusters
Note: This page discusses build clusters that use GKE. Technically speaking, a build cluster could be any Kubernetes cluster (not just GKE) because the only thing Prow needs is the ability to authenticate as a Kubernetes Service Account with cluster-admin role permissions to the build cluster.
Overview
By default Prow will schedule jobs in the cluster that maps to a kubeconfig
alias named “default” (imagine running kubectl config set-context "default" --cluster=<CLUSTER_CONTEXT>, where the <CLUSTER_CONTEXT> could be any
cluster). So the jobs can be scheduled either in the same cluster that is
hosting Prow itself, or a different one. For example the “default” cluster
in https://prow.k8s.io is the build cluster located in
the k8s-prow-builds GCP project and not the k8s-prow GCP project where the
Prow services actually run.
Setting up a separate build cluster will allow you to schedule jobs into a different Kubernetes cluster altogether. When everything’s set up, Prow’s component will schedule jobs into your build cluster (as shown in the Arhictecture diagram) instead of its own. This way, you can “bring your own build cluster” to Prow to make it scale however you see fit.
For convenience we use the terms KSA and GSA, where KSA means Kubernetes Service Account and GSA means GCP (IAM) Service Account.
Running the build cluster setup script
The Prow source repo comes with a default create-build-cluster.sh script which allows you to create a new GKE cluster with the intent of giving the Kubernetes Prow instance access to it. Because there are different Prow instances and each instance has its own default settings (esp. for permissions), each instance has its own such script, forked from the default one. For example, Google’s OSS Prow instance has its own script here.
The scripts all have prompts and ask you various questions to set everything up. If everything proceeds smoothly, then there’s nothing more for you to do (you’re ready to start writing Prow jobs that use your cluster). Below is a discussion of the overall process to demystify what goes on behind the scenes.
How does Prow actually use your build cluster?
There are two requirements:
- Prow must be able to schedule jobs into your build cluster.
- The jobs themselves must be able to upload artifacts to the GCS bucket used by Deck, in order to report job status (e.g., “passing” or “failing”).
We look at both requirements below.
Let Prow schedule your jobs into your build cluster
Prow is a Kubernetes cluster. So is your build cluster. In order for Prow to
schedule jobs (i.e., create Kubernetes pods) into your build cluster, it must be
able to authenticate as a KSA1 defined in your build cluster that has a
cluster-admin
Kubernetes role. This way, the prow-controller-manager component can
freely create, update, and delete jobs (pods) in your build cluster as
necessary. The item “KSA A” in the diagram below is this service account.
In order for Prow’s components to authenticate as the cluster-admin KSA in your build cluster, they use a token. You can think of this token simply as a password, that when provided to your build cluster’s API server along with the KSA name, grants authentication as this very same KSA.
The question now turns to how we can generate this token. This can be done
manually, but the token cannot be valid for longer than 2 days for security
reasons (a GKE restriction), and must be rotated regularly. Fortunately, there
is a tool called gencred that automates the generation of the token. We just
need to have it be run periodically — and so we need to add a Prow job that
regularly invokes gencred.
Once the token is generated, we can store it in the GCP Secret Manager for the
GCP project that is running Prow for safekeeping. Then we have to mount this
token into the various Prow components that need it; this one-way sync is
performed by the kubernetes-external-secrets component. The Prow components'
configurations don’t have to be updated though, because your build cluster’s
token is combined with other secrets into a composite file.
Let your jobs report their status to GCS
Your jobs in your build cluster must have GCS access in order to upload critical
job metadata, such as a finished.json file to indicate the status of your job
(whether it passed or failed). The GCS bucket location usually depends on how
the Prow instance is configured. Currently they are:
| Prow instance | GCS bucket |
|---|---|
| https://prow.k8s.io/ | gs://kubernetes-jenkins (source) |
| https://oss.gprow.dev/ | gs://oss-prow (source) |
You can also configure this to be a different bucket (example).
In order to grant your job access to a GCS bucket, we’ll use Workload Identity.
The basic steps to get GCS uploads working are:
- Create
KSA B - Create
GSA C - Bind
KSA Bin thetest-podsnamespace toGSA Cwith Workload Identity. - Assign
KSA Ba Workload Identity annotation so that GKE knows to automatically run the “impersonate as GSA C” process when the prowjob Kubernetes pod starts in your build cluster.
Below is a diagram of all critical pieces between your build cluster and Prow, once everything is set up and working.
flowchart TD
classDef yellow fill:#ff0
classDef cyan fill:#0ff
classDef pink fill:#f99
classDef clear fill:#00000000,stroke-width:0px
style GCS fill:#cca
style GSA_C fill:#ae0
style KES_pod fill:#0ff
style KSA_A_token fill:#f90
style Kubeconfig_secret fill:#f90
style PCM_pod fill:#0ff
style gencred_prowjob_pod fill:#ff0
style other_pods fill:#0ff
style prowjob_pod fill:#ff0
style testpods_namespace fill:#f1cab
style your_gcp_project fill:#00000000
style another_gcp_project fill:#00000000
subgraph Prow["GKE K8S CLUSTER (PROW)"]
subgraph default_namespace["'default' namespace, where all Prow components run"]
PCM_pod["prow-controller-manager\n(Prow component)"]
KES_pod["kubernetes-external-secrets\n(Prow component)"]
other_pods["Other Prow components"]
Kubeconfig_secret["Kubeconfig secret"]
%%caption1["(This is where Prow services run.)"]:::clear
end
subgraph test_pods_namespace["'test-pods' namespace, aka trusted build cluster"]
gencred_prowjob_pod["gencred prowjob"]
end
subgraph GCP Secret Manager
KSA_A_token["Secret (2-day) token for <b>KSA A</b>"]
end
end
subgraph your_gcp_project["Your GCP Project"]
subgraph Build Cluster["GKE K8S CLUSTER (YOUR BUILD CLUSTER)"]
subgraph testpods_namespace["'test-pods' K8s namespace"]
prowjob_pod["K8s Pod\n(prowjob)\n\nRuns as <b>KSA B</b>, bound to <b>GSA C</b> via\nWorkload Identity"]
KSA_B["<b>KSA B</b>"]
end
KSA_A["<b>KSA A</b>\n\nHas cluster-admin access\nfor your cluster"]
end
subgraph GCP IAM
GSA_C["<b>GSA C</b>"]
end
end
subgraph another_gcp_project["Another GCP Project"]
GCS
end
PCM_pod ===> |"Schedules prowjob pod via\nauthorization as <b>KSA A</b>\nusing a <b>kubectl apply ...</b> equivalent"| prowjob_pod
gencred_prowjob_pod --> |"Creates\n(if one does not exist)"| KSA_A
gencred_prowjob_pod --> |"Refreshes\n(creates a new one)"| KSA_A_token
prowjob_pod -.-> |"Runs as"| KSA_B
prowjob_pod --> |"Uploads via\nauthorization as <b>GSA C</b>"| GCS["<span style='font-size: 30px'>GCS</span>"]
prowjob_pod -.-> |"Impersonates via\nWorkload Identity"| GSA_C
KES_pod --> |"Reads"| KSA_A_token
KES_pod --> |"Merges into"| Kubeconfig_secret
Kubeconfig_secret --> |"Mounted into"| PCM_pod
Kubeconfig_secret --> |"Mounted into"| other_pods
GSA_C -.-> |"Has write access"| GCS
-
KSA is not a hard requirement; it’s just an easier way to generate a kubeconfig for authenticating with a build cluster. The other method is via creating a certificate. ↩︎
5 - Contribution Guidelines
Clearing out of Legacy Snapshot
Our docs have been migrated from the Prow folder inside the kubernetes/test-infra repository to the kubernetes-sigs/prow repository (the page you are reading is generated from kubernetes-sigs/prow). However, these migrated files have been placed under the Legacy Snapshot directory because they have not been vetted by the Prow team as being up-to-date. The original files have been frozen and can no longer be modified.
Our current top priority is to review docs under the Legacy Snapshot and to move them to a more appropriate section. Please contribute!
Updating existing docs
If you need to update an existing doc (that is, in
kubernetes/test-infra/prow/.*\.md), you must find the corresponding file in
Legacy Snapshot and move it to a more appropriate location.
Tooling
We use Hugo to format and generate our website, the Docsy theme for styling and site structure, and Netlify to manage the deployment of the site. Hugo is an open-source static site generator that provides us with templates, content organisation in a standard directory structure, and a website generation engine. You write the pages in Markdown (or HTML if you want), and Hugo wraps them up into a website.
Useful resources
- Docsy user guide: All about Docsy (the Hugo theme used on this site).
6 - Metrics
Prometheus Metrics
Some Prow components expose Prometheus metrics that can be used for monitoring and alerting. The following table describes the metrics that are currently available.
| Component | Type | Metric | Labels | Description |
|---|---|---|---|---|
| Tide | Gauge | pooledprs |
org, repo, branch | The number of PRs in each Tide pool. |
| Gauge | updatetime |
org, repo, branch | The last time each Tide pool was synced. | |
| Gauge | syncdur |
The Tide sync controller loop duration. | ||
| Gauge | statusupdatedur |
The Tide status controller loop duration. | ||
| Histogram | merges |
org, repo, branch | A histogram of the number of PRs in each merge. | |
| Counter | tidepoolerrors |
org, repo, branch | Count of Tide pool sync errors. | |
| Counter | tidequeryresults |
query_index, org_shard, result | Count of Tide queries by query index, org shard, and result (success/error). | |
| Counter | tidesyncheartbeat |
controller | Count of Tide syncs per controller. | |
| Hook | Counter | prow_webhook_counter |
event_type | The number of GitHub webhooks received by Prow. |
| Plank/Jenkins-Operator | Gauge | prowjobs |
job_name, type, state | The number of ProwJobs. |
| Jenkins-Operator | Counter | jenkins_requests |
verb, handler, code | The number of jenkins requests made by Prow. |
| Counter | jenkins_request_retries |
The number of jenkins request retries Prow has made. | ||
| Histogram | jenkins_request_latency |
verb, handler | A histogram of round trip times between Prow and Jenkins. | |
| Histogram | resync_period_seconds |
A histogram of the jenkins controller loop duration. | ||
| Bugzilla | Histogram | bugzilla_request_duration |
method, status | Bugzilla request duration by API path. |
| Sinker | Gauge | sinker_pods_existing |
Number of the existing pods in each sinker cleaning. | |
| Gauge | sinker_loop_duration_seconds |
Time used in each sinker cleaning. | ||
| Gauge | sinker_pods_removed |
reason | Number of pods removed in each sinker cleaning. | |
| Gauge | sinker_pod_removal_errors |
reason | Number of errors which occurred in each sinker pod cleaning. | |
| Gauge | sinker_prow_jobs_existing |
Number of the existing prow jobs in each sinker cleaning. | ||
| Gauge | sinker_prow_jobs_cleaned |
reason | Number of prow jobs cleaned in each sinker cleaning. | |
| Gauge | sinker_prow_jobs_cleaning_errors |
reason | Number of errors which occurred in each sinker prow job cleaning. | |
| Crier | Histogram | crier_report_latency |
reporter | Histogram of time spent reporting, calculated by the time difference between job completion and end of reporting. |
| Counter | crier_reporting_results |
reporter, result | Count of successful and failed reporting attempts by reporter. | |
| Flagutil | Counter | kubernetes_failed_client_creations |
cluster | The number of clusters for which we failed to create a client. |
| Gerrit/Adapter | Counter | gerrit_processing_results |
instance, repo, result | Count of change processing by instance, repo, and result. |
| Histogram | gerrit_trigger_latency |
instance | Histogram of seconds between triggering event and ProwJob creation time. | |
| Gerrit/Client | Counter | gerrit_query_results |
instance, repo, result | Count of Gerrit API queries by instance, repo, and result. |
| GitHub | Gauge | github_user_info |
token_hash, login, email | Metadata about a user, tied to their token hash. |
| GitHub-Server | Counter | prow_webhook_counter |
event_type | A counter of the webhooks made to prow. |
| Counter | prow_webhook_response_codes |
response_code | A counter of the different responses hook has responded to webhooks with. | |
| Histogram | prow_plugin_handle_duration_seconds |
event_type, action, plugin, took_action | How long Prow took to handle an event by plugin, event type and action. | |
| Counter | prow_plugin_handle_errors |
event_type, action, plugin, took_action | Prow errors handling an event by plugin, event type and action. | |
| Jenkins | Counter | jenkins_requests |
verb, handler, code | Number of Jenkins requests made from prow. |
| Counter | jenkins_request_retries |
Number of Jenkins request retries made from prow. | ||
| Histogram | jenkins_request_latency |
verb, handler | Time for a request to roundtrip between prow and Jenkins. | |
| Histogram | resync_period_seconds |
Time the controller takes to complete one reconciliation loop. | ||
| Jira | Histogram | jira_request_duration_seconds |
method, path, status | |
| Kube | Gauge | prowjobs |
job_namespace, job_name, type, state, org, repo, base_ref, cluster, retest | Number of prowjobs in the system. |
| Counter | prowjob_state_transitions |
job_namespace, job_name, type, state, org, repo, base_ref, cluster, retest | Number of prowjobs transitioning states. | |
| Plugins | Gauge | prow_configmap_size_bytes |
name, namespace | Size of data fields in ConfigMaps updated automatically by Prow in bytes. |
| Pubsub/Subscriber | Counter | prow_pubsub_message_counter |
subscription | A counter of the webhooks made to prow. |
| Counter | prow_pubsub_error_counter |
subscription, error_type | A counter of the webhooks made to prow. | |
| Counter | prow_pubsub_ack_counter |
subscription | A counter for message acked made to prow. | |
| Counter | prow_pubsub_nack_counter |
subscription | A counter for message nacked made to prow. | |
| Counter | prow_pubsub_response_codes |
response_code, subscription | A counter of the different responses server has responded to Push Events with. | |
| Version | Gauge | prow_version |
Prow Version. |
Pushgateway and Proxy
To support metric collection from ephemeral tasks like request handling and to
provide a single scrape endpoint, Prow’s prometheus metrics are pushed to a
Prometheus pushgateway that is scraped instead of the metric source. A proxy is
used to limit cluster external requests to GET requests since Prometheus doesn’t
provide any form of authentication. The pushgateway and proxy deployment are
defined in pushgateway_deployment.yaml.
Kubernetes Prow Metrics
Prometheus metrics from the Kubernetes Prow instance are used to create the graphs at http://monitoring.prow.k8s.io
7 - Building, Testing, and Updating Prow
This guide is directed at Prow developers and maintainers who want to build/test individual components or deploy changes to an existing Prow cluster. “Deploying Prow” is a better reference for deploying a new Prow cluster.
How to build and test Prow
You can build, test, and deploy Prow’s binaries, container images, and cluster resources.
Build locally with:
make build-images
Push to remote with
make push-images REGISTRY=<YOUR_REGISTRY>
Unit test with:
make test
Integration test with(more details):
./test/integration/integration-test.sh
Individual packages and components can be built and tested like:
go build ./cmd/hook
go test ./pkg/plugins/lgtm
(Note: deck depends on non-go static files, these were tested by integration
tests, and for e2e test use runlocal if desired.)
How to test a plugin
If you are making changes to a Prow plugin you can test the new behavior by sending fake webhooks to hook with phony.
How to update the cluster
Any modifications to prow Go code will require redeploying the affected binaries. The process of doing so is streamlined, which is highly recommended to all prow instances:
- Prow code change PR merged.
post-test-infra-push-prowis automatically triggered, can be found on prow.k8s.io, which pushes images to gcr.io/k8s-prow.- Periodic job
ci-test-infra-autobump-prowruns every hour, looking for latest image tags from gcr.io/k8s-prow, and creates a PR (example) to let prow use the latest tag. - Once the periodic job is merged,
post-test-infra-deploy-prowdeploys the config changes from the PR above.
How to test a ProwJob
The best way to go about testing a new ProwJob depends on the job itself. If the job can be run locally that is typically the best way to initially test the job because local debugging is easier and safer than debugging in CI. See Running a ProwJob Locally below.
Actually running the job on Prow by merging the job config is the next step.
Typically, new presubmit jobs are configured to skip_reporting to GitHub and
may not be configured to automatically run on every PR with always_run: true.
Once the job is stable these values can be changed to make the job run everywhere
and become visible to users by posting results to GitHub (if desired). Changes
to existing jobs can be trialed on canary jobs.
ProwJobs can also be manually triggered by generating a YAML ProwJob CRD with mkpj and deploying that directly to the Prow cluster, however this pattern is generally not recommended. It requires the use of direct prod cluster access, allows ProwJobs to run in prod without passing presubmit validation, and can result in malformed ProwJobs CRDs that can jam some of Prow’s core service components. See How to manually run a given job on Prow below if you need to do this.
Running a ProwJob Locally
Using pj-on-kind.sh
pj-on-kind.sh is a bash script that runs ProwJobs locally as pods in a Kind cluster. The script does the following:
- Installs mkpj, mkpod, and Kind if they are not found in the path. A Kind
cluster named
mkpodis created if one does not already exist. - Uses mkpj to generate a YAML ProwJob CRD given job name, config, and git refs (if applicable).
- Uses mkpod to generate a YAML Pod resource from the ProwJob CRD. This Pod will
be decorated with the pod utilities if needed and will exactly match what would be
applied in prod with two exceptions:
- The job logs, metadata, and artifacts will be copied to disk rather than
uploaded to GCS. By default these files are copied to
/mnt/disks/prowjob-out/<job-name>/<build-id>/on the host machine. - Any volume mounts may be substituted for
emptyDirorhostPathvolumes at the interactive prompt to replace dependencies that are only available in prod. NOTE! In order forhostPathvolume sources to reach the host and not just the Kind “node” container, use paths under/mnt/disks/kind-nodeor set$NODE_DIRbefore the mkpod cluster is created.
- The job logs, metadata, and artifacts will be copied to disk rather than
uploaded to GCS. By default these files are copied to
- Applies the Pod to the Kind cluster and starts watching it (interrupt whenever, this is for convenience). At this point the Pod will start running if configured correctly.
Once the Pod has been applied to the cluster you can wait for it to complete and output
results to the output directory, or you can interact with it using kubectl by first
running export KUBECONFIG="$(kind get kubeconfig-path --name=mkpod)".
Requirements: Go, Docker, and kubectl must be installed before using this script.
The ProwJob must use agent: kubernetes (the default, runs ProwJobs as Pods).
pj-on-kind.sh for specific Prow instances
Each Prow instance can supply a preconfigured variant of pj-on-kind.sh that properly
defaults the config file locations. Example
for prow.istio.io.
To test ProwJobs for the prow.k8s.io instance use config/pj-on-kind.sh.
Example
This command runs the ProwJob pull-test-infra-yamllint locally on Kind.
./pj-on-kind.sh pull-test-infra-yamllint
You may also need to set the CONFIG_PATH and JOB_CONFIG_PATH environmental variables:
CONFIG_PATH=$(realpath ../config/prow/config.yaml) JOB_CONFIG_PATH=$(realpath ../config/jobs/kubernetes/test-infra/test-infra-presubmits.yaml) ...
Modifying pj-on-kind.sh for special scenarios
This tool was written in bash so that it can be easily adjusted when debugging. In particular it should be easy to modify the main function to:
- Add additional K8s resources to the cluster before running the Pod such as secrets, configmaps, or volumes.
- Skip applying the pod.yaml to the Kind cluster to inspect it, modify it, or apply it to
a real cluster instead of the
mkpodKind cluster. (Same for pj.yaml)
Debugging within a pj-on-kind.sh container
To point kubectl to the Kind cluster you will need to export the KUBECONFIG Env. The command to point this to the correct config is echoed in the pj-on-kind.sh logging. It will have the form:
export KUBECONFIG='/<path to user dir>/.kube/kind-config-mkpod'
After pointing to the correct master you will be able to drop into the container using kubectl exec -it <pod name> <bash/sh/etc>. **This pod will only last the lifecycle of the job, if you need more time to debug you might add a sleep within the job execution.
Using Phaino
Phaino lets you interactively mock and run the job locally on your workstation in a docker container. Detailed instructions can be found in Phaino’s Readme.
Note: Test containers designed for decorated jobs (configured with decorate: true)
may behave incorrectly or fail entirely without the environment the pod utilities
provide. Similarly jobs that mount volumes or use extra_refs likely won’t work
properly.
These jobs are best run locally as decorated pods inside a Kind cluster Using pj-on-kind.sh.
How to manually run a given job on Prow
If the normal job triggering mechanisms (/test foo comments, PR changes, PR
merges, cron schedule) are not sufficient for your testing you can use mkpj to
manually trigger new ProwJob runs.
To manually trigger any ProwJob, run the following, specifying JOB_NAME:
For K8S Prow, you can trigger a job by running
go run ./config:mkpj --job=JOB_NAME
For your own prow instance:
go run sigs.k8s.io/prow/cmd/mkpj --job=JOB_NAME --config-path=path/to/config.yaml
Alternatively, if you have jobs defined in a separate job-config, you can
specify the config by adding the flag --job-config-path=path/to/job/config.yaml.
This will print the ProwJob YAML to stdout. You may pipe it into kubectl.
Depending on the job, you will need to specify more information such as PR
number.
NOTE: It is dangerous to create ProwJobs from handcrafted YAML. Please use mkpj
to generate ProwJob YAML.
8 - Deploying Prow
This document will walk you through deploying your own Prow instance to a new Kubernetes cluster. If you encounter difficulties, please open an issue so that we can make this process easier.
Prow runs in any kubernetes cluster. The guide below is focused on Google Kubernetes Engine but should work on any kubernetes distro with no/minimal changes.
GitHub App
First, you need to create a GitHub app. GitHub itself documents this. Initially, it is sufficient to set a dummy url for the Webhook. The exact set of permissions needed varies based on what functionality you use. Below is a minimum set of permissions needed. Please keep in mind that any changes to the permissions your app requests (both added and removed) require everyone to re-install it.
Repository permissions:
- Actions: Read-Only (Only needed when using the merge automation
tide) - Administration: Read-Only (Required to fetch teams and collaborators, Read & write needed when using branch protection automation)
- Checks: Read-Only (Only needed when using the merge automation
tide) - Contents: Read (Read & write needed when using the merge automation
tide) - Issues: Read & write
- Metadata: Read-Only
- Pull Requests: Read & write
- Projects: Admin when using the
projectsplugin, none otherwise - Commit statuses: Read & write
Organization permissions:
- Members: Read-Only (Read & write when using
peribolos) - Projects: Admin when using the
projectsplugin, none otherwise
In Subscribe to events select all events.
After you saved the app, click “Generate Private Key” on the bottom
and save the private key together with the App ID in the top of the
page.
Deploying prow
Prow runs in a kubernetes cluster, so first figure out which cluster you want to deploy prow into. If you already have a cluster created you can skip to the Create cluster role bindings step.
Create the cluster
You can use the GCP cloud console to set up a project and create a new Kubernetes Engine cluster.
I’m assuming that PROJECT and ZONE environment variables are set, if you are using
GCP. Skip this step if you are using another service to host your Kubernetes cluster.
$ export PROJECT=your-project
$ export ZONE=us-west1-a
Run the following to create the cluster. This will also set up kubectl to
point to the new cluster on GCP.
$ gcloud container --project "${PROJECT}" clusters create prow \
--zone "${ZONE}" --machine-type n1-standard-4 --num-nodes 2
Create cluster role bindings
As of 1.8 Kubernetes uses Role-Based Access Control (“RBAC”) to drive authorization decisions, allowing cluster-admin to dynamically configure policies.
To create cluster resources you need to grant a user cluster-admin role in all namespaces for the cluster.
For Prow on GCP, you can use the following command.
$ kubectl create clusterrolebinding cluster-admin-binding \
--clusterrole cluster-admin --user $(gcloud config get-value account)
For Prow on other platforms, the following command will likely work.
$ kubectl create clusterrolebinding cluster-admin-binding-"${USER}" \
--clusterrole=cluster-admin --user="${USER}"
On some platforms the USER variable may not map correctly to the user
in-cluster. If you see an error of the following form, this is likely the case.
Error from server (Forbidden): error when creating
"config/prow/cluster/starter/starter-gcs.yaml": roles.rbac.authorization.k8s.io "<account>" is
forbidden: attempt to grant extra privileges:
[PolicyRule{Resources:["pods/log"], APIGroups:[""], Verbs:["get"]}
PolicyRule{Resources:["prowjobs"], APIGroups:["prow.k8s.io"], Verbs:["get"]}
APIGroups:["prow.k8s.io"], Verbs:["list"]}] user=&{<CLUSTER_USER>
[system:authenticated] map[]}...
Run the previous command substituting USER with CLUSTER_USER from the error
message above to solve this issue.
$ kubectl create clusterrolebinding cluster-admin-binding-"<CLUSTER_USER>" \
--clusterrole=cluster-admin --user="<CLUSTER_USER>"
There are relevant docs on Kubernetes Authentication that may help if neither of the above work.
Create the GitHub secrets
You will need two secrets to talk to GitHub. The hmac-token is the token that
you give to GitHub for validating webhooks. Generate it using any reasonable
randomness-generator, eg openssl rand -hex 20.
$ openssl rand -hex 20 > /path/to/hook/secret
$ kubectl create secret -n prow generic hmac-token --from-file=hmac=/path/to/hook/secret
Afterwards, edit your GitHub app and set Webhook secret to the value of /path/to/hook/secret.
The github-token is the RSA private key and app id you created above for the GitHub App.
kubectl create secret -n prow generic github-token --from-file=cert=/path/to/github/cert --from-literal=appid=<<The ID of your app>>
Update the sample manifest
There are three sample manifests to get you started:
starter-s3.yamlsets up a minio as blob storage for logs and is particularly well suited to quickly get something working. NOTE: this method requires 2 PVs of 100Gi each.starter-gcs.yamluses GCS as blob storage and requires additional configuration to set up the bucket and ServiceAccounts. See this for details.starter-azure.yamluses Azure as blob storage and requires MinIO deployment. See this for details.
Note: It will deploy prow in the prow namespace of the cluster.
Regardless of which object storage you choose, the below adjustments are always needed:
- The GitHub app cert by replacing the
$GITHUB_TOKENstring - The GitHub app id by replacing the
$GITHUB_APP_IDstring - The hmac token by replacing the
$HMAC_TOKENstring - The domain by replacing the
$PROW_HOSTstring - Optionally, you can update the
cert-manager.io/cluster-issuer:annotation if you use cert-manager - Your GitHub organization(s) by replacing the
$GITHUB_ORGstring
Add the prow components to the cluster
First you need to create the ProwJob custom resource:
kubectl apply --server-side=true -f config/prow/cluster/prowjob-crd/prowjob_customresourcedefinition.yaml
Apply the manifest you edited above by executing one of the following three commands:
kubectl apply -f config/prow/cluster/starter/starter-s3.yamlkubectl apply -f config/prow/cluster/starter/starter-gcs.yamlkubectl apply -f config/prow/cluster/starter/starter-azure.yaml
Note that some of the values, such as $GITHUB_TOKEN, are sensitive and should not be checked in version control;
instead, you can e.g. assign them to environments variables and substitute dynamically:
export GITHUB_TOKEN=<your GitHub token>
...
envsubst < starter-azure.yaml | kubectl apply -f -
After a moment, the cluster components will be running.
$ kubectl get pods -n prow
NAME READY STATUS RESTARTS AGE
crier-69b6bd8f48-6sg24 1/1 Running 0 9m54s
deck-7f6867c46c-j7nnh 1/1 Running 0 2m5s
deck-7f6867c46c-mkxzk 1/1 Running 0 2m5s
ghproxy-fdd45dfb6-582fh 1/1 Running 0 9m54s
hook-7cc4df66f7-r2qpl 1/1 Running 1 9m53s
hook-7cc4df66f7-shnjq 1/1 Running 1 9m53s
horologium-7976c7f597-ss86t 1/1 Running 0 9m53s
minio-d756b6477-d4w4k 1/1 Running 0 9m53s
prow-controller-manager-657767bb69-5qzhp 1/1 Running 0 9m53s
sinker-8b645d469-jjw8r 1/1 Running 0 9m53s
statusreconciler-669697d466-zqfsj 1/1 Running 0 3m11s
tide-65489c49b8-rpnn2 1/1 Running 0 3m2s
Get ingress IP address
Find out your external address. It might take a couple of minutes for the IP to show up.
kubectl get ingress -n prow prow
NAME CLASS HOSTS ADDRESS PORTS AGE
prow <none> prow.<<your-domain.com>> an.ip.addr.ess 80, 443 22d
Go to that address in a web browser and verify that the “echo-test” job has a green check-mark next to it. At this point you have a prow cluster that is ready to start receiving GitHub events!
Add the webhook to GitHub
To set up the webhook, you have to go the GitHub UI and edit your app. Update
the Webhook URL property to https://prow.<<your-domain.com>>/hook. Use the URL
shown above when getting the Ingress and fill in the Webhook secret using the value
in the hmac-token secret created earlier.
Install Prow for a GitHub organization or repo
To install Prow for an org or repo, go to your GitHub app -> Install app and select the organizations to
install the app in. If you want to install the app in other accounts than the one that created it, you need
to make it public. To do so, go to Advanced -> Make this GitHub app public. After it is public, everyone
can install it (Prow will not do anything for orgs or repos it doesn’t have configuration for though).
Deploying with GitHub Enterprise
When using GitHub Enterprise (GHE), Prow must be configured slightly differently. It’s possible to run GHE with or
without the api subdomain:
- with the
apisubdomain the endpoints are:- v3:
https://api.<<github-hostname>> - graphql:
https://api.<<github-hostname>>/graphql
- v3:
- without the
apisubdomain the endpoints are:- v3:
https://<<github-hostname>>/api/v3 - graphql:
https://<<github-hostname>>/api/graphql
- v3:
Prow component configuration:
-
ghproxy:- configure arg:
--upstream=<<v3-endpoint>> - the
ghproxywill not be able to proxy graphql requests when GHE is not using theapisubdomain (because it tries to use the wrong context path for graphql)
- configure arg:
-
crier,deck,hook,status-reconciler,tide,prow-controller-manager:- configure args:
--github-endpoint=http://ghproxy--github-endpoint=<<v3-endpoint>>- with
apisubdomain:--github-graphql-endpoint=http://ghproxy/graphql
- without
apisubdomain:--github-graphql-endpoint=<<graphql-endpoint>>
- configure args:
-
deck,hook,tide,prow-controller-manager:- configure arg:
--github-host=<<github-hostname>>
- configure arg:
Prow global configuration (config.yaml):
- configure
github.link_url: "https://<<github-hostname>>"
ProwJob configuration:
- ensure that
clone_uriandpath_aliasare always set:clone_uri:https://<<github-hostname>>/<<org>>/<<repo>>.gitpath_alias:<<github-hostname>>/<<org>>/<<repo>>
- it might be necessary to configure
plank.default_decoration_config_entries[].ssh_host_fingerprints
Next Steps
You now have a working Prow cluster (Woohoo!), but it isn’t doing anything interesting yet. This section will help you complete any additional setup that your instance may need.
Configure an Azure blob storage
If you want to persist logs and output in Azure, you need to follow the steps below.
By default, Prow doesn’t support Azure blob storage for storing job metadata, logs, and artifacts. However, with MinIO it is possible to keep artifacts in Azure blob storage as one would in GCS or S3. MinIO Gateway adds Amazon S3 compatibility to Azure Blob Storage. As such, we can mimic S3 storage for Prow, while actually pushing artifacts to the Azure storage. To run MinIO in gateway mode with Azure being the backend storage, we need to pass the following arguments to MinIO deployment:
args:
- gateway # mode of MinIO
- azure # storage provider
- --console-address=:"<<CHANGE_ME_MINIO_CONSOLE_PORT>>" # predictable port number of the web console. E.g. 33333
In order to configure the Azure storage, follow the following steps:
- create a storage account.
- update MinIO deployment and
s3-credentialSecret with your Azure BlobStorage account name and key. - update MinIO deployment and
minio-consolewith your desired port number for accessing its web-console.minio-consoleservice is optional and only necessary if you plan to access MinIO web-console. - create the following containers in
your Azure BlobStorage account where Prow will push various artifacts:
prow-logsstatus-reconcilertide
- apply starter-azure.yaml.
Configure a GCS bucket
If you want to persist logs and output in GCS, you need to follow the steps below.
When configuring Prow jobs to use the Pod utilities
with decorate: true, job metadata, logs, and artifacts will be uploaded
to a GCS bucket in order to persist results from tests and allow for the
job overview page to load those results at a later point. In order to run
these jobs, it is required to set up a GCS bucket for job outputs. If your
Prow deployment is targeted at an open source community, it is strongly
suggested to make this bucket world-readable.
In order to configure the bucket, follow the following steps:
- provision a new service account for interaction with the bucket
- create the bucket
- (optionally) expose the bucket contents to the world
- grant access to admin the bucket for the service account
- Either use a Kubernetes service account bound to the GCP service account (recommended on GKE):
- Create a Kubernetes service account in the namespace where jobs will run.
- Bind the Kubernetes service account to the GCP service account.
- edit the
plankconfiguration fordefault_decoration_config_entries[].config.default_service_account_nameto point to the Kubernetes service account.
- OR use a GCP service account key file:
- serialize a key for the service account
- upload the key to a
Secretunder theservice-account.jsonkey - edit the
plankconfiguration fordefault_decoration_config_entries[].config.gcs_credentials_secretto point to theSecretabove
After downloading the gcloud tool and authenticating,
the following collection of commands will execute the above steps for you:
You will need to change the bucket name from
gs://your-bucket-name/to a globally unique one and use that instead instarter-gcs.yamltoo.
$ gcloud iam service-accounts create prow-gcs-publisher
$ identifier="$(gcloud iam service-accounts list --filter 'name:prow-gcs-publisher' --format 'value(email)')"
$ gsutil mb gs://your-bucket-name/ # step 2
$ gsutil iam ch allUsers:objectViewer gs://your-bucket-name # step 3
$ gsutil iam ch "serviceAccount:${identifier}:objectAdmin" gs://your-bucket-name # step 4
$ gcloud iam service-accounts keys create --iam-account "${identifier}" service-account.json # step 5
$ kubectl -n test-pods create secret generic gcs-credentials --from-file=service-account.json # step 6
$ kubectl -n prow create secret generic gcs-credentials --from-file=service-account.json # this secret is also needed by deployments in the prow namespace
Configure the version of plank’s utility images
Before we can update plank’s default_decoration_config_entries[] we’ll need to retrieve the version of plank. Check the deployment file or use the following:
$ kubectl get pod -n prow -l app=plank -o jsonpath='{.items[0].spec.containers[0].image}' | cut -d: -f2
v20191108-08fbf64ac
Then, we can use that tag to retrieve the corresponding utility images in default_decoration_config_entries[] in config.yaml:
For more information on how the pod utility images for prow are versioned see generic-autobumper and the autobump config used for prow.k8s.io
plank:
default_decoration_config_entries:
- config:
utility_images: # using the tag we identified above
clonerefs: "gcr.io/k8s-prow/clonerefs:v20191108-08fbf64ac"
initupload: "gcr.io/k8s-prow/initupload:v20191108-08fbf64ac"
entrypoint: "gcr.io/k8s-prow/entrypoint:v20191108-08fbf64ac"
sidecar: "gcr.io/k8s-prow/sidecar:v20191108-08fbf64ac"
gcs_configuration:
bucket: prow-artifacts # the bucket we just made
path_strategy: explicit
gcs_credentials_secret: gcs-credentials # the secret we just made
Adding more jobs
There are two ways to configure jobs:
- Using the inrepoconfig feature to configure jobs inside the repo under test
- Using the static config by editing the
configconfigmap, some samples below:
Add the following to config.yaml:
periodics:
- interval: 10m
name: echo-test
decorate: true
spec:
containers:
- image: alpine
command: ["/bin/date"]
postsubmits:
YOUR_ORG/YOUR_REPO:
- name: test-postsubmit
decorate: true
spec:
containers:
- image: alpine
command: ["/bin/printenv"]
presubmits:
YOUR_ORG/YOUR_REPO:
- name: test-presubmit
decorate: true
always_run: true
skip_report: true
spec:
containers:
- image: alpine
command: ["/bin/printenv"]
Again, run the following to test the files, replacing the paths as necessary:
$ go run ./cmd/checkconfig --plugin-config=path/to/plugins.yaml --config-path=path/to/config.yaml
Now run the following to update the configmap.
$ kubectl create configmap -n prow config \
--from-file=config.yaml=path/to/config.yaml --dry-run=server -o yaml | kubectl replace configmap -n prow config -f -
We create a make rule:
update-config: get-cluster-credentials
kubectl create configmap -n prow config --from-file=config.yaml=config.yaml --dry-run=server -o yaml | kubectl replace configmap -n prow config -f -
Presubmits and postsubmits are triggered by the trigger plugin. Be sure to
enable that plugin by adding it to the list you created in the last section.
Now when you open a PR it will automatically run the presubmit that you added
to this file. You can see it on your prow dashboard. Once you are happy that it
is stable, switch skip_report in the above config.yaml to false. Then, it will post a status on the
PR. When you make a change to the config and push it with make update-config,
you do not need to redeploy any of your cluster components. They will pick up
the change within a few minutes.
When you push or merge a new change to the git repo, the postsubmit job will run.
For more information on the job environment, see jobs.md
Run test pods in different clusters
You may choose to run test pods in a separate cluster entirely. This is a good practice to keep testing isolated from Prow’s service components and secrets. It can also be used to furcate job execution to different clusters.
One can use a Kubernetes kubeconfig file (i.e. Config object) to instruct Prow components to use the build cluster(s).
All contexts in kubeconfig are used as build clusters and the InClusterConfig (or current-context) is the default.
NOTE: See the create-build-cluster.sh script to help you quickly create and register a GKE cluster as a build cluster for a Prow instance. Continue reading for information about registering a build cluster by hand.
Create a secret containing a kubeconfig like this:
apiVersion: v1
clusters:
- name: default
cluster:
certificate-authority-data: fake-ca-data-default
server: https://1.2.3.4
- name: other
cluster:
certificate-authority-data: fake-ca-data-other
server: https://5.6.7.8
contexts:
- name: default
context:
cluster: default
user: default
- name: other
context:
cluster: other
user: other
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
token: fake-token-default
- name: other
user:
token: fake-token-other
Use gencred to create the kubeconfig file (and credentials) for accessing the cluster(s):
NOTE:
gencredwill merge new entries to the specifiedoutputfile on successive invocations by default .
Create a default cluster context (if one does not already exist):
NOTE: If executing
gencredlike below, ensure--outputis an absolute path.
$ go run ./gencred \
--context=<kube-context> \
--name=default \
--output=/tmp/kubeconfig.yaml \
--serviceaccount
Create one or more build cluster contexts:
NOTE: the
current-contextof the existingkubeconfigwill be preserved.
$ go run ./gencred \
--context=<kube-context> \
--name=other \
--output=/tmp/kubeconfig.yaml \
--serviceaccount
Create a secret containing the kubeconfig.yaml in the cluster:
$ kubectl --context=<kube-context> create secret generic kubeconfig --from-file=config=/tmp/kubeconfig.yaml
Mount this secret into the prow components that need it (at minimum: plank,
sinker and deck) and set the --kubeconfig flag to the location you mount it at. For
instance, you will need to merge the following into the plank deployment:
spec:
containers:
- name: plank
args:
- --kubeconfig=/etc/kubeconfig/config # basename matches --from-file key
volumeMounts:
- name: kubeconfig
mountPath: /etc/kubeconfig
readOnly: true
volumes:
- name: kubeconfig
secret:
defaultMode: 0644
secretName: kubeconfig # example above contains a `config` key
Configure jobs to use the non-default cluster with the cluster: field.
The above example kubeconfig.yaml defines two clusters: default and other to schedule jobs, which we can use as follows:
periodics:
- name: cluster-unspecified
# cluster:
interval: 10m
decorate: true
spec:
containers:
- image: alpine
command: ["/bin/date"]
- name: cluster-default
cluster: default
interval: 10m
decorate: true
spec:
containers:
- image: alpine
command: ["/bin/date"]
- name: cluster-other
cluster: other
interval: 10m
decorate: true
spec:
containers:
- image: alpine
command: ["/bin/date"]
This results in:
- The
cluster-unspecifiedandcluster-defaultjobs run in thedefaultcluster. - The
cluster-otherjob runs in theothercluster.
See gencred for more details about how to create/update kubeconfig.yaml.
Enable merge automation using Tide
PRs satisfying a set of predefined criteria can be configured to be automatically merged by Tide.
Tide can be enabled by modifying config.yaml.
See how to configure tide for more details.
Set up GitHub OAuth
GitHub Oauth is required for PR Status
and for the rerun button on Prow Status.
To enable these features, follow the
instructions in github_oauth_setup.md.
Configure SSL
Use cert-manager for automatic LetsEncrypt integration. If you already have a cert then follow the official docs to set up HTTPS termination. Promote your ingress IP to static IP. On GKE, run:
$ gcloud compute addresses create [ADDRESS_NAME] --addresses [IP_ADDRESS] --region [REGION]
Point the DNS record for your domain to point at that ingress IP. The convention
for naming is prow.org.io, but of course that’s not a requirement.
Then, install cert-manager as described in its readme. You don’t need to run it in a separate namespace.
Further reading
9 - Developing and Contributing to Prow
Contributing
Please consider upstreaming any changes or additions you make! Contributions in any form (issues, pull requests, even constructive comments in discussions) are more than welcome! You can develop in-tree for more help and review, or out-of-tree if you need to for whatever reason. If you upstream a new feature or a change that impacts the default behavior of Prow, consider adding an announcement about it and dropping an email at the sig-testing mailing list.
New Contributors should search for issues in kubernetes/test-infra with the help-wanted and/or good first issue labels. (Query link). Before starting work please ensure that the issue is still active and then provide a short design overview of your planned solution.
Also reach out on the Kubernetes slack in the sig-testing channel.
Prow Integration Points
There are a number of ways that you can write code for Prow or integrate existing code with Prow.
Plugins
Prow plugins are sub-components of the hook binary that register event handlers for various types of GitHub events.
Plugin event handlers are provided a PluginClient that provides access to a suite of clients and agents for configuration, ProwJobs, GitHub, git, OWNERS file, Slack, and more.
How to add new plugins
Add a new package under plugins with a method satisfying one of the handler
types in plugins. In that package’s init function, call
plugins.Register*Handler(name, handler). Then, in hook/plugins.go, add an
empty import so that your plugin is included. If you forget this step then a
unit test will fail when you try to add it to plugins.yaml. Don’t add a brand
new plugin to the main kubernetes/kubernetes repo right away, start with
somewhere smaller and make sure it is well-behaved.
The lgtm plugin is a good place to start if you’re looking for an example
plugin to mimic.
External plugins
For even more flexibility, anything that receives GitHub webhooks can be configured to be forwarded webhooks as an external plugin. This allows in-cluster or out of cluster plugins and forwarding to other bots or infrastructure.
Cluster Deployments
Additional cluster components can use the informer framework for ProwJobs in order to react to job creation, update, and deletion.
This can be used to implement additional job execution controllers for executing job with different agents. For example, jenkins-operator executes jobs on jenkins, plank uses kubernetes pods, and build uses the build CRD.
The informer framework can also be used to react to job completion or update in order to create an alternative job reporting mechanism.
Artifact Viewers
Spyglass artifact viewers allow for custom display of ProwJob artifacts that match a certain file regexp. Existing viewers display logs, metadata, and structured junit results.
ProwJobs
ProwJobs themselves are often a sufficient integration point if you just need to execute a task on a schedule or in reaction to code changes.
Exposed Data
If you just need some data from Prow you may be able to get it from the JSON exposed by Prow’s front end deck, or from Prometheus metrics.
Building, Testing, and Deploying
You can build, test, and deploy Prow’s binaries, container images, and cluster resources. See “Deploying Prow” for initially deploying Prow and “Building, Testing, and Updating Prow” for iterating on an existing deployment.
10 - Getting more out of Prow
If you want more functionality from your Prow instance this guide is for you. It primarily links to other resources that catalogue existing components and features.
Use more Prow components and plugins
Prow has a number of optional cluster components and a suite of plugins for hook that provide all sorts of automation. Check out the Components for a list of cluster components and the Plugins for information about available plugins.
Consume Prometheus metrics
Some Prow components expose prometheus metrics that can be used for monitoring, alerting, and pretty graphs. You can find details in the Metrics document.
Make Prow update and deploy itself
You can easily make your Prow instance automatically update itself when changes
are made to its component’s kubernetes resource files. This is achieved with a
postsubmit job that kubectl applys the resource files whenever they are
changed (based on a run_if_changed or skip_if_only_changed regexp). In
order to kubectl apply to the cluster, the job will need to supply credentials
(e.g. a kubeconfig file or
GCP service account key-file). Since
this job requires priviledged credentials to deploy to the cluster, it is
important that it is run in a separate build cluster that is isolated from all
presubmit jobs. See the
documentation about separate build clusters
for details. An example of such a job can be found
here.
Once you have a postsubmit deploy job, any changes to Prow component files are
automatically applied to the cluster when the changes merge. In order to ensure
that all changes to production are properly approved, you can use OWNERS files
with the approve plugin and Tide.
With the help of the Prow Autobump utility you can easily create commits that update all references to Prow images to the latest image version that has been vetted by the https://prow.k8s.io instance. If your Prow component resource files live in GitHub, this utility can even automatically create/update a Pull Request that includes these changes. This works great when run as a periodic job since it will maintain a single open PR that is periodically updated to reference the most recent upstream version. See the config used to bump prow.k8s.io for an example
Combining a postsubmit deploy job with a periodic job that runs the Prow Autobump utility allows Prow to be updated to the latest version by simply merging the automatically created Pull Request (or letting Tide merge it after it has been approved).
Deploy config changes automatically
Prow can also automatically upload changes to files that correspond to Kubernetes ConfigMaps. This includes its own config, plugins and job-config config maps. Take a look at the updateconfig plugin and config-bootstrapper for more details. Both of these tools share the updateconfig plugin’s plugin configuration. The plugin provides slightly better GitHub integration and is simpler to enable, but the config-bootstrapper is more flexible. It can be run in a postsubmit job to provide config upload on non-GitHub Prow instances or run after custom config generation is executed.
Use other tools with Prow
- If you find that your GitHub bot is running low on API tokens consider using
ghproxyto cache requests to GitHub and take advantage of the strange re-validation rules that allow for additional API token savings. - Testgrid provides a highly configurable visual overview of test results and can be configured to send alerts for failing or stale results. Testgrid is in the process of being open sourced, but until it has completely made the switch OSS users will need to use the https://testgrid.k8s.io instance that is managed by the GKE-Engprod team.
- Kind lets you run an entire Kubernetes cluster in a container. This makes it fast and easy for ProwJobs to test anything that runs on Kubernetes (or Kubernetes itself).
- label_sync maintains GitHub labels across orgs and repos based on yaml configuration.
Handle scale
If your Prow instance operates on a lot of GitHub repos or runs lots of jobs you should review the “Scaling Prow” guide for tips and best practices.
Private Front end
If you want to create a private Deck instnace that contains a subset of prowjobs, you should review the “Private Deck” guide.
11 - GitHub API Library
This GitHub API library is used by multiple parts of Prow. It uses both v3 and v4 of GitHub’s API. It is subject to change as needed without notice, but you can reuse and extend it within this repository.
Its primary component is client.go, a GitHub client that sends and receives API calls.
Recommended Usage
Instantiation
An application that takes flags may want to set GitHub flags, such as a proxy endpoint. To do that, GitHubOptions has a method that returns a GitHub client.
If you’re not using flags, you can instantiate a client with the NewClient and
NewClientWithFields methods
Interfacing a Subset of Client
This client has a lot of functions listed in the interfaces of client.go. Further, these interfaces may change at any time. To avoid having to extend the entire interface, we recommend writing a local interface that uses the functionality you need.
For example, if you only need to get and edit issues, you might write an interface like the following:
type githubClient interface {
GetIssue(org, repo string, number int) (*github.Issue, error)
EditIssue(org, repo string, number int, issue *github.Issue) (*github.Issue, error)
}
The provided fake works like this; FakeClient doesn’t completely implement Client, but gives many common functions used in testing.
12 - ghProxy
ghProxy is a reverse proxy HTTP cache optimized for use with the GitHub API (https://api.github.com). It is essentially just a reverse proxy wrapper around ghCache with Prometheus instrumentation to monitor disk usage.
ghProxy is designed to reduce API token usage by allowing many components to share a single ghCache.
with Prow
While ghProxy can be used with any GitHub API client, it was designed for Prow. Prow’s GitHub client request throttling is optimized for use with ghProxy and doesn’t count requests that can be fulfilled with a cached response against the throttling limit.
Many Prow features (and soon components) require ghProxy in order to avoid rapidly consuming the API rate limit. Direct your Prow components that use the GitHub API (anything that requires the GH token secret) to use ghProxy and fall back to using the upstream API by adding the following flags:
--github-endpoint=http://ghproxy # Replace this as needed to point to your ghProxy instance.
--github-endpoint=https://api.github.com
Deploying
A new container image is automatically built and published to gcr.io/k8s-prow/ghproxy whenever this directory is changed on the master branch. You can find a recent stable image tag and an example of how to deploy ghProxy to Kubernetes by checking out Prow’s ghProxy deployment.
Throttling algorithm
To prevent hitting GH API secondary rate limits, an additional ghProxy throttling algorithm can be configured and used. It is described here.
12.1 - ghCache
What?
ghCache is an HTTP cache optimized for caching responses from the GitHub API (https://api.github.com). Specifically, it has the following non-standard caching behavior:
- Every cache hit is revalidated with a conditional HTTP request to GitHub regardless of cache entry freshness (TTL). The ‘Cache-Control’ header is ignored and overwritten to achieve this.
- Concurrent requests for the same resource are coalesced and share a single request/response from GitHub instead of each request resulting in a corresponding upstream request and response.
ghCache also provides prometheus instrumentation to expose cache activity, request duration, and API token usage/savings.
Why?
The most important behavior of ghCache is the mandatory cache entry revalidation. While this property would cause most API caches to use tokens excessively, in the case of GitHub, we can actually save API tokens. This is because conditional requests for unchanged resources don’t cost any API tokens!!! See: https://docs.github.com/en/rest/overview/resources-in-the-rest-api#conditional-requests Free revalidation allows us to ensure that every request is satisfied with the most up to date resource without actually spending an API token unless the resource has been updated since we last checked it.
Request coalescing is beneficial for use cases in which the same resource is requested multiple times in rapid succession. Normally these requests would each result in an upstream request to GitHub, potentially costing API tokens, but with request coalescing at most one token is used. This particularly helps when many handlers react to the same event like in Prow’s hook component.
12.2 - Additional throttling algorithm
Motivation
An additional throttling algorithm was introduced to ghproxy to prevent secondary rate
limiting issues (code 403) in large Prow installations, consisting of several organizations.
Its purpose is to schedule incoming requests to adjust to the GitHub general rate-limiting
guidelines.
Implementation
An incoming request is analyzed whether it is targeting GitHub API v3 or API v4.
Separate queues are formed not only per API but also per organization if Prow installation is
using GitHub Apps. If a user account in a form of the bot is used, every request coming
from that user account is categorized as coming from the same organization. This is due to
the fact, that such a request identifies not using AppID and organization name, but sha256 token hash.
There is a possibility to apply different throttling times per API version.
In the situation of a very high load, the algorithm prefers hitting secondary rate limits instead of forming a massive queue of throttled messages, thus default max waiting time in a queue is introduced. It is 30 seconds.
Flags
Flags --throttling-time-ms and --get-throttling-time-ms have to be set to a non-zero value,
otherwise, additional throttling mechanism will be disabled.
All available flags:
throttling-time-msenables a throttling mechanism which imposes time spacing between outgoing requests. Counted per organization. Has to be set together with--get-throttling-time-ms.throttling-time-v4-msis the same flag as above, but when set applies a separate time spacing for API v4.get-throttling-time-msallows setting different time spacing for API v3GETrequests.throttling-max-delay-duration-secondsandthrottling-max-delay-duration-v4-secondsallow setting max throttling time for respectively API v3 and API v4. The default value is 30. They are present to prefer hitting secondary rate limits, instead of forming massive queues of messages during periods of high load.request-timeoutrefers to request timeout which applies also to paged requests. The default is 30 seconds. You may consider increasing it ifthrottling-max-delay-duration-secondsandthrottling-max-delay-duration-v4-secondsare modified.
Example configuration
Args from ghproxy configuration YAML file:
...
args:
- --cache-dir=/cache
- --cache-sizeGB=10
- --legacy-disable-disk-cache-partitions-by-auth-header=false
- --get-throttling-time-ms=300
- --throttling-time-ms=900
- --throttling-time-v4-ms=850
- --throttling-max-delay-duration-seconds=45
- --throttling-max-delay-duration-v4-seconds=110
- --request-timeout=120
- --concurrency=1000 # rely only on additional throttling algorithm and "disable" the previous solution
...
Metrics
Impact and the results after applying additional throttling can be consulted using two
ghproxy Prometheus metrics:
github_request_durationto consult returned status codes across user agents and paths.github_request_wait_duration_secondsto consult the status and waiting times of the requests handled by the throttling algorithm.
Both metrics are histogram type.
13 - Inrepoconfig
Inrepoconfig is a Prow feature that allows versioning Presubmit and Postsubmit
jobs in the same repository that also holds the code (with a .prow directory
or .prow.yaml file, akin to a .travis.yaml file). So instead of having all
your jobs defined centrally, you could instead define the jobs in a distributed
manner, coupled closely with the source code repos that they work on.
If enabled, Prow will use both the centrally-defined jobs and the ones defined in the code repositories. The latter ones are dynamically loaded on-demand.
Why use Inrepoconfig?
Pros
- Coupling the jobs with the source code allows you to update both the job and the source code at the same time.
Cons
- Inrepoconfig jobs are loaded on-demand, so it takes some extra setup to check that a misconfigured Inrepoconfig job is not blocking a PR. See “Config verification job” below.
Basic usage
To enable it, add the following to your Prow’s config.yaml:
in_repo_config:
enabled:
# The key can be one of "*" for "globally", "org" or "org/repo".
# The narrowest match is used. Here the key is "kubernetes/kubernetes".
kubernetes/kubernetes: true
# Clusters must be allowed before they can be used. Here we allow the "default"
# cluster globally. This setting also allows using "*" for "globally", "org" or "org/repo" as key.
# All clusters that are allowed for the specific repo, its org or
# globally can be used.
allowed_clusters:
"*": ["default"]
Additionally, Deck must be configured with a GitHub token if that is not already the case. To do
so, the --github-token-path= flag must be set and point to a valid token file that has permissions
to read all your repositories. Also, in order for Deck to serve content from storage locations not
defined in the default locations or centrally-defined jobs, those buckets must be listed
in deck.additional_allowed_buckets.
Config verification job
Afterwards, you need to add a config verification job to make sure people people get told about
mistakes in their Inrepoconfig rather than the PR being stuck. It makes sense to define this
job in the central repository rather than the code repository, so the checkconfig version used
stays in sync with the Prow version used. It looks like this:
presubmits:
kubernetes/kubernetes:
- name: pull-kubernetes-validate-prow-yaml
always_run: true
decorate: true
extra_refs:
- org: kubernetes
repo: test-infra
base_ref: master
spec:
containers:
- image: gcr.io/k8s-prow/checkconfig:v20221220-5c7fbe528a
command:
- /ko-app/checkconfig
args:
- --plugin-config=../test-infra/path/to/plugins.yaml
- --config-path=../test-infra/path/to/config.yaml
- --prow-yaml-repo-name=$(REPO_OWNER)/$(REPO_NAME)
After deploying the new config, the only step left is to create jobs. This is done by adding a file
named .prow.yaml to the root of the repository that holds your code:
presubmits:
- name: pull-test-infra-yamllint
always_run: true
decorate: true
spec:
containers:
- image: quay.io/kubermatic/yamllint:0.1
command:
- yamllint
- -c
- config/jobs/.yamllint.conf
- config/jobs
- config/prow/cluster
postsubmits:
- name: push-test-infra-yamllint
always_run: true
decorate: true
spec:
containers:
- image: quay.io/kubermatic/yamllint:0.1
command:
- yamllint
- -c
- config/jobs/.yamllint.conf
- config/jobs
- config/prow/cluster
Multiple config files
It is possible also to use multiple config files with this same format under a .prow
directory in the root of your repo. All the YAML files under the .prow directory will
be read and merged together recursively. This makes it easier to handle big repos with
a large number of jobs and allows fine-grained OWNERS control on them.
The .prow directory and .prow.yaml file are mutually exclusive; when both are present the .prow directory takes precedence.
For more detailed documentation of possible configuration parameters for jobs, please check the job documentation
Symlinks
Symlinks inside the .prow directory that point to outside the directory are
not
supported.
14 - Life of a Prow Job
NOTE: This document uses 5df7636b83cab54e248e550a31dbf1e4731197a6 (July 21, 2021) as a reference point for all code links.
Let’s pretend a user comments /test all on a Pull Request (PR).
In response, GitHub posts this comment to Prow via a webhook.
See examples for webhook payloads.
Prow’s Kubernetes cluster uses an ingress resource for terminating TLS, and routes traffic to the hook service resource, finally sending the traffic to the hook application, which is defined as a deployment:
- This document describes the configuration for the ingress resource.
- This document describes the configuration for the hook service.
- This document defines the pods for the hook application.
The pods for hook run the hook executable.
hook listens for incoming HTTP requests and translates them to “GitHub event objects”.
For example, in the case of the /test all comment from above, hook builds an GenericCommentEvent.
Afterwards, hook broadcasts these events to Prow Plugins.
Prow Plugins receive 2 objects:
- a GitHub event object, and
- a
ClientAgentobject.
The ClientAgent object contains the following clients:
- GitHub client
- Prow job client
- Kubernetes client
- BuildClusterCoreV1 clients
- Git client
- Slack client
- Owners client
- Bugzilla client
- Jira client
These clients are initialized by hook, during start-up.
hook handles events by looking at X-GitHub-Event, a custom HTTP header.
Afterwards, a ConfigAgent object, initialized during hook’s startup, selects plugins to handle events.
See githubeventserver.go for more details, and check plugins.yaml for a list of plugins per repo.
Going back to the example, hook delivers an event that represents the /test all comment to the Trigger plugin.
The Trigger plugin validates the PR before running tests.
One such validation is, for instance, that the author is a member of the organization or that the PR is labeled ok-to-test.
The function called handleGenericComment describes Trigger’s logic.
If all conditions are met (ok-to-test, the comment is not a bot comment, etc.), handleGenericComment determines which presubmit jobs to run.
The initial list of presubmit jobs to run (before being filtered down to those that qualify for this particular comment), is retrieved with getPresubmits.
Next, for each presubmit we want to run, the trigger plugin talks to the Kubernetes API server and creates a ProwJob with the information from the PR comment.
The ProwJob is primarily composed of the Spec and Status objects.
Pod details aside, a sample ProwJob might look like this:
apiVersion: prow.k8s.io/v1
kind: ProwJob
metadata:
name: 32456927-35d9-11e7-8d95-0a580a6c1504
spec:
job: pull-test-infra-bazel
decorate: true
pod_spec:
containers:
- image: gcr.io/k8s-staging-test-infra/bazelbuild:latest-test-infra
refs:
base_ref: master
base_sha: 064678510782db5b382df478bb374aaa32e577ea
org: kubernetes
pulls:
- author: ixdy
number: 2716
sha: dc32ccc9ea3672ccc523b7cbaa8b00360b4183cd
repo: test-infra
type: presubmit
status:
startTime: 2017-05-10T23:34:22.567457715Z
state: triggered
prow-controller-manager runs ProwJobs by launching them by creating a new Kubernetes pod. It knows how to schedule new ProwJobs onto the cluster, responding to changes in the ProwJob or cluster health.
When the ProwJob finishes (the containers in the pod have finished running), prow-controller-manager updates the ProwJob.
crier reports back the status of the ProwJob back to the various external services like GitHub (e.g., as a green check-mark on the PR where the original /test all comment was made).
A day later, sinker notices that the job and pod are a day old and deletes them from the Kubernetes API server.
Here is a summary of the above:
- User types in
/test allas a comment into a GitHub PR. - GitHub sends a webhook (HTTP request) to Prow, to the
prow.k8s.io/hookendpoint. - The request gets intercepted by the ingress.
- The ingress routes the request to the hook service.
- The hook service in turn routes traffic to the hook application, defined as a deployment.
- The container routes traffic to the hook binary inside it.
- hook binary parses and validates the HTTP request and creates a GitHub event object.
- hook binary sends the GitHub event object (in this case
GenericCommentEvent) tohandleGenericCommentEvent. handleGenericCommentEventsends the data to be handled by thehandleEvent.- The data in the comment gets sent from hook to one of its many plugins, one of which is trigger. (The pattern is that hook constructs objects to be consumed by various plugins.)
- trigger determines which presubmit jobs to run (because it sees the
/testcommand in/test all). - trigger creates a ProwJob object!
- prow-controller-manager creates a pod to start the ProwJob.
- When the ProwJob’s pod finishes, prow-controller-manager updates the ProwJob.
- crier sees the updated ProwJob status and reports back to the GitHub PR (creating a new comment).
- sinker cleans up the old pod from above and deletes it from the Kubernetes API server.
15 - Prow Configuration
Core Prow component configuration is managed by the config package and stored in the Config struct. If a configuration guide is available for a component it can be found in the “Components” directory. See jobs.md for a guide to configuring ProwJobs.
Configuration for plugins is handled and stored separately. See the plugins package for details.
You can find a sample config with all possible options and a documentation of them here.
16 - Prow Secrets Management
Secrets in prow service/build clusters are managed with Kubernetes External
Secrets, which is responsible for one-way syncing secret values from major
secret manager providers such as GCP, Azure, and AWS secret managers into
kubernetes clusters, based on ExternalSecret custom resource defined in
cluster (As shown in example below).
Note: the instructions below are only for GCP secret manager, for authenticating with other providers please refer to https://github.com/external-secrets/kubernetes-external-secrets#backends
Set Up (Prow maintainers)
This is performed by prow service/build clusters maintainer.
- In the cluster that the secrets are synced to, enable workload identity by
following
workload-identity. - Deploy
kubernetes-external-secrets_crd.yaml,kubernetes-external-secrets_deployment.yaml,kubernetes-external-secrets_rbac.yaml, andkubernetes-external-secrets_service.yamlunderconfig/prow/cluster. The deployment file assumes using the same service account name as used in step #1 - [Optional but recommended] Create postsubmit deploy job for managing the deployment, for example post-test-infra-deploy-prow.
Usage (Prow clients)
This is performed by prow serving/build cluster clients. Note that the GCP project mentioned here doesn’t have to, and normally is not the same GCP project where the prow service/build clusters are located.
-
In the GCP project that stores secrets with google secret manager, grant the
roles/secretmanager.viewerandroles/secretmanager.secretAccessorpermission to the GCP service account used above, by running:gcloud beta secrets add-iam-policy-binding <my-gsm-secret-name> --member="serviceAccount:<same-service-account-for-workload-identity>" --role=<role> --project=<my-gsm-secret-project>The above command ensures that the service account used by prow can only access the secret name
<my-gsm-secret-name>in the GCP project owned by clients. The service account used for prow.k8s.io (akatest-infra-trustedbuild cluster) is defined intrusted_serviceaccounts.yaml, and the secrets are defined inkubernetes_external_secrets.yaml. The service account used fork8s-prow-buildscluster(aka the default build cluster) is defined inbuild_serviceaccounts.yaml, and the secrets are defined inbuild_kubernetes-external-secrets_customresource.yaml. -
Create secret in google secret manager
-
Create kubernetes external secrets custom resource by:
apiVersion: kubernetes-client.io/v1 kind: ExternalSecret metadata: name: <my-precious-secret-kes-name> # name of the k8s external secret and the k8s secret namespace: <ns-where-secret-is-used> spec: backendType: gcpSecretsManager projectId: <my-gsm-secret-project> data: - key: <my-gsm-secret-name> # name of the GCP secret name: <my-kubernetes-secret-name> # key name in the k8s secret version: latest # version of the GCP secret # Property to extract if secret in backend is a JSON object, # remove this line if using the GCP secret value straight property: value
Within 10 seconds (determined by POLLER_INTERVAL_MILLISECONDS envvar on deployment), a secret will be created automatically:
apiVersion: v1
kind: Secret
metadata:
name: <my-precious-secret-kes-name>
namespace: <ns-where-secret-is-used>
data:
<my-kubernetes-secret-name>: <value_read_from_gsm>
The Secret will be updated automatically when the secret value in gsm changed
or the ExternalSecret is changed. when ExternalSecret CR is deleted from the
cluster, the secret will be also be deleted by kubernetes external secret.
(Note: deleting the ExternelSecret CR config from source control doesn’t
result in deletion of corresponding ExternalSecret CR from the cluster as the
postsubmit action only does kubectl apply).
17 - Gerrit
Gerrit is a free, web-based team code collaboration tool.
Related Deployments
Related packages
Client
We have a gerrit-client package that provides a thin wrapper around
andygrunwald/go-gerrit, which is a go client library
for accessing the Gerrit Code Review REST API
You can create a client instance by pass in a map of instance-name:project-ids, and pass in an oauth token path to start the client, like:
projects := map[string][]string{
"foo.googlesource.com": {
"project-bar",
"project-baz",
},
}
c, err := gerrit.NewClient(projects)
if err != nil {
// handle error
}
c.Start(cookiefilePath)
The client will try to refetch token from the path every 10 minutes.
You should also utilize grandmatriarch to generate a token from a
passed-in service account credential.
If you need extra features, feel free to introduce new gerrit API functions to the client package.
Adapter
The adapter package implements a controller that is periodically polling gerrit, and triggering presubmit and postsubmit jobs based on your prow config.
Gerrit Labels
Prow adds the following Labels to Gerrit Presubmits that can be accessed in the container by leveraging the Downward API.
- “prow.k8s.io/gerrit-revision”: SHA of current patchset from a gerrit change
- “prow.k8s.io/gerrit-patchset”: Numeric ID of the current patchset
- “prow.k8s.io/gerrit-report-label”: Gerrit label prow will cast vote on, fallback to CodeReview label if unset
- name: PATHCSET_NUMBER
valueFrom:
fieldRef:
fieldPath: metadata.labels['prow.k8s.io/gerrit-patchset']
Caveat
The gerrit adapter currently does not support gerrit hooks, If you need them, please send us a PR to support them :-)
18 - ProwJobs
For a brief overview of how Prow runs jobs take a look at “Life of a Prow Job”.
For a brief cookbook for jobs intended for prow.k8s.io, please refer to
config/jobs/README.md
Make sure Prow has been deployed correctly:
- The
horologiumcomponent schedules periodic jobs. - The
hookcomponent schedules presubmit and postsubmit jobs, ensuring the repo:- enabled
triggerinplugins.yaml - sends GitHub webhooks to prow.
- enabled
- The
plankcomponent schedules the pod requested by a prowjob. - The
criercomponent reports status back to github.
How to configure new jobs
To configure a new job you’ll need to add an entry into config.yaml.
If you have update-config plugin deployed then the
config will be automatically updated once the PR is merged, else you will need
to run make update-config. This does not require redeploying any binaries,
and will take effect within a few minutes.
Alternatively, the inrepoconfig feature can be used to version Presubmit jobs in the same repository that also contains the code and have Prow load them dynamically. See its documentation for more details.
Prow requires you to have a basic understanding of kubernetes, such that you can define pods in yaml. Please see kubernetes documentation for help here, for example the Pod overview and PodSpec api reference.
Periodic config looks like so (see GoDocs for complete config):
periodics:
- name: foo-job # Names need not be unique, but must match the regex ^[A-Za-z0-9-._]+$
decorate: true # Enable Pod Utility decoration. (see below)
interval: 1h # Anything that can be parsed by time.ParseDuration.
# Alternatively use a cron instead of an interval, for example:
# cron: "05 15 * * 1-5" # Run at 7:05 PST (15:05 UTC) every M-F
extra_refs: # Periodic job doesn't clone any repo by default, needs to be added explicitly
- org: org
repo: repo
base_ref: main
spec: {} # Valid Kubernetes PodSpec.
Postsubmit config looks like so (see GoDocs for complete config):
postsubmits:
org/repo:
- name: bar-job # As for periodics.
decorate: true # As for periodics.
spec: {} # As for periodics.
max_concurrency: 10 # Run no more than this number concurrently.
branches: # Regexps, only run against these branches.
- ^main$
skip_branches: # Regexps, do not run against these branches.
- ^release-.*$
Postsubmits are run by the trigger plugin when a push event happens on a repo, hence they are
configured per-repo. If no branches are specified, then they will run on every push to
every branch on the given repo.
Postsubmit jobs apply run_if_changed and skip_if_only_changed filters based on which
files were modified by the commits included in the specific push event from github.
Presubmit config looks like so (see GoDocs for complete config):
presubmits:
org/repo:
- name: qux-job # As for periodics.
decorate: true # As for periodics.
always_run: true # Run for every PR, or only when requested.
run_if_changed: "qux/.*" # Regexp, only run on certain changed files.
skip_report: true # Whether to skip setting a status on GitHub.
context: qux-job # Status context. Defaults to the job name.
max_concurrency: 10 # As for postsubmits.
spec: {} # As for periodics.
branches: [] # As for postsubmits.
skip_branches: [] # As for postsubmits.
trigger: "(?m)qux test this( please)?" # Regexp, see discussion.
rerun_command: "qux test this please" # String, see discussion.
Presubmit jobs are run for pull requests by the trigger plugin.
The trigger is a regexp that matches the rerun_command. Users will be told
to input the rerun_command when they want to rerun the job. Actually, anything
that matches trigger will suffice. This is useful if you want to make one
command that reruns all jobs. If unspecified, the default configuration makes
/test <job-name> trigger the job.
See the Triggering Jobs section below to learn how to
control when jobs are automatically run. We also have sections about posting
and requiring GitHub status contexts. A useful
pattern when adding new jobs is to start with always_run set to false and
skip_report set to true. Test it out a few times by manually triggering,
then switch always_run to true. Watch for a couple days, then switch
skip_report to false.
Presubmit jobs apply run_if_changed and skip_if_only_changed filters based on which
files were modified in any of the commits in the pull request.
Presets
Presets can be used to define commonly reused values for a subset of fields
for PodSpecs and BuildSpecs. A preset config looks like:
presets:
- labels: # a job with these labels/values will have the preset applied
preset-foo-bar: "true" # key:value pair must be unique among presets
env: # list of valid Kubernetes EnvVars
- name: FOO
value: BAR
volumes: # list of valid Kubernetes Volumes
- name: foo
emptyDir: {}
- name: bar
secret:
secretName: bar
volumeMounts: # list of valid Kubernetes VolumeMounts
- name: foo
mountPath: /etc/foo
- name: bar
mountPath: /etc/bar
readOnly: true
And to use the preset, add corresponding label in prow job definition like:
- name: obfsucated-job-with-mysteriously-hidden-side-effects
labels:
preset-foo-bar: "true"
Alternatively, annonymous presets can be applied to all jobs, the config looks like:
- env: # a preset with no labels is applied to all jobs
- name: BAZ
value: qux
volumes:
# etc...
volumeMounts:
# etc...
Standard Triggering and Execution Behavior for Jobs
When configuring jobs, it is necessary to keep in mind the set of rules Prow has for triggering jobs, the GitHub status contexts that those jobs provide, and the rules for protecting those contexts on branches.
Triggering Jobs
Trigger Types
prow will consider three different types of jobs that run on pull requests
(presubmits):
- jobs that run unconditionally and automatically. All jobs that set
always_run: truefall into this set. - jobs that run conditionally, but automatically. All jobs that set
run_if_changedorskip_if_only_changedto some value fall into this set. - jobs that run conditionally, but not automatically. All jobs that set
always_run: falseand do not setrun_if_changed/skip_if_only_changedto any value fall into this set and require a human to trigger them with a command.
By default, jobs fall into the third category and must have their always_run,
run_if_changed, or skip_if_only_changed configured to operate differently.
In the rest of this document, “a job running unconditionally” indicates that the job will run even if it is normally conditional and the conditions are not met. Similarly, “a job running conditionally” indicates that the job runs if all of its conditions are met.
Triggering Jobs Based On Changes
Jobs that set always_run: false may be configured to run conditionally based
on the contents of the pull request. run_if_changed and
skip_if_only_changed accept a (Golang-style) regular expression which is
run against the path of each changed file.
run_if_changed triggers the job if any path matches. For example, you may
wish to trigger a compilation job if the pull request changes any *.c or
*.h file, or the Makefile:
presubmits:
org/repo:
- name: compile-job
always_run: false
run_if_changed: "(\\.[ch]|^Makefile)$"
...
skip_if_only_changed skips the job if all paths match. For example, you
may wish to skip a compilation job for pull requests that only change
documentation files:
presubmits:
org/repo:
- name: compile-job
always_run: false
skip_if_only_changed: "^docs/|\\.(md|adoc)$|^(README|LICENSE)$"
Both of the above examples would trigger on a pull request containing
foo/bar.c and SECURITY.md, but not one containing only SECURITY.md.
Note:
run_if_changedandskip_if_only_changedare mutually exclusive.- Jobs which would otherwise be skipped based on this configuration can still be triggered explicitly with comments (see below).
- Only presubmit and postsubmit jobs are inherently associated with git refs and can use these fields.
Triggering Jobs With Comments
A developer may trigger presubmits by posting a comment to a pull request that contains one or more of the following phrases:
/test job-name: When posting/test job-name, any jobs with matching triggers will be triggered unconditionally./retest: When posting/retest, two types of jobs will be triggered:- all jobs that have run and failed will run unconditionally
- any not-yet-executed automatically run jobs will run conditionally
/test all: When posting/test all, all automatically run jobs will run conditionally.
Note: It is possible to configure a job’s trigger to match any of the above keywords
(/retest and/or /test all) but this behavior is not suggested as it will confuse
developers that expect consistent behavior from these commands. More generally, it is
possible to configure a job’s trigger to match any command that is otherwise known
to Prow in some other context, like /close. It is similarly not suggested to do this.
Posting GitHub Status Contexts
Presubmit and postsubmit jobs post a status context to the GitHub
commit under test once they start, unless the job is configured
with skip_report: true.
Use a /retest or /test job-name to re-trigger the test and
hopefully update the failed context to passing.
If a job should no longer trigger on the pull request, use the
/skip command to dismiss a failing status context (depends on
skip plugin).
Repo administrators can also /override job-name in case of emergency
(depends on the override plugin).
Requiring Job Statuses
Requiring Jobs for Auto-Merge Through Tide
Tide will treat jobs in the following manner for merging:
- unconditionally run jobs with required status contexts are always required to have passed on a pull request to merge
- conditionally run jobs with required status contexts are required to have passed on a pull request to merge if the job currently matches the pull request.
- jobs with optional status contexts are ignored when merging
In order to set a job’s context to be optional, set optional: true on the job. If it
is required to not post the results of the job to GitHub whatsoever, the job may be set
to be optional and silent by setting skip_report: true. It is valid to set both of
these options at the same time.
Protecting Status Contexts
The branch protection rules will only enforce the presence of jobs that run unconditionally and have required status contexts. As conditionally-run jobs may or may not post a status context to GitHub, they cannot be required through this mechanism.
Running a ProwJob in a Build Cluster
ProwJobs that execute as Kubernetes resources (namely agent: kubernetes jobs that run as Pods, the default value) can specify a cluster: build-cluster-name field as part of the ProwJob config to specify that the job should be run in a build cluster other than the default build cluster.
periodics:
- name: periodic-cluster-a
cluster: cluster-a
...
presubmits:
org/repo:
- name: presubmit-cluster-b
cluster: cluster-b
...
postsubmits:
org/repo:
- name: postsubmit-default-cluster
# cluster field omitted or set to "default"
...
You can learn more about creating and using build clusters in “Using Prow at Scale” and “Deploying Prow”.
Pod Utilities
If you are adding a new job that will execute on a Kubernetes cluster (agent: kubernetes, the default value) you should consider using the Pod Utilities. The pod utils decorate jobs with additional containers that transparently provide source code checkout and log/metadata/artifact uploading to GCS.
Job Environment Variables
Prow will expose the following environment variables to your job. If the job runs on Kubernetes, the variables will be injected into every container in your pod, If the job is run in Jenkins, Prow will supply them as parameters to the build.
| Variable | Periodic | Postsubmit | Batch | Presubmit | Description | Example |
|---|---|---|---|---|---|---|
CI |
✓ | ✓ | ✓ | ✓ | Represents whether the current environment is a CI environment | true |
ARTIFACTS |
✓ | ✓ | ✓ | ✓ | Directory in which to place files to be uploaded when the job completes | /logs/artifacts |
JOB_NAME |
✓ | ✓ | ✓ | ✓ | Name of the job. | pull-test-infra-bazel |
JOB_TYPE |
✓ | ✓ | ✓ | ✓ | Type of job. | presubmit |
JOB_SPEC |
✓ | ✓ | ✓ | ✓ | JSON-encoded job specification. | see below |
BUILD_ID |
✓ | ✓ | ✓ | ✓ | Unique build number for each run. | 12345 |
PROW_JOB_ID |
✓ | ✓ | ✓ | ✓ | Unique identifier for the owning Prow Job. | 1ce07fa2-0831-11e8-b07e-0a58ac101036 |
REPO_OWNER |
✓ | ✓ | ✓ | GitHub org that triggered the job. | kubernetes |
|
REPO_NAME |
✓ | ✓ | ✓ | GitHub repo that triggered the job. | test-infra |
|
PULL_BASE_REF |
✓ | ✓ | ✓ | Ref name of the base branch. | master |
|
PULL_BASE_SHA |
✓ | ✓ | ✓ | Git SHA of the base branch. | 123abc |
|
PULL_REFS |
✓ | ✓ | ✓ | All refs to test. | master:123abc,5:qwe456 |
|
PULL_NUMBER |
✓ | Pull request number. | 5 |
|||
PULL_PULL_SHA |
✓ | Pull request head SHA. | qwe456 |
|||
PULL_HEAD_REF |
✓ | Pull request branch name. | fixup-some-stuff |
|||
PULL_TITLE |
✓ | Pull request title. | Add something |
Examples of the JSON-encoded job specification follow for the different job types:
Periodic Job:
{"type":"periodic","job":"job-name","buildid":"0","prowjobid":"uuid","refs":{}}
Postsubmit Job:
{"type":"postsubmit","job":"job-name","buildid":"0","prowjobid":"uuid","refs":{"org":"org-name","repo":"repo-name","base_ref":"base-ref","base_sha":"base-sha"}}
Presubmit Job:
{"type":"presubmit","job":"job-name","buildid":"0","prowjobid":"uuid","refs":{"org":"org-name","repo":"repo-name","base_ref":"base-ref","base_sha":"base-sha","pulls":[{"number":1,"author":"author-name","sha":"pull-sha","title":"pull-title","head_ref":"pull-branch"}]}}
Batch Job:
{"type":"batch","job":"job-name","buildid":"0","prowjobid":"uuid","refs":{"org":"org-name","repo":"repo-name","base_ref":"base-ref","base_sha":"base-sha","pulls":[{"number":1,"author":"author-name","sha":"pull-sha"},{"number":2,"author":"other-author-name","sha":"second-pull-sha"}]}}
Testing a new job
Badges
Prow can display badges that signal whether jobs are passing (example).
{kind=link}
The format to send your deck URL is /badge.svg?jobs=single-job-name or /badge.svg?jobs=common-job-prefix-*.
19 - Setting up Private Deck
1) [User] Create a PR to Set up TenantIDs for prowjobs and Repos
Prow users should create a PR creating tenantID defaults for their org/repos and clusters. Once you set up a tenantID, all prowjobs labelled with that tenantID will only be visible on Deck instances created with the same tenantID. If you already have prowjobs that you don’t want to lose access to on Deck, do this step last. If not, do it first to make sure prowjobs you want to keep sequestered do not appear on other instances of Deck.
The recommended way to add tenantIDs to prowjobs based on org/repo or cluster is through prowjob_default_entries in the prow config. This will apply the tenant ID to jobs with matching cluster AND repo. If you want to do cluster OR repo, create two entries in the config and use “*” for either field.
prowjob_default_entries:
- cluster: "build-private"
repo: "*"
config:
tenant_id: 'private'
- cluster: '*'
repo: 'private'
config:
tenant_id: 'private'
This configuration is used both to apply tenantIDs to prowjobs, but is also used by Deck to filter out Tide information from orgRepos with tenantIDs that do not match. So even if you can lable all your prowjobs using cluster, make sure that all of your repos are given a tenantID as well.
Once the PR is created, Prow operators should review the PR to make sure that no other tenantIDs were affected by the change.
Override TenantIDs
You can also define a tenantID for a given prowjob by defining it in the prowjob spec under spec.ProwJobDefault. This will override the tenantID assigned via prowjob defaults.
2) [Operator] Create a New Service Account and Bind it
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: default
name: <SA_NAME>
annotations:
"iam.gke.io/gcp-service-account": "..."
gcloud iam service-accounts add-iam-policy-binding \
--project=PROJECT \
--role=roles/iam.workloadIdentityUser \
--member=serviceAccount:K8S_PROJECT.svc.id.goog[SOMEWHERE/SOMETHING] \
SOMEBODY@PROJECT.iam.gserviceaccount.com
Once the service account is created, grant the service account Viewer access to the GCS bucket where test results are located.
3) [Operator] (Optional) Create a New OauthApp for Authentication
If you want to make the new Deck instance private, create a new oauth app using the Prowbot github account.
You can follow this Documentation to create the app:
Creating oauth Secrets
You will need to create two secrets populated with information from the oauth app
github-oauth-config:
data:
secret: {
"client_id":"...",
"client_secret":"...",
"redirect_url":"...",
"cookie_secret":"...",
"final_redirect_url":"...",
"scopes":[]
}
oauth-config
data:
clientID: ...
clientSecret: ...
cookieSecret: ...
For more information on how to make these secrets take a look at the Secrets Documentation
4 [User] Create the new Deck Deployment
When creating the new Deck Deployment, make sure to update the following fields:
-
Update Service Account on new Deployment
-
Update TenantID on new Deployment
- Add
- --tenant-id=NEW_IDunder args in the Deck deployment spec - You can add this flag multiple times to allow multiple tenantIDs
- Add
-
(Optional) Add a volume mount for the oauth app and update the oauth-config
- Here is an example of oauth2-proxy being used with github account validation. The oauth and oauth-config secrets are made in step 3.
volumeMounts: ... - name: oauth2-proxy image: quay.io/oauth2-proxy/oauth2-proxy ports: - containerPort: 4180 protocol: TCP args: - --provider=github - --github-org=ORG - --github-team=TEAM - --http-address=0.0.0.0:4180 - --upstream=http://localhost:8080 - --cookie-domain=DOMAIN - --cookie-name=COOKIE NAME (can be anything) - --cookie-samesite=none - --cookie-expire=23h - --email-domain=* livenessProbe: httpGet: path: /ping port: 4180 initialDelaySeconds: 3 periodSeconds: 3 readinessProbe: httpGet: path: /ping port: 4180 initialDelaySeconds: 3 periodSeconds: 3 env: - name: OAUTH2_PROXY_CLIENT_ID valueFrom: secretKeyRef: name: oauth key: clientID - name: OAUTH2_PROXY_CLIENT_SECRET valueFrom: secretKeyRef: name: oauth key: clientSecret - name: OAUTH2_PROXY_COOKIE_SECRET valueFrom: secretKeyRef: name: oauth key: cookieSecret - name: OAUTH2_PROXY_REDIRECT_URL value: https://prow.infra.cft.dev/oauth2/callbackvolumes: ... - name: oauth-config secret: secretName: oauth-config
Here is an example private deployment.
5 [Operator] Use the New Deployment
In order to use the new Deployment you will need to:
- Make a new static IP
- On GCP go to VPC Networks -> ExternalIP
- Click Reserve Static Address
- Set the Region to Global
- Create new Domain and configure DNS with new Static IP
- Make a new Ingress with the new Domain
- Create a new Managed Cert
- Add the new Rule
- Configure Ingress to use the managed cert
- Here is an example
6 [User] Update status check links
In the prow config, add the new domain to target_urls and job_url_prefix_config like so:
target_urls:
"*": https://oss-prow.knative.dev/tide
"privateOrg/repo": https://DOMAIN/tide
job_url_prefix_config:
"*": https://oss-prow.knative.dev/view/
"privateOrg/repo": https://DOMAIN/view/
7 [Operator] Ensure that the public deck service account does not have access to the bucket for the jobs you wish to remain private
20 - Spyglass
Spyglass
Spyglass is a pluggable artifact viewer framework for Prow. It collects artifacts (usually files in a storage bucket) from various sources and distributes them to registered viewers, which are responsible for consuming them and rendering a view.
A typical Spyglass page might look something like this:

If you want to know how to write a Spyglass lens, check the lens-writing guide. If you’re interested in how Spyglass works, check the architecture summary.
Configuration
Using Spyglass on your Prow instance requires you to first enable Spyglass in deck, and then
configure Spyglass to actually do something.
Enabling Spyglass
To enable spyglass, just pass the --spyglass flag to your deck instance. Once spyglass is enabled,
it will expose itself under /view/ on your deck instance.
In order to make Spyglass useful, you may want to set your job URLs to point at it. You can do so by
setting plank.job_url_prefix_config['*'] to https://your.deck/view/, and possibly plank.job_url_template
to reference something similar depending on your setup.
If you are not using the images we provide, you may also need to provide --spyglass-files-location,
pointing at the on-disk location of the lenses folder in this directory.
Configuring Spyglass
Spyglass configuration is contained in the spyglass subsection of the deck section of Prow’s
primary configuration.
The spyglass block has the following properties:
| Name | Required | Example | Description |
|---|---|---|---|
size_limit |
Yes | 100000000 |
The maximum size of an artifact to download, in bytes. Larger values will be omitted or truncated. |
gcs_browser_prefix |
No | https://gcsweb.k8s.io/gcs/ https://s3.console.aws.amazon.com/s3/buckets/ |
If you have a GCS browser available, the bucket and path to the artifact directory will be appended to gcs_browser_prefix and linked from Spyglass pages. If left unset, no artifacts link will be visible. The provided URL should have a trailing slash |
testgrid_config |
No | gs://k8s-testgrid/config |
If you have a TestGrid instance available, testgrid_config should point to the TestGrid config proto on GCS. If omitted, no TestGrid link will be visible. |
testgrid_root |
No | https://testgrid.k8s.io/ |
If you have a TestGrid instance available, testgrid_root should point to the root of the TestGrid web interface. If omitted, no TestGrid link will be visible. |
announcement |
No | "Remember: friendship is magic!" |
If announcement is set, the string will appear at the top of the page. announcement is parsed as a Go template. The only value provided is .ArtifactPath, which is of the form gcs-bucket/path/to/job/root/. |
lenses |
Yes | (see below) | lenses configures the lenses you want, when they should be visible, what artifacts they should receive, and any lens specific configuration |
Configuring Lenses
Lenses are the Spyglass components that actually display information. The lenses block under the
spyglass block is a list of configuration for each lens. Each lens entry has the following
properties:
| Name | Required | Example | Description |
|---|---|---|---|
required_files |
Yes | - build-log\.txt |
A list of regexes matching artifact names that must be present for a lens to appear. The list entries are ANDed together - that is, something much match every entry. OR can be simulated by using a pipe in a single regex entry. |
optional_files |
No | - something\.txt |
A list of regexes matching artifact names that will be provided to a lens if present, but are not necessary for it to appear (for that, use required_files). Since each entry in the list is optional, these are effectively ORed together. |
lens.name |
Yes | buildlog |
The name of the lens you want to render these files. Must be a known lens name. |
lens.config |
No | Lens-specific configuration. What can be included here, if anything, depends on the lens in question. |
The following lenses are available:
metadata: parses the metadata files generated by podutils and displays their content. It has no configuration.junit: parses junit files and displays their content. It has no configurationbuildlog: displays the build log (or any other log file), highlighting interesting parts and hiding the rest behind expandable folders. You can configure what it considers “interesting” by providinghighlight_regexes, a list of regexes to highlight. If not specified, it uses defaults optimised for highlighting Kubernetes test results. The optionalhide_raw_logboolean field can be used to omit the link to the rawbuild-log.txtsource.podinfo: displays info about ProwJob pods including the events and details about containers and volumes. Thegcsk8sreporterCrier reporter must be enabled to upload the requiredpodinfo.jsonfile.coverage: displays go coverage contentrestcoverage: displays REST API statistics
Example Configuration
deck:
spyglass:
size_limit: 100000000 # 100 MB
gcs_browser_prefix: https://gcsweb.k8s.io/gcs/
testgrid_config: gs://k8s-testgrid/config
testgrid_root: https://testgrid.k8s.io/
announcement: "The old job viewer has been deprecated."
lenses:
- lens:
name: metadata
required_files:
- ^(?:started|finished)\.json$
optional_files:
- ^(?:podinfo|prowjob)\.json$
- lens:
name: buildlog
config:
highlight_regexes:
- timed out
- 'ERROR:'
- (FAIL|Failure \[)\b
- panic\b
- ^E\d{4} \d\d:\d\d:\d\d\.\d\d\d]
required_files:
- ^build-log\.txt$
- lens:
name: junit
required_files:
- ^artifacts/junit.*\.xml$
- lens:
name: podinfo
config:
runner_configs: # Would only work if `prowjob.json` is configured below
"<BUILD_CLUSTER_ALIAS>":
pod_link_template: "https://<YOUR_CLOUD_PROVIDER_URL>/{{ .Name }}" # Name is directly from the Pod truct.
# Example:
# "default":
# pod_link_template: "https://console.cloud.google.com/kubernetes/pod/us-central1-f/prow/test-pods/{{ .Name }}/details?project=k8s-prow-builds"
required_files:
- ^podinfo\.json$
optional_files:
- ^prowjob\.json$ # Only if runner_configs is configured.
Accessing custom storage buckets
By default, spyglass has access to all storage buckets defined globally
(plank.default_decoration_config_entries[...].gcs_configuration) or on individual jobs (<path-to-job>.gcs_configuration.bucket).
In order to access additional/custom storage buckets, those buckets must be listed in deck.additional_storage_buckets.
20.1 - Spyglass Architecture
Spyglass is split into two major parts: the Spyglass core, and a set of independent lenses. Lenses are designed to run statelessly and without any knowledge of the world outside being provided with a list of artifacts. The core is responsible for selecting lenses and providing them with artifacts.
Spyglass Core
The Spyglass Core is split across prow/spyglass and prow/cmd/deck. It has
the following responsibilities:
- Looking up artifacts for a given job and mapping those to lenses
- Generating a page that loads the required lenses
- Framing lenses with their boilerplate
- Faciliating communication between the lens frontends and backends
Spyglass Lenses
Spyglass Lenses currently all live in prow/spyglass/lenses, though hopefully in the
future they can live elsewhere. Spyglass lenses have the following responsibilities:
- Fetching artifacts
- Rendering HTML for human consumption
Lens frontends are run in sandboxed iframes (currently sandbox="allow-scripts allow-top-navigation allow-popups allow-same-origin"), which ensures that they can only interact with the world via the
intended API. In particular, this prevents lenses from interacting with other Deck pseudo-APIs or with
the core spyglass page.
In order to provide this API to lenses, a library
(prow/cmd/deck/static/spyglass/lens.ts) is injected into
the lenses under the spyglass namespace. This library communicates with the spyglass core via
window.postMessage. The
spyglass core then takes the requested action on the lens’s behalf, which includes facilitating
communication between the lens frontend and backend. The messages exchanged between the core and the
lens are described in prow/cmd/deck/static/spyglass/common.ts.
The messages are exchanged over a simple JSON-encoded protocol where each message sent from the lens
has an ID number attached, and a response with the same ID number is expected to be received.
For the purposes of static typing, the lens library is ambiently declared in
spyglass/lenses/lens.d.ts, which just re-exports the definition of
spyglass from lens.ts.
This design is discussed in its implementation PR.
Lens endpoints
Lenses are exposed by the spyglass core on the following Deck endpoints:
| URL | Method | Purpose |
|---|---|---|
/spyglass/lens/:lens_name/iframe |
GET | The iframe view loaded directly by the spyglass core |
/spyglass/lens/:lens_name/rerender |
POST | Returns the lens body, used by calls to spyglass.updatePage and spyglass.requestPage |
/spyglass/lens/:lens_name/callback |
POST | Allows the lens frontend to exchange arbitrary strings with the lens backend. Used by spyglass.request() |
In all cases, the endpoint expects a JSON blob via the query parameter req that contains
bookkeeping information required by the spyglass core - the artifacts required, what job this is
about, a reference to the lens configuration. This information is attached to requests by the
spyglass core, and the lenses are not directly aware of it. In the case of the POSTed endpoints
/rerender and /callback, the lens can choose to attach an arbitrary string for its own use. This
string is passed through the core as an opaque string.
Some additional query parameters are attached to the iframes created by the spyglass core. These are not used by the backend, and are provided as a convenient means to synchronously provide information from the frontend core to the frontend lens library.
Page loading sequence
When a spyglass page is loaded, the following occurs:
- The core backend generates a list of artifacts for the job (e.g. by listing from GCS)
- The core backend matches the artifact list against the configured lenses and determines which ones to display.
- The core backend generates an HTML page with the lens->resource mapping embedded in it as JavaScript objects.
- The core frontend reads the embedded mapping and generates iframes for each lens
- The core receives the simultaneous requests to the lens endpoints and invokes the lenses to generate their content, injecting the lens library alongside some basic styling.
After this final step completes, the page is fully rendered. Lenses may choose to request additional information from their frontend, in which case the following happens:
- The lens frontend makes a request to the core frontend
- The core frontend attaches some lens-specific metadata and makes an HTTP request to the relevant lens endpoint
- The core backend receives the request and invokes the lens backend with the relevant information attached.
20.2 - Build a Spyglass Lens
Spyglass lenses consist of two components: a frontend (which may be trivial) and a backend.
Lens backend
Today, a lens backend must be linked in to the deck binary. As such, lenses must live under
prow/spyglass/lenses. Additionally lenses must be in a folder that matches the
name of the lens. The content of this folder will be served by deck, enabling you to reference
static content such as images, stylesheets, or scripts.
Inside your template you must implement the lenses.Lens interface.
An instance of the struct implementing the lenses.Lens interface must then be registered with
spyglass, by calling lenses.RegisterLens.
A minimal example of a lens called samplelens, located at lenses/samplelens, might look like this:
package samplelens
import (
"encoding/json"
"sigs.k8s.io/prow/pkg/config"
"sigs.k8s.io/prow/pkg/spyglass/lenses"
)
type Lens struct{}
func init() {
lenses.RegisterLens(Lens{})
}
// Config returns the lens's configuration.
func (lens Lens) Config() lenses.LensConfig {
return lenses.LensConfig{
Title: "Human Readable Lens",
Name: "samplelens", // remember: this *must* match the location of the lens (and thus package name)
Priority: 0,
}
}
// Header returns the content of <head>
func (lens Lens) Header(artifacts []lenses.Artifact, resourceDir string, config json.RawMessage, spyglassConfig config.Spyglass) string {
return ""
}
func (lens Lens) Callback(artifacts []lenses.Artifact, resourceDir string, data string, config json.RawMessage, spyglassConfig config.Spyglass) string {
return ""
}
// Body returns the displayed HTML for the <body>
func (lens Lens) Body(artifacts []lenses.Artifact, resourceDir string, data string, config json.RawMessage, spyglassConfig config.Spyglass) string {
return "Hi! I'm a lens!"
}
If you want to read resources included in your lens (such as templates), you can find them in the
provided resourceDir.
Finally, you will need to import your lens from deck in order to actually link it in. You can do
this by importing it from prow/cmd/deck/main.go, alongside the other lenses:
import (
// ...
_ "sigs.k8s.io/prow/pkg/spyglass/lenses/samplelens"
)
Finally, you can then test it by running ./cmd/deck/runlocal and loading a spyglass page.
Lens frontend
The HTML generated by a lens can reference static assets that will be served by Deck on behalf of
your lens. Scripts and stylesheets can be referenced in the output of the Header() function (which
is inserted into the <head> element). Relative references into your directory will work: spyglass
adds a <base> tag that references the expected output directory.
Spyglass lenses have access to a spyglass global that provides a number of APIs to interact with
your lens backend and the rest of the world. Your lens is rendered in a sandboxed iframe, so you
generally cannot interact without using these APIs.
We recommend writing lenses using TypeScript, and provide TypeScript declarations for the spyglass
APIs.
In order to build frontend resources in, you will need to notify the build system. Assuming you had
a template called template.html, a typescript file called sample.ts, a stylesheet called
style.css, and an image called magic.png. The changes are:
- Add a new file called
tsconfig.json:
{
"extends": "../../../../tsconfig.json",
"include": [
"sample.ts",
],
}
- Add a line in prow/cmd/deck/.ts-packages:
prow/spyglass/lenses/sample/sample.ts->script_bundle.min.js
With this setup, you would reference your script in your HTML as script_bundle.min.js, like so:
<script type="text/javascript" src="script_bundle.min.js"></script>
Lens APIs
Many Spyglass APIs are asynchronous, and so return a
Promise. We
recommend using async/await to use them, like this:
async function doStuff(): Promise<void> {
const someStuff = await spyglass.request("");
}
We provide the following methods under spyglass in all lenses:
spyglass.contentUpdated(): void
contentUpdated should be called whenever you make changes to the content of the page. It signals
to the Spyglass host page that it needs to recalculate how your lens is displayed. It is not
necessary to call it on initial page load.
spyglass.request(data: string): Promise<string>
request is used to call back to your lens’s backend. Whatever data you provide will be provided
unmodified to your lens backend’s Callback() method. request returns a Promise, which will
eventually be resolved with the string returned from Callback() (unless an error occurs, in which
case it will fail). We recommend, but do not require, that both strings be JSON-encoded.
spyglass.updatePage(data: string): Promise<void>
updatePage calls your lens backend’s Body() method again, passing in whatever data you
provide and shows a loading spinner. Once the call completes, the lens is re-displayed using the
newly-provided <body>. Note that this does not reload the lens, and so your script will keep
running. The returned promise resolves once the new content is ready.
spyglass.requestPage(data: string): Promise<string>
requestPage calls your lens backend’s Body() method again, passing in whatever data you
provide. Unlike updatePage, it does not show a spinner, and does not change the page. Instead,
the returned promise will resolve with the newly-generated HTML.
spyglass.makeFragmentLink(fragment: string): string
makeFragmentLink returns a link to the top-level page that will cause your lens to receive the
specified fragment in location.hash, and no other lens on the page to receive any fragment.
This is useful when generating links for the user to copy to your content, but should not be used
to perform direct navigation - instead, just update location.hash, and propagation will be
handled transparently.
If the provided fragment does not have a leading # one will be added, for consistency with the
behaviour of location.hash.
spyglass.scrollTo(x: number, y: number): Promise<void>
scrollTo scrolls the parent Spyglass page such that the provided (x, y) document-relative
coordinate of your lens is visible. Note that we keep lenses at slightly under 100% page width, so
only y is currently meaningful.
Special considerations
Sandboxing
Lenses are contained in sandboxed iframes in the parent page. The most notably restricted activity is making XHR requests to Deck, which would be considered prohibited CORS requests. Lenses also cannot directly interact with their parent window, outside of the provided APIs.
Links
We set a default <base> with href set pointing in to your resource directory, and target set
to _top. This means that links will by default replace the entire spyglass page, which is usually
the intended effect. It also means that src or href HTML attributes are based in those
directories, which is usually what you want in this context.
Fragments / Anchor links
Fragment URLs (the part after the #) are supported fairly transparently, despite being in an iframe.
The parent page muxes all the lens’s fragments and ensures that if the page is loaded, each lens
receives the fragment it expects. Changing your fragment will automatically update the parent page’s
fragment. If the fragment matches the ID or name of an element, the page will scroll such that that
element is visible.
Anchor links (<a href="#something">) would usually not work well in conjunction with the <base>
tag. To resolve this, we rewrite all links of this form to behave as expected both on page load and
on DOM modification. In most cases, this should be transparent. If you want users to copy links via
right click -> copy link, however, this will not work nicely. Instead, consider setting the href
attribute to something from spyglass.makeFragmentLink, but handling clicks by manually setting
location.hash to the desired fragment.
20.3 - REST API coverage lens
Presents REST endpoints statistics
Configuration
threshold_warningset threshold for warning highlightthreshold_errorset threshold for error highlight
Expected input
uniqueHitstotal number of unique params calls (first hit of any leaf should increase this value)expectedUniqueHitstotal number of params (leaves)percentisuniqueHits* 100 /expectedUniqueHitsmethodCalledwhether the method was calledbodybody paramsqueryquery paramsrootroot of the treehitsnumber of all params hitsitemscollection of nodes, if not present then the node is a leafheightheight of the treesizesize of the tree
{
"uniqueHits": 2,
"expectedUniqueHits": 4,
"percent": 50.00,
"endpoints": {
"/pets": {
"post": {
"uniqueHits": 2,
"expectedUniqueHits": 4,
"percent": 50.00,
"methodCalled": true,
"params": {
"body": {
"uniqueHits": 2,
"expectedUniqueHits": 4,
"percent": 50.00,
"root": {
"hits": 15,
"items": {
"origin": {
"hits": 8,
"items": {
"country": {
"hits": 8,
"items": {
"name": {
"hits": 8
},
"region": {
"hits": 0
}
}
}
}
},
"color": {
"hits": 0
},
"type": {
"hits": 7
}
}
},
"height": 4,
"size": 7
}
}
}
}
}
}
21 - Using Prow at Scale
If you are maintaining a Prow instance that will need to scale to handle a large load, consider using the following best practices, features, and additional tools. You may also be interested in “Getting more out of Prow”.
Features and Tools
Separate Build Cluster(s)
It is frequently not secure to run all ProwJobs in the same cluster that runs
Prow’s service components (hook, plank, etc.). In particular, ProwJobs that
execute presubmit tests for OSS projects should typically be isolated from
Prow’s microservices. This isolation prevents a malicious PR author from
modifying the presubmit test to do something evil like breaking out of the
container and stealing secrets that live in the cluster or DOSing a
cluster-internal Prow component service.
Any number of build clusters can be used in order to isolate specific jobs from each other, improve scalability, or allow tenants to provide and manage their own execution environments. Instructions for configuring jobs to run in different clusters can be found here.
Production Prow instances should run most ProwJobs in a build cluster separate from the Prow service cluster (the cluster where the Prow components live). Any ‘trusted’ jobs that require secrets or services that should not be exposed to presubmit jobs, such as publishing or deployment jobs, should run in a different cluster from the rest of the ‘untrusted’ jobs. It is common for the Prow service cluster to be reused as a build cluster for these ‘trusted’ jobs since they are typically fast and few in number so running and managing an additional build cluster would be wasteful.
Pull Request Merge Automation
Pull Requests can be automatically merged when they satisfy configured merge
requirements using tide. Automating merge is critical for
large projects where allowing human to click the merge button is either a bottle
neck, a security concern, or both. Tide ensures that PRs have been tested
against the most recent base branch commit before merging (retesting if
necessary), and automatically groups multiple PRs to be tested and merged as a
batch whenever possible.
Config File Split
If your Prow config starts to grow too large, consider splitting the job config
files into more specific and easily reviewed files. This is particularly useful
for delegating ownership of ProwJob config to different users or groups via the
use of OWNERS files with the approve plugin and
Tide. It is common to enforce custom config policies for
jobs defined in certain files or directories via presubmit unit tests. This
makes it safe for Prow admins to delegate job config ownership by enforcing
limitations on what can be configured and by whom. For example, we use a golang
unit test in a presubmit job to validate that all jobs that are configured to
run in the test-infra-trusted build cluster are defined in a file controlled
by test-infra oncall.
(examples)
To use this pattern simply aggregate all job configs in a directory of files
with unique base names and supply the directory path to components via
--job-config-path. The updateconfig plugin and
config-bootstrapper support this pattern by
allowing multiple files to be loaded into a single configmap under different
keys (different files once mounted to a container).
GitHub API Cache
ghproxy is a reverse proxy HTTP cache optimized for the GitHub API.
It takes advantage of how GitHub responds to E-tags in order to fulfill repeated
requests without spending additional API tokens. Check out this tool if you find
that your GitHub bot is consuming or approaching its token limit. Similarly,
re-deploying Prow components may trigger a large amount of API requests to GitHub
which may trip the abuse detection mechanisms. At scale, the tide deployment
itself may create enough API throughput to trigger this on its own. Deploying the
GitHub proxy cache is critical to ensuring that Prow does not trip this mechanism
when operating at scale.
Config Driven GitHub Org Management
Managing org and repo scoped settings across multiple orgs and repos is not easy with the mechanisms that GitHub provides. Only a few people have access to the settings, they must be manually synced between repos, and they can easily become inconsistent. These problems grow with number of orgs/repos and with the number of contributors. We have a few tools that automate this kind of administration and integrate well with Prow:
label_syncis a tool that synchronizes labels and their metadata across multiple orgs and repos in order to provide a consistent user experience in a multi-repo project.branchprotectoris a Prow component that synchronizes GitHub branch requirements and restrictions based on config.peribolosis a tool that synchronizes org settings, teams, and memberships based on config.
Metrics
Prow exposes some Prometheus metrics that can be used to generate graphs and alerts. If you are maintaining a Prow instance that handles important workloads you should consider using these metrics for monitoring.
Best Practices
Don’t share Prow’s GitHub bot token with other automation.
Some parts of Prow do not behave well if the GitHub bot token’s rate limit is exhausted. It is imperative to avoid this so it is a good practice to avoid using the bot token that Prow uses for any other purposes.
Working around GitHub’s limited ACLs.
GitHub provides an extremely limited access control system that makes it impossible to control granular permissions like authority to add and remove specific labels from PRs and issues. Instead, write access to the entire repo must be granted. This problem grows as projects scale and granular permissions become more important.
Much of the GitHub automation that Prow provides is designed to fill in the gaps in GitHub’s permission system. The core idea is to limit repo write access to the Prow bot (and a minimal number of repo admins) and then let Prow determine if users have the appropriate permissions before taking action on their behalf. The following is an overview of some of the automation Prow implements to work around GitHub’s limited permission system:
- Permission to trigger presubmit tests is determined based on org membership
as configured in the
triggersplugin config section. - File ownership is described with OWNERS files and change approval is
enforced with the
approveplugin. See the docs for details. - Org member review of the most recent version of the PR is enforced with the
lgtmplugin. - Various other plugins manage labels, milestone, and issue state based on
/foostyle commands from authorized users. Authorization may be based on org membership, GitHub team membership, or OWNERS file membership. Tideprovides PR merge automation so that humans do not need to (and are not allowed to) merge PRs. Without Tide, a user either has no permission to merge or they have repo write access which grants permission to merge any PR in the entire repo. Additionally, Tide enforces merge requirements like required and forbidden labels that humans may not respect if they are allowed to manually click the merge button.
22 - Understanding Started.json and Finished.json
Context
Prow uploads a host of artifacts throughout the life cycle of a job. Two of these artifacts that are present in each run are started.json and finished.json which contain a host of information pertaining to the job/run. These files have existed through the evolution of Kubernetes CI: from Jenkins -> Containerized Jenkins -> Bootstrap Containerized Jenkins -> Bootstrap Prow -> PodUtils. As of 2021, all jobs exist within either Bootstrap Prow or PodUtils. As the CI has evolved, so has started/finished.json and it’s function.
Examples: started.json finished.json
Related Issues:
- #3412: What is the origin and purpose for the fields in these files?
- #11100: This isn’t a source of truth and prow/pod/gcs are not in sync
- #10699: Unify *.json structures, was partially covered as part of #10703
Format Source of Truth
There has not been a consistent source of truth for the format of these two files, which has caused issues. From discussion in the community it seems that the the TestGrid job definition.
Current Standards
There are currently different flavors of data format depending on if the job is Bootstrap or PodUtils. Ex of differences:
Bootstrapped PR (finished): "revision": "v1.20.0-alpha.0.261+06ea384605f172"
Decorated PR (finished): "revision":"5dd9241d43f256984358354d1fec468f274f9ac4"
| Fields | Content |
|---|---|
| node | This is the first element in the hostname using socket.gethostname split by ‘.’ |
| pull | The SHA linked with the ‘main’ repo within ‘repos’ |
| repo-version | “unknown” if no ‘repos’ otherwise read from local ‘version’ file (e2e tests use this path) otherwise execute version script if ‘hack/lib/version.sh exists |
| timestamp | epoch time |
| repos | comes from –repos= arg |
| version | exact same as repo-version |
| Ex |
{
"node": "0790211c-cacb-11ea-a4b9-4a19d9b965b2",
"pull": "master:5a529aa3a0dd3a050c5302329681e871ef6c162e,93063:c25e430df7771a96c9a004d8500473a4f2ef55d3",
"repo-version": "v1.20.0-alpha.0.261+06ea384605f172",
"timestamp": 1595278460,
"repos": {
"k8s.io/kubernetes": "master:5a529aa3a0dd3a050c5302329681e871ef6c162e,93063:c25e430df7771a96c9a004d8500473a4f2ef55d3",
"k8s.io/release": "master"
},
"version": "v1.20.0-alpha.0.261+06ea384605f172"
}
| Fields | Content |
|---|---|
| timestamp | epoch |
| passed | bool (job success) |
| version | If version is in metadata, set from metadata same as job-version |
| result | ‘SUCCESS’ or “FAILURE’ depending on passed |
| job-version (dep) | If not existing and not ‘unknown’… from metadata, try ‘job-version’ then ‘version’ |
| metadata | exact same as repo-version |
| metadata.repo-commit | Git rev-parse HEAD (for k8s) |
| metadata.repos | Same as started ‘comes from –repo= args’ |
| metadata.infra-commit | Git rev-parse HEAD (for test-infra) |
| metadata.repo | main repo for job |
| metadata.job-version | Same as job version from above |
| metadata.revision | Same as job-version |
| Ex |
{
"timestamp": 1596732481,
"version": "v1.20.0-alpha.0.519+e825f0a86103a6",
"result": "SUCCESS",
"passed": true,
"job-version": "v1.20.0-alpha.0.519+e825f0a86103a6",
"metadata": {
"repo-commit": "e825f0a86103a6de00ebd20e158274c4fa625a34",
"repos": {
"k8s.io/kubernetes": "master:382107e6c84374b229e6188207ef026621286aa2,93714:19ff4d5a9a9b2df60019854f119e269ee035bbee"
},
"infra-commit": "1b7fbb373",
"repo": "k8s.io/kubernetes",
"job-version": "v1.20.0-alpha.0.519+e825f0a86103a6",
"revision": "v1.20.0-alpha.0.519+e825f0a86103a6"
}
}
| Fields | Content |
|---|---|
| timestamp | epoch |
| repo-version (dep) prob should use repo-commit | If refs in job, get SHA for ref else use downward api to get main SHA |
| job-version (dep) | Never set |
| pull | Pr number primary is testing, first pull in Spec Pull list |
| repo-commit | unset (but shouldn’t be) |
| repos | For Ref, ExtraRef add Org/Repo: Ref |
| node | unset |
| metadata | misc |
| Ex |
{
"timestamp": 1595277241,
"pull": "93264",
"repos": {
"kubernetes/kubernetes": "master:5feab0aa1e592ab413b461bc3ad08a6b74a427b4,93264:5dd9241d43f256984358354d1fec468f274f9ac4"
},
"metadata": {
"links": {
"resultstore": {
"url": "https://source.cloud.google.com/results/invocations/20688dbb-eb32-47e6-8a49-34734e714f81/targets/test"
}
},
"resultstore": "https://source.cloud.google.com/results/invocations/20688dbb-eb32-47e6-8a49-34734e714f81/targets/test"
},
"repo-version": "30f64c5b1fc57a3beb1476f9beb29280166954d1",
"Pending": false
}
| Fields | Content |
|---|---|
| timestamp | epoch |
| passed | bool |
| result | SUCCESS, ABORTED, FAILURE |
| repo-version (dep) | unset |
| job-version (dep) | unset |
| revision (dep) | SHA from Refs |
| metadata | unset |
| Ex |
{
"timestamp": 1595279434,
"passed": true,
"result": "SUCCESS",
"revision": "5dd9241d43f256984358354d1fec468f274f9ac4"
}
23 - Testing Prow
23.1 - Run Prow integration tests
Run all integration tests
./test/integration/integration-test.sh
Run a specific integration test
./test/integration/integration-test.sh -run=TestIWantToRun
Cleanup
./test/integration/teardown.sh -all
Adding new integration tests
New component
Assume we want to add most-awesome-component (source code in cmd/most-awesome-component).
-
Add
most-awesome-componentto thePROW_COMPONENTS,PROW_IMAGES, andPROW_IMAGES_TO_COMPONENTSvariables in lib.sh.- Add the line
most-awesome-componenttoPROW_COMPONENTS. - Add the line
[most-awesome-component]=cmd/most-awesome-componenttoPROW_IMAGES. - Add the line
[most-awesome-component]=most-awesome-componenttoPROW_IMAGES_TO_COMPONENTS. - Explanation:
PROW_COMPONENTSlists which components are deployed into the cluster,PROW_IMAGESdescribes where the source code is located for each component (in order to build them), and finallyPROW_IMAGES_TO_COMPONENTSdefines the relationship between the first two variables (so that the test framework knows what to redeploy depending on what image has changed). As an example, thedeckanddeck-tenantedcomponents (inPROW_COMPONENTS) both use thedeckimage (defined inPROW_IMAGES_TO_COMPONENTS), so they are both redeployed every time you change something incmd/deck(defined inPROW_IMAGES).
- Add the line
-
Set up Kubernetes Deployment and Service configurations inside the [configuration folder][config/prow/cluster] for your new component. This way the test cluster will pick it up when it deploys Prow components.
-
If you want to deploy an existing Prow component used in production (i.e., https://prow.k8s.io), you can reuse (symlink) the configurations used in production. See the examples in [configuration folder][config/prow/cluster].
-
Remember to use
localhost:5001/most-awesome-componentfor theimage: ...field in the Kubernetes configurations to make the test cluster use the freshly-built image.
-
New tests
Tests are written under the test directory. They are named with the
pattern <COMPONENT>_test.go*. Continuing the example above, you would add new
tests in most-awesome-component_test.go
Check that your new test is working
- Add or edit new tests (e.g.,
func TestMostAwesomeComponent(t *testing.T) {...}) inmost-awesome-component_test.go. - Run
./test/integration/integration-test.sh -run=TestMostAwesomeComponentto bring up the test cluster and to only test your new test namedTestMostAwesomeComponent. - If you need to make changes to
most-awesome-component_test.go(and not the component itself), run./test/integration/integration-test.sh -run=TestMostAwesomeComponent -no-setup. The-no-setupwill ensure that the test framework avoid redeploying the test cluster.- If you do need to make changes to the Prow component, run
./test/integration/integration-test.sh -run=TestMostAwesomeComponent -build=most-awesome-componentso thatcmd/most-awesome-componentis recompiled and redeployed into the cluster before runningTestMostAwesomeComponent.
- If you do need to make changes to the Prow component, run
If Step 2 succeeds and there is nothing more to do, you’re done! If not (and your tests still need some tweaking), repeat steps 1 and 3 as needed.
How it works
In short, the integration-test.sh script creates a KIND Kubernetes cluster, runs all available integration tests, and finally deletes the cluster.
Recall that Prow is a collection of services (Prow components) that can be deployed into a Kubernetes cluster. KIND provides an environment where we can deploy certain Prow components, and then from the integration tests we can create a Kubernetes Client to talk to this deployment of Prow.
Note that the integration tests do not test all components (we need to fix this). The PROW_COMPONENTS variable is a list of components currently tested. These components are compiled and deployed into the test cluster on every invocation of integration-test.sh.
Each tested component needs a Kubernetes configuration so that KIND understands
how to deploy it into the cluster, but that’s about it (more on this below). The
main thing to keep in mind is that the integration tests must be hermetic and
reproducible. For this reason, all components that are tested must be configured
so that they do not attempt to reach endpoints that are outside of the cluster.
For example, this is why some Prow components have a -github-endpoint=... flag
that you can use — this way these components can be instructed to talk to the
fakeghserver deployed inside the cluster instead of trying to talk to GitHub.
Code layout
.
├── cmd # Binaries for fake services deployed into the test cluster along with actual Prow components.
│ ├── fakegerritserver # Fake Gerrit.
│ ├── fakeghserver # Fake GitHub.
│ └── fakegitserver # Fake low-level Git server. Can theoretically act as the backend for fakeghserver or fakegerritserver.
├── config # Kubernetes configuration files.
│ └── prow # Prow configuration for the test cluster.
│ ├── cluster # KIND test cluster configurations.
│ └── jobs # Static Prow jobs. Some tests use these definitions to run Prow jobs inside the test cluster.
├── internal
│ └── fakegitserver
└── test # The actual integration tests to run.
└── testdata # Test data.
23.1.1 - Fake Git Server (FGS)
FGS is actually not a fake at all. It is a real web server that serves real Git
repositories them over HTTP. FGS wraps around the vanilla git http-backend
subcommand that comes with Git, calling it as a CGI executable. It supports both
read (e.g., git clone, git fetch) and write (e.g., git push) operations
against it.
FGS is used for integration tests. See TestClonerefs for an example.
Usage in Integration Testing
The fakegitserver.go file is built automatically by hack/prowimagebuilder,
and we deploy it to the KIND cluster. Inside the cluster, it accepts web traffic
at the endpoint http://fakegitserver.default (http://localhost/fakegitserver
from outside of the KIND cluster).
There are 2 routes:
/repo/<REPO_NAME>: endpoint for Git clients to interact (git clone,git fetch,git push). E.g.,git clone http://fakegitserver.default/repo/foo. Internally, FGS serves all Git repo folders under-git-repos-parent-diron disk and serves them for the/reporoute with thegit-http-backendCGI script.- POST
/setup-repo: endpoint for creating new Git repos on the server; you just need to send a JSON payload like this:
{
"name": "foo",
"overwrite": true,
"script": "echo hello world > README; git add README; git commit -m update"
}
Here is a cURL example:
# mkFoo is a plaintext file containing the JSON from above.
$ curl http://localhost/fakegitserver/setup-repo -d @mkFoo
commit c1e4e5bb8ba0e5b16147450a75347a27e5980222
Author: abc <d@e.f>
Date: Thu May 19 12:34:56 2022 +0000
update
Notice how the server responds with a git log output of the just-created repo
to ease debugging in case repos are not created the way you expect them to be
created.
During integration tests, each test creates repo(s) using the /setup-repo
endpoint as above. Care must be taken to not reuse the same repository name, as
the test cases (e.g., the test cases in TestClonerefs) all run in parallel and
can clobber each other’s repo creation setp.
Allowing Push Access
Although this is not (yet) used in tests, push access is enabled for all served
repos. This is achieved by setting the http.receivepack Git configuration
option to true for each repo found under -git-repos-parent-dir. This is
because the git http-backend script does not by default allow anonymous push
access unless the aforementioned option is set to true on a per-repo basis.
Allowing Fetching of Commit SHAs
By default the CGI script will only serve references that are “advertised” (such
as those references under refs/heads/* or refs/pull/*/head). However, FGS
also sets the uploadpack.allowAnySHA1InWant option to true to allow Git
clients (such as clonerefs) to fetch commits by their SHA.
Local Usage (for debugging)
FGS has 2 requirements:
- the path to the local
gitbinary installation, and - the path to a folder containing Git repositories to be served (can be an empty directory, or pre-populated).
By default port 8888 is used, although this can also be configured with -port.
Example:
$ go run fakegitserver.go -h
Usage of /tmp/go-build2317700172/b001/exe/fakegitserver:
-git-binary git
Path to the git binary. (default "/usr/bin/git")
-git-repos-parent-dir string
Path to the parent folder containing all Git repos to serve over HTTP. (default "/git-repo")
-port int
Port to listen on. (default 8888)
$ go run fakegitserver.go -git-repos-parent-dir <PATH_TO_REPOS> -git-binary <PATH_TO_GIT>
{"component":"unset","file":"/home/someuser/go/src/sigs.k8s.io/prow/pkg/test/integration/fakegitserver/fakegitserver.go:111","func":"main.main","level":"info","msg":"Start server","severity":"info","time":"2022-05-22T20:31:38-07:00"}
In this example, http://localhost:8888 is the HTTP address of FGS:
# Clone "foo" repo, assuming it exists locally under `-git-repos-parent-dir`.
$ git clone http://localhost:8888/repo/foo
$ cd foo
$ git log # or any other arbitrary Git command
# ... do some Git operations
$ git push
That’s it!
Local Usage with Docker and Ko (for debugging)
It may be helpful to run FGS in a containerized environment for debugging. First
install ko itself. Then
cd to the fakegitserver folder (same folder as this README.md file), and
run:
# First CD to the root of the repo, because the .ko.yaml configuration (unfortunately)
# depends on relative paths that can only work from the root of the repo.
$ cd ${PATH_TO_REPO_ROOT}
$ docker run -it --entrypoint=sh -p 8123:8888 $(ko build --local sigs.k8s.io/prow/pkg/test/integration/fakegitserver)
The -p 8123:8888 allows you to talk to the containerized instance of
fakegitserver over port 8123 on the host.
Custom Base Image
To use a custom base image for FGS, change the baseImageOverrides entry for
fakegitserver in .ko.yaml like this:
baseImageOverrides:
# ... other entries ...
sigs.k8s.io/prow/pkg/test/integration/fakegitserver: gcr.io/my/base/image:tag
If you want ko to pick up a local Docker image on your machine, rename the
image to have a ko.local prefix. For example, like this:
baseImageOverrides:
sigs.k8s.io/prow/pkg/test/integration/fakegitserver: ko.local/my/base/image:tag
24 - Legacy Snapshot
Legacy Snapshot
Historically, almost all of Prow’s documentation resided in the kubernetes/test-infra (“k/t-i”) repo. As part of the migration effort, those docs were replaced with “tombstones” in https://github.com/kubernetes/test-infra/pull/27818, with a pointer to this page.
This page captures Prow documentation in the k/t-i repository as of October 25, 2022. All Markdown files have been copied in along with their directory structure here.
How you can help
The files in this snapshot should probably be reorganized around logical delineations, and not the (inherited) filesystem delineations from k/t-i. This is an ongoing effort and the goal is to one day delete this snapshot altogether (to be replaced by equivalent documentation outside of this folder).